【 TiDB 使用环境】
v4.0.11
【概述】场景+问题概述
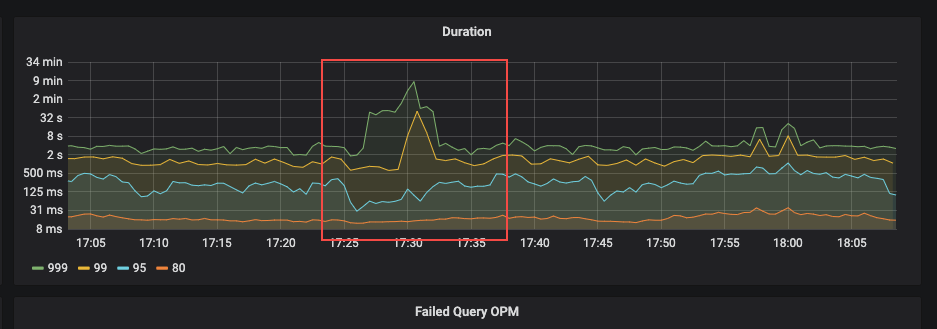
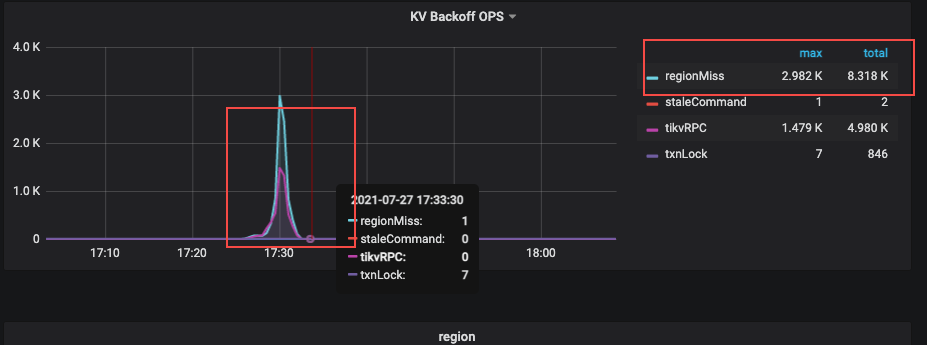
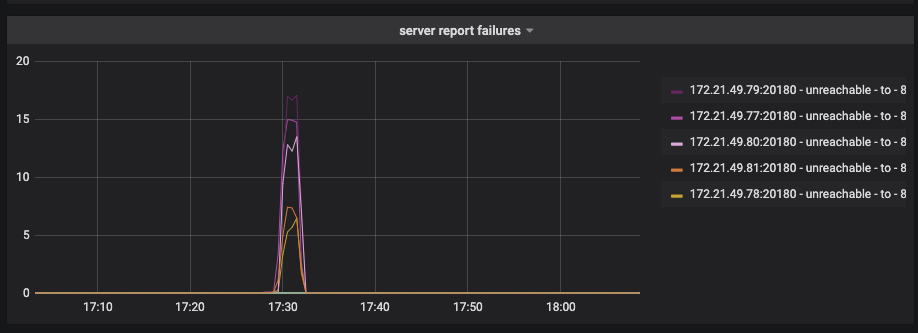
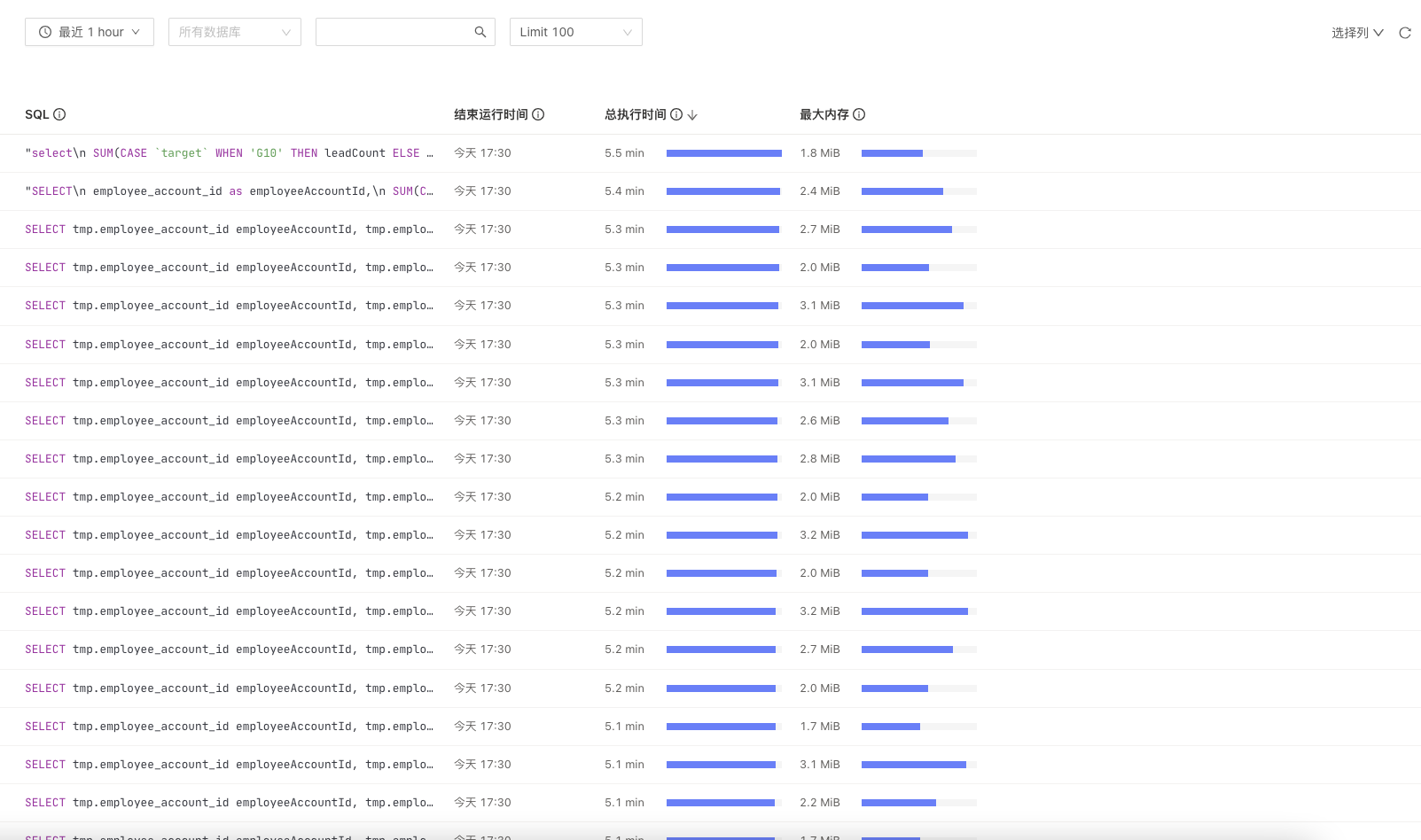
线上业务运行,17:30业务大量超时 看监控发现该时间段SQL延迟增长,监控regionmiss和grpc监控报错
【背景】做过哪些操作
无任何操作
【业务影响】
改时间段业务超时,过后恢复
大概的问题方向请问怎么怎么排查?
【 TiDB 使用环境】
v4.0.11
【概述】场景+问题概述
线上业务运行,17:30业务大量超时 看监控发现该时间段SQL延迟增长,监控regionmiss和grpc监控报错
【背景】做过哪些操作
无任何操作
【业务影响】
改时间段业务超时,过后恢复
大概的问题方向请问怎么怎么排查?
问题时间端 tikv 可能存在一些性能瓶颈,可以通过监控排查下相关 metric 慢在哪里
https://docs.pingcap.com/zh/tidb/v5.0/tidb-troubleshooting-map#45-tikv-写入慢
大佬请教下,regionmiss的确切含义或场景是什么? 和notleader错误有什么关系?
region miss 表示访问的 region 在当前 kv 没有找到,可能从当前 store 迁走了;not leader 是请求的 kv 上的 peer 不是 leader 并返回新 leader 的信息或 leader 暂时缺失,这类访问 kv 失败的报错返回给 tidb 后,tidb 发起 backoff 重试,如果多次重试超过最大重试时间,会将报错返回给客户端。
感谢大佬,“region miss 表示访问的 region 在当前 kv 没有找到,可能从当前 store 迁走了;” 这里的访问应该都是指的访问leader吧,对于tidb来讲,如果访问一个kv的region时,该region leader已经迁移到其他tikv,那么tikv 返回not leader错误的同时,tidb的region miss统计是不是也会相应增加。 另外tidb的region cache是如何管理的,除了由于notleader等错误进行清理和替换外有没有类似LRU的机制管理region cache.
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。