abcd
(Abcd)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】场景+问题概述
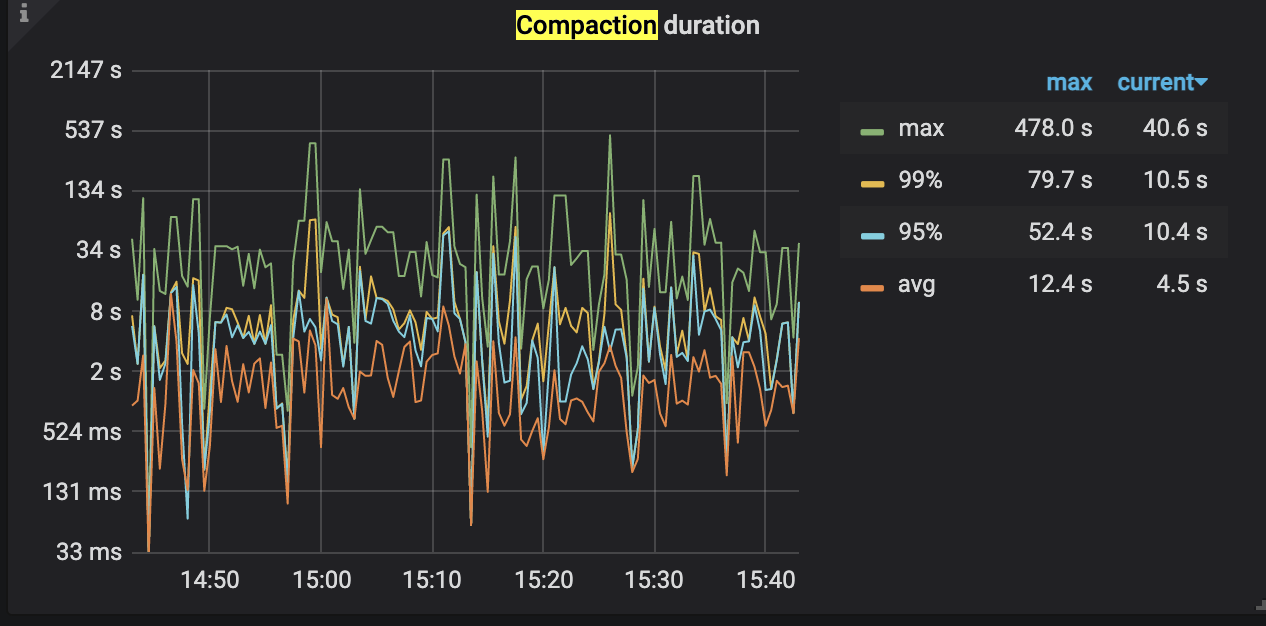
根据监控显示,整体compaction duration数值较高
主要参考了
https://asktug.com/t/topic/68073/13帖子的内容,但该贴内容主要是针对pending bytes超过64导致的stall给出了优化方法,而由监控可知我们的集群并没有write stall,该帖没有给出compaction duration较大时的优化方法
test-cluster-TiKV-Details_2021-07-14T07_45_17.342Z.json.zip (1.0 MB)
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
慢查询较多
【TiDB 版本】
4.0.13
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
3 个赞
这道题我不会
(Lizhengyang@PingCAP)
2
集群的磁盘类型是什么?除了 compaction duraiont 高之外,从监控中还看集群整体的 append/apply log duration 都很高,麻烦反馈下 node_expoter 中各 tikv 节点的磁盘时延情况。
1 个赞
abcd
(Abcd)
3
2 个赞
spc_monkey
(carry@pingcap.com)
4
在 asktug 中,有 读流程/写流程 慢的排查文档。可以 参考一下
2 个赞
abcd
(Abcd)
5
正如标题所述,compaction部分信息已经参考了https://asktug.com/t/topic/95104写性能第五条,没有找到针对目前问题的解决方案,那我只能继续再看一下其他部分了
1 个赞
spc_monkey
(carry@pingcap.com)
6
先说问题哈,
1、你的集群机会没有在用,但你的 IO 延迟似乎非常高,咱们有个监控 :disk- performance ,第一个指标就是 disk 延迟的,建议你看看(进入编辑模式,把 写延迟的表达式打开)
2、你的 region 大小,非常大(监控显示 400G?我都怀疑是不是监控错了,默认是96 M,就算写的非常快,我最多监控 1G 的),你集群配置,没有改 region 大小啥的吧?
3、你这是生产还是测试,这个情况多久了
1 个赞
abcd
(Abcd)
7
1、
2、没有修改过region大小,默认配置
3、生产环境,什么时候开始的已经无从考证了,看监控最近30天应该是一直都有的,
1 个赞
spc_monkey
(carry@pingcap.com)
8
延迟达到 4ms 其实算比较高的了,但你的 QPS 很少,感觉不至于,要不你看一下慢日志(slow.log),根据 具体的 SQL 看一下?
1 个赞
abcd
(Abcd)
9
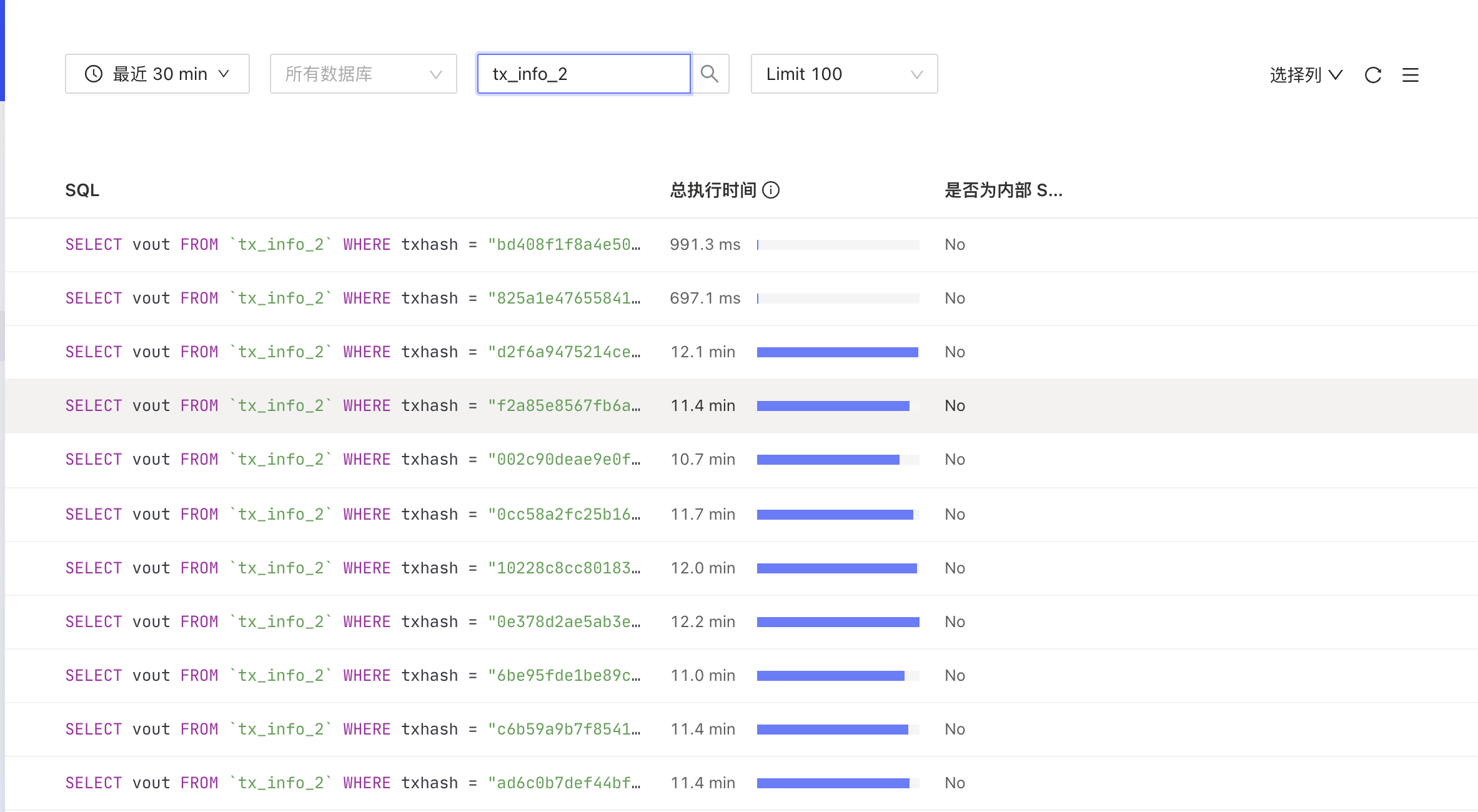
慢日志显示都是一个简单的点查,执行时间超过10分钟并且最终执行失败,由于太影响业务性能,现在已经通过设置max_execute_time限制了最大执行时间
1 个赞
spc_monkey
(carry@pingcap.com)
10
分析这些 SQL 的时候,建议看 慢日志文件或 系统表(里面信息更多一些)(会提供慢的原因)
1 个赞
abcd
(Abcd)
11
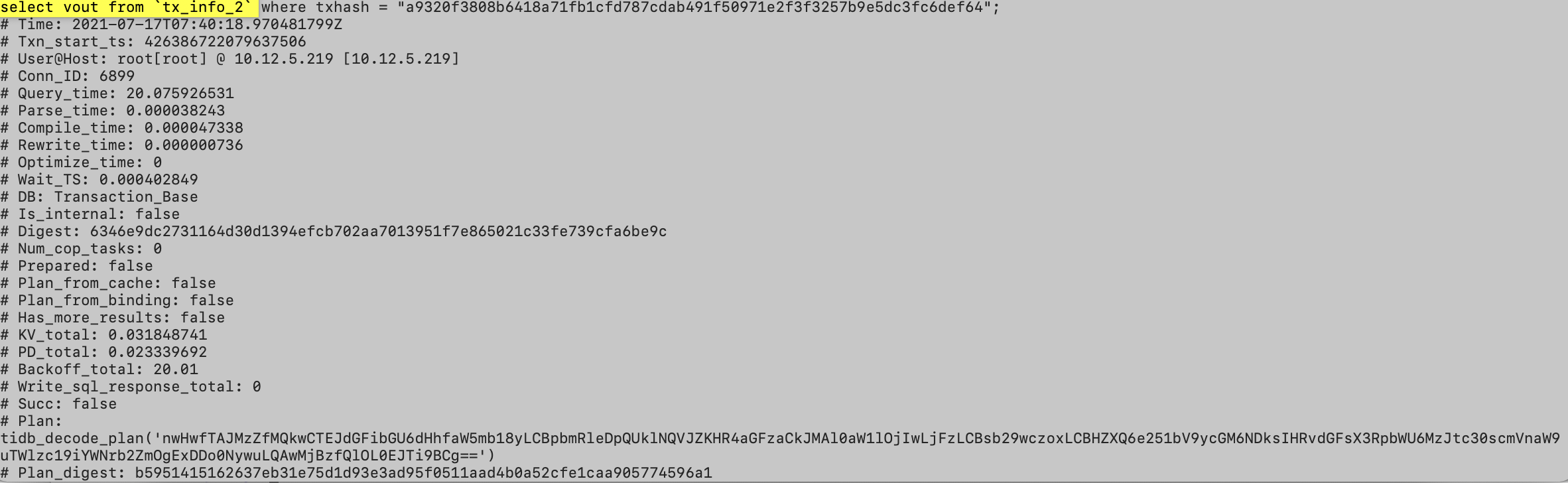
慢查询日志如下:
链接: 百度网盘-链接不存在 密码: agcd
以其中一条慢查询为例,从日志上看出了query_time以外其他时间都很短,如何进一步分析
1 个赞
spc_monkey
(carry@pingcap.com)
12
问一下你集群版本是多少啊,麻烦把。tidb- server / overview ,pd 的监控也给一下吧(你慢日志,backoff 的次数很多)
1 个赞
abcd
(Abcd)
13
1、集群版本4.0.13
2、overview:pd.zip (475.9 KB)
1 个赞
spc_monkey
(carry@pingcap.com)
16
还是想确认一下:joy:
1、咱们的 sda 不是数据盘对吧,为什么这么高?
2、咱们的一台服务器上,部署了几个实例(服务),然后有没有部署其他程序啊
abcd
(Abcd)
17
abcd
(Abcd)
18
1、sda就是数据盘
2、集群状况如图,每一台服务器上都只有一个实例,没有部署其他程序
spc_monkey
(carry@pingcap.com)
20
建议咱们
1、排查一下,集群各个服务器 IO 为什么实用这么高(排查一下是否有其他程序占用)
2、建议 你用 pd-ctl 把调度相关的 参数临时关闭半小时,观察一下集群及 IO 实用情况如何