为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】场景+问题概述
模拟PD故障的场景
【背景】做过哪些操作
不小心将pd的数据目录和部署目录都删除了, 要怎么恢复集群的状态呢?
【现象】业务和数据库现象
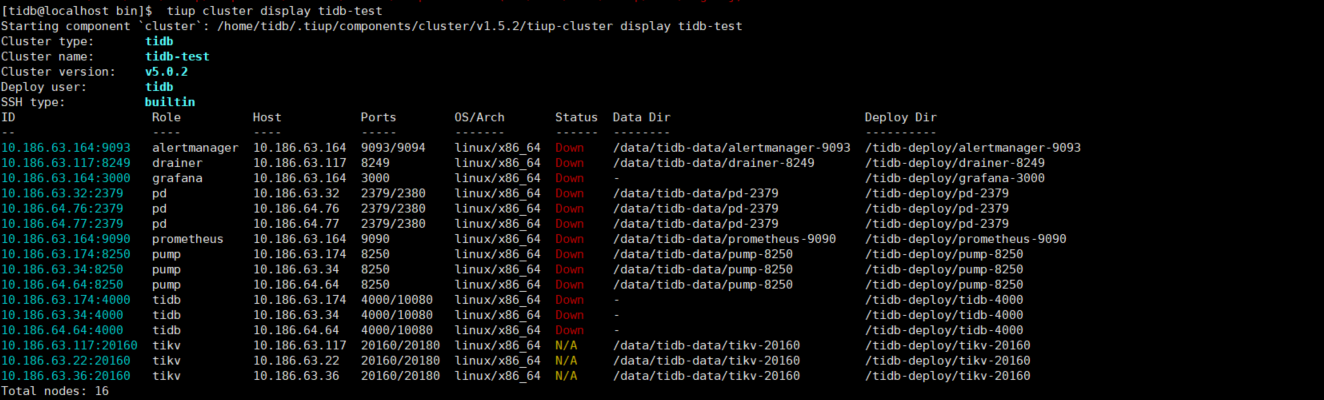
【业务影响】
【TiDB 版本】
v5.0.2
【附件】
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】场景+问题概述
模拟PD故障的场景
【背景】做过哪些操作
不小心将pd的数据目录和部署目录都删除了, 要怎么恢复集群的状态呢?
【现象】业务和数据库现象
【TiDB 版本】
v5.0.2
【附件】
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
以下操作均为实验步骤,建议在测试环境进行充分测试,并根据实际的 IP,Port,目录情况进行修改
因为所有的 PD 节点均出现异常,且无法连接,所以无法使用 TiUP 来新部署 PD 节点,此处需要手动部署。
如新 deploy 的 PD Server 服务器的 IP 地址为 IP_New
IP_New 上创建相应的目录,并且该目录结构要以原 PD 结构为准(tiup cluster edit-config {cluster_name} 可以查看相关目录),并且确认目录权限无误
mkdir -p /home/tidb/xxx/tidb-deploy/tidb-data/pd-2179
mkdir -p /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/scripts
mkdir -p /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/log
mkdir -p /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/bin
mkdir -p /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/conf
从 TiUP 的目录中拷贝 PD 的 binary 文件,到目标服务器 IP_New
1) 从中控机拷贝 pd 的 binary 文件
scp /home/tidb/.tiup/components/pd/v5.0.2/pd-server IP_New:/home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/bin
2) 修改 binary 文件的权限
编辑 run_pd.sh 脚本
$ cd /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/scripts
$ vi run_pd.sh
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=/home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179
cd "${DEPLOY_DIR}" || exit 1
exec bin/pd-server \
--name="pd-IP_New-2479" \
--client-urls="http://0.0.0.0:2179" \
--advertise-client-urls="http://IP_New:2179" \
--peer-urls="http://0.0.0.0:2180" \
--advertise-peer-urls="http://IP_New:2180" \
--data-dir="/home/tidb/xxx/tidb-deploy/tidb-data/pd-2179" \
--initial-cluster="pd-IP_New-2479=http://IP_New:2180" \
--config=conf/pd.toml \
--log-file="/home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/log/pd.log" 2>> "/home/tidb/gzj/tidb-deploy/cluster-deploy/pd-2179/log/pd_stderr.log"
编辑 pd.toml 配置文件
$ cd /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/conf
https://github.com/tikv/pd/blob/master/conf/simconfig.toml
编辑 pd-2179.service
$ vi pd-2179.service
[Unit]
Description=pd service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
LimitSTACK=10485760
User=tidb
ExecStart=/home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179/scripts/run_pd.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
启动 PD Server
$ systemctl start pd-2179.service
cluster id 以及 Alloc ID
// 获取 cluster id
-- 通过 tidb.log 获取
$ cat tidb.log | grep "init cluster id"
[2021/05/08 09:58:52.619 +00:00] [INFO] [base_client.go:126] ["[pd] init cluster id"] [cluster-id=6959847903187149571]
-- 通过 tikv.log 获取
cat tikv.log | grep "connect to PD cluster"
[2021/05/13 09:55:57.659 +00:00] [INFO] [server.rs:298] ["connect to PD cluster"] [cluster_id=6959847903187149571]
// 获取 Alloc ID
通过 Grafana PD Dashboard --> Cluster --> Current ID allocation 来获取,此处假设为 500001,请以实际的的数据为准
$ ./pd-recover -endpoints http://IP_New:2179 -cluster-id 6959847903187149571 -alloc-id 50001
recover success! please restart the PD cluster
$ cat pd.log | grep "init cluster id"
[2021/05/17 11:28:30.688 +08:00] [INFO] [server.go:352] ["init cluster id"] [cluster- id=6959847903187149571]
编辑 tiup 的 meta 文件:
$ vi /home/tidb/.tiup/storage/cluster/clusters/gzj-test/meta.yaml
pd_servers:
# 请将故障的原 3 个 pd server 的信息注释掉
#- host: 172.16.x.107
# ssh_port: 22
# name: pd-172.16.x.107-2479
# client_port: 2179
# peer_port: 2180
# deploy_dir: /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179
# data_dir: /home/tidb/xxx/tidb-deploy/tidb-data/pd-2179
# arch: amd64
# os: linux
# 将手动部署的 pd server 信息补充到 meta.yaml 中
# 并且和上面手动 deploy pd 的 run_pd.sh 脚本中配置,保持一致,如下面的 name 与 run_pd.sh 中的 --name 对应
- host: 172.16.4.237
ssh_port: 22
name: pd-IP_New-2479
client_port: 2179
peer_port: 2180
deploy_dir: /home/tidb/xxx/tidb-deploy/cluster-deploy/pd-2179
data_dir: /home/tidb/xxx/tidb-deploy/tidb-data/pd-2179
arch: amd64
os: linux
注意:下述操作为此极端场景下的非常规操作手段,所以一般情况下强烈建议不要直接修改 meta.yaml 原文件!
TiUP display 查看新 deploy 的 PD Server 的状态
因为 PD 信息在原有的 TiKV 以及 TiDB 的 run_tidb.sh / run_pd.sh 脚本中,仍然是记录的旧的不可用的 PD 信息,故需要更新为新 deploy 的 PD Server:
此操作会更改除 PD 外其他组件的 run 脚本,请在测试环境充分验证后使用
// 以 TiDB Server 为为例,可见 PD 信息仍为不可用 PD
$ more run_tidb.sh
// tiup reload TiKV 以及 TiDB
$ tiup cluster reload gzj-test -R tidb,tikv
Starting component `cluster`: /home/tidb/.tiup/components/cluster/v1.4.3/tiup-cluster reload gzj-test -R tidb,tikv
+ [ Serial ] - SSHKeySet: privateKey=/home/tidb/.tiup/storage/cluster/clusters/gzj-test/ssh/id_rsa, publicKey=/home/tidb/.tiup/storage/cluster/clusters/gzj-test/ssh/id_rsa.pub
+ [Parallel] - UserSSH: user=tidb, host=172.16.x.237
+ [Parallel] - UserSSH: user=tidb, host=172.16.x.237
+ [Parallel] - UserSSH: user=tidb, host=172.16.x.107
+ [Parallel] - UserSSH: user=tidb, host=172.16.x.107
..................
..................
Reloaded cluster `gzj-test` successfully
// 验证 Reload 后的 run_xx.sh 脚本内容,以 TiDB Server 为例
$ more run_tidb.sh
#!/bin/bash
set -e
WARNING: This file was auto-generated. Do not edit!
All your edit might be overwritten!
DEPLOY_DIR=/home/tidb/gzj/tidb-deploy/cluster-deploy/tidb-4111
cd "${DEPLOY_DIR}" || exit 1
exec env GODEBUG=madvdontneed=1 bin/tidb-server \
-P 4111 \
--status="11181" \
--host="0.0.0.0" \
--advertise-address="172.16.x.107" \
--store="tikv" \
--path="IP_New:2179" \
--log-slow-query="log/tidb_slow_query.log" \
--config=conf/tidb.toml \
--log-file="/home/tidb/xxx/tidb-deploy/cluster-deploy/tidb-4111/log/tidb.log" 2>> "/home/tidb/xxx/tidb-deploy/cluster-deploy/tidb-4111/log/tidb_stderr.log"
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。