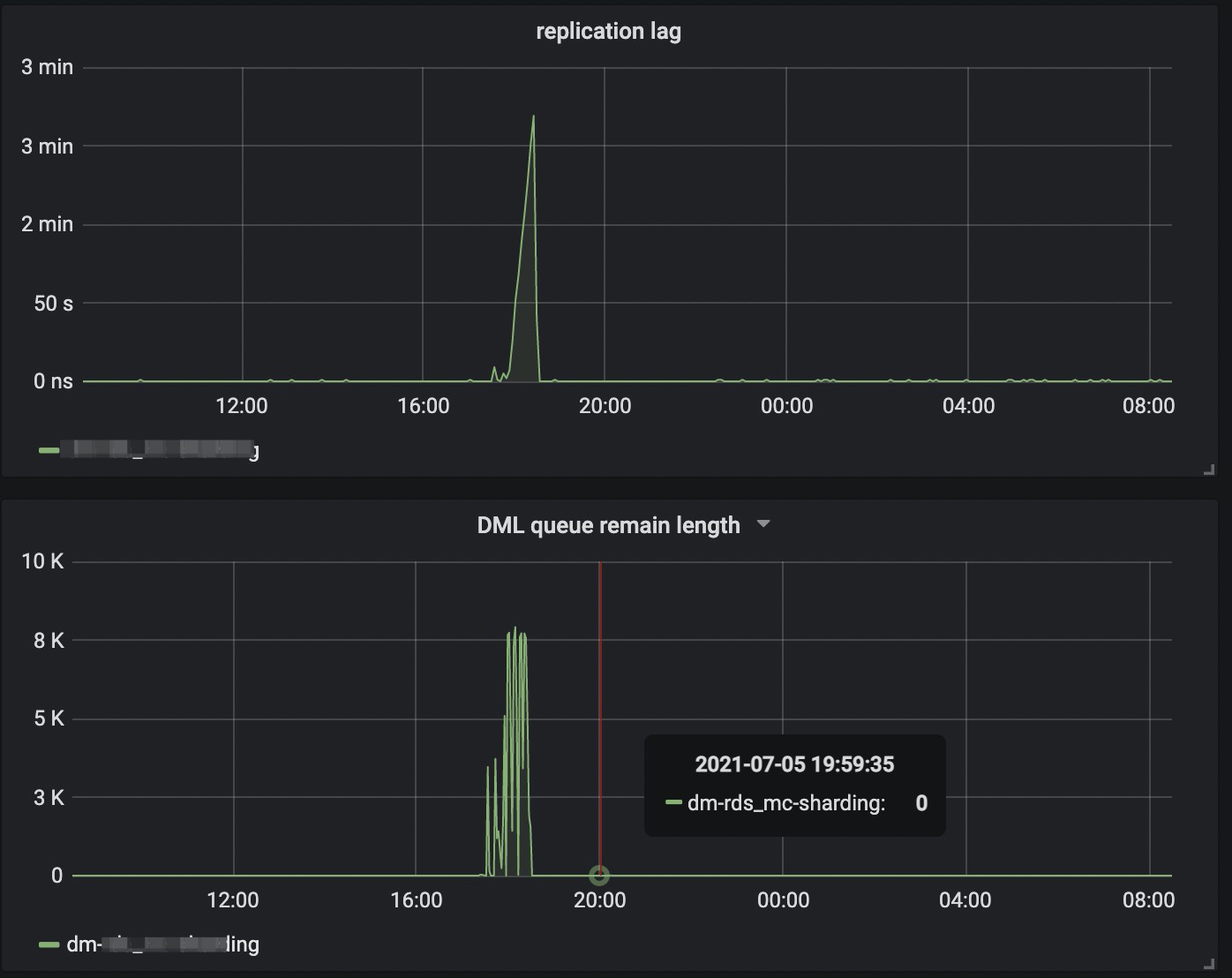
【概述】
DM版本2.0.4,目前发现一下两种情况出现cpu异常
- 全量导入完成且处于正常同步时,cpu利用率持续很高
- 当同步存在堆积或者延时后,随时间推移,堆积或延时会消除,但cpu利用率不会下降,持续很高
以上两种情况,在同步任务重启后,cpu会恢复到正常水平。如图:
【概述】
DM版本2.0.4,目前发现一下两种情况出现cpu异常
以上两种情况,在同步任务重启后,cpu会恢复到正常水平。如图:
Hi,想请您确认一下下面几个问题
A:如果是一个全量+增量任务,一定会出现1吗
B:如果增量任务一开始没有延时,CPU使用率就不会上升(大约在5%)一旦有了延迟,CPU使用率会变为20%
C:有没有使用 relay log 功能
D:您同步的表结构可以去除列名等敏感信息后发一份吗
A:就是全量加增量出现的
B:这个要看binlog event的量,随event的量变化;但是一旦有延时或堆积,cpu就不会再有很大的波动了
C:没有
D:如下,这个是256张表聚合后:
CREATE TABLE xxxx (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘主键Id,无业务含义’,
a bigint(20) unsigned NOT NULL,
b varchar(60) NOT NULL DEFAULT ‘0’,
c bigint(20) unsigned NOT NULL,
d tinyint(8) unsigned NOT NULL DEFAULT ‘2’,
e int(11) NOT NULL DEFAULT ‘0’,
f bigint(20) unsigned NOT NULL,
g timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
h timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
i tinyint(3) unsigned NOT NULL DEFAULT ‘1’,
j timestamp NULL DEFAULT NULL,
k bigint(20) unsigned NOT NULL DEFAULT ‘0’,
l tinyint(3) NOT NULL DEFAULT ‘0’,
m varchar(2048) DEFAULT NULL,
n tinyint(3) unsigned NOT NULL DEFAULT ‘1’ ,
o timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
p timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY ( id ),
UNIQUE KEY uk_a ( a ),
KEY idx_c ( c , d , i ),
KEY idx_f ( f ),
KEY idx_o ( o ),
KEY idx_p ( p ),
KEY idx_b ( b ),
KEY idx_acdi ( a , c , d , i ),
KEY idx_fo ( f , o )
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=1412224057797152049;
这是个bug吗?
原因还不确定,我们会在上面的仓库 issue 更新进展的
您好,我们使用 v2.0.4 版本的 DM,配置了一个增量任务,在任务结束后 DM-worker 的 CPU 回到了 10% 左右的水平。您这边下次出现该问题的时候,可以帮忙提供一些 debug 信息吗
curl -v http://<worker-IP>:<worker-port>/debug/pprof/profile > cpu.profile
在延迟已经追上,但是 CPU 占用率仍然高的时候,使用上面的命令抓取 DM-worker CPU 使用信息,然后将 cpu.profile 提供到这里或者私信一个社区专家
要在有堆积的情况下,会出现这个问题
有堆积的时候 CPU 使用率高是预期的。我们的复现是在有堆积的时候 CPU 使用率高,数据追上之后 CPU 回落了
按照您在一楼的描述,“堆积或延时会消除,但cpu利用率不会下降”,这个不是预期的。希望您提供一下此时的 debug 信息
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。