abcd
(Abcd)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】 场景 + 问题概述
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
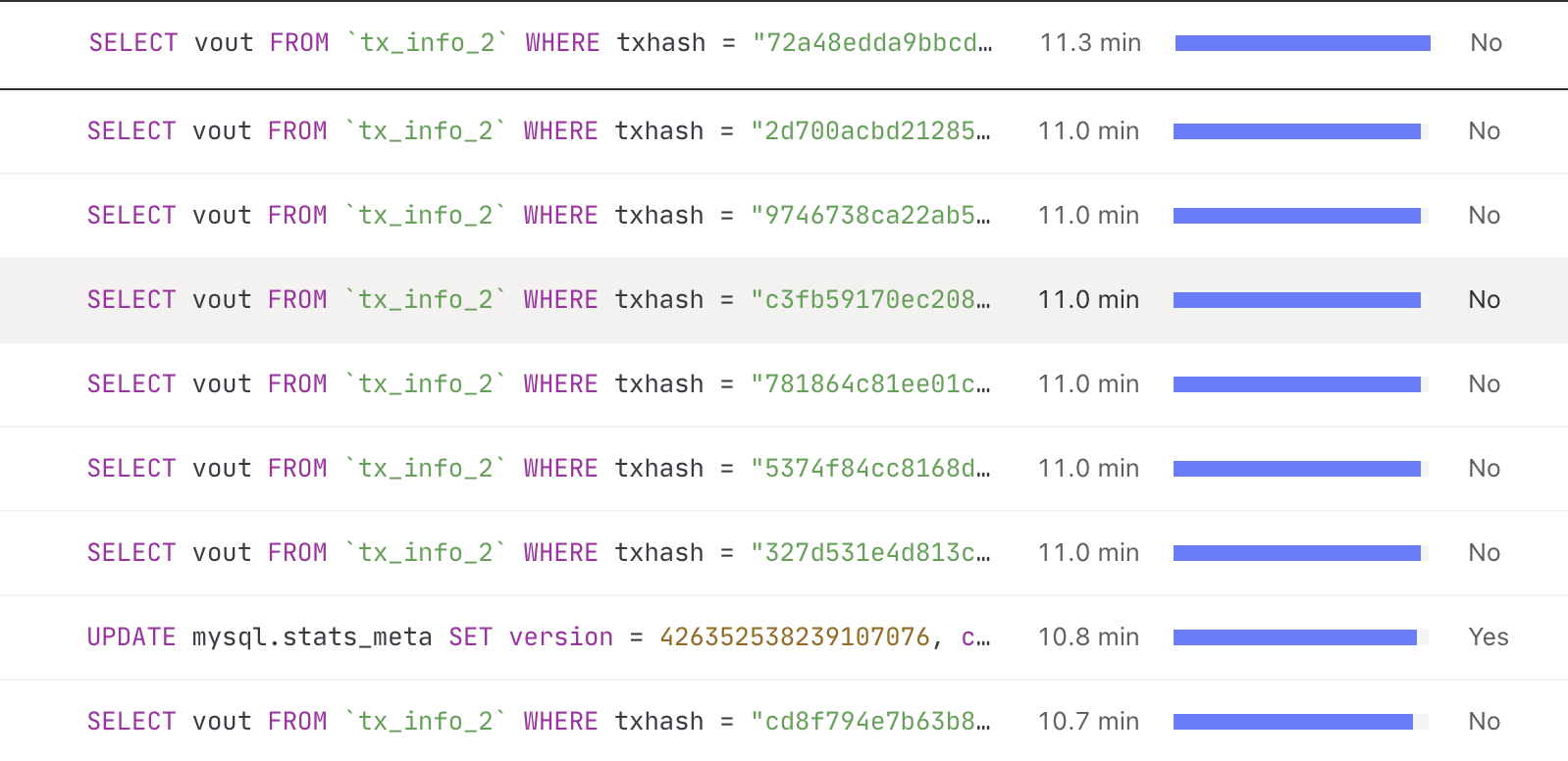
一些简单的索引点查耗时10分钟,且执行失败
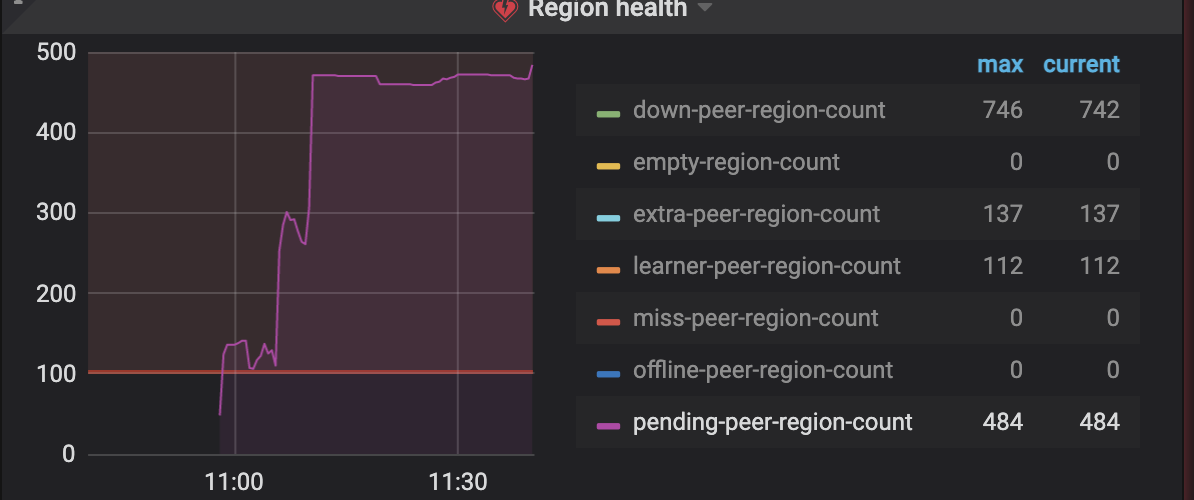
以下是监控面板tikv-details信息,可以看到只有两个节点有io,其他几乎为0。
test-cluster-TiKV-Details_2021-07-16T04_29_23.931Z.json.zip
以下为日志
链接: 百度网盘-链接不存在 密码: ndwf
具体现象大致如下
烦请加急处理,谢谢。
【业务影响】
大量查询阻塞报错
【TiDB 版本】
4.0.13
1 个赞
abcd
(Abcd)
3
已经按照给出的意见将kv更换为了ssd,每个kv配置完全相同,空region也merge了,但该现象依然存在。
xfworld
(魔幻之翼)
4
SQL 执行慢的话,原因很多,你试下:
explain SQL 和 explain analyze SQL
一个是预计执行的结果
一个是实际执行的结果
看看有没有帮助~
abcd
(Abcd)
8
您好,请问一下是否可以设置一个超时时间,如果一次select请求超过一定时间后直接返回失败,我们的应用需要批量查询数据库,这样每个失败等待10分钟十分影响性能
xfworld
(魔幻之翼)
9
这个操作不是太好,最好通过explain 直接优化SQL,减少出现慢SQL 的问题
如果非要用,请注意设置的要求,你参考下:
max_execution_time
- 作用域:SESSION | GLOBAL
- 默认值:
0
- 范围:
[0, 2147483647]
- 单位:毫秒
- 语句最长执行时间。默认值 (0) 表示无限制。
注意:
max_execution_time 目前对所有类型的语句生效,并非只对 SELECT 语句生效,与 MySQL 不同(只对 SELECT 语句生效)。实际精度在 100ms 级别,而非更准确的毫秒级别。
https://docs.pingcap.com/zh/tidb/stable/system-variables#max_execution_time
abcd
(Abcd)
11
出现问题的都是最简单的点查询,不知该如何进行sql语句的优化
system
(system)
关闭
12
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。