为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】:场景 + 问题概述
【背景】:做过哪些操作
【现象】:业务和数据库现象
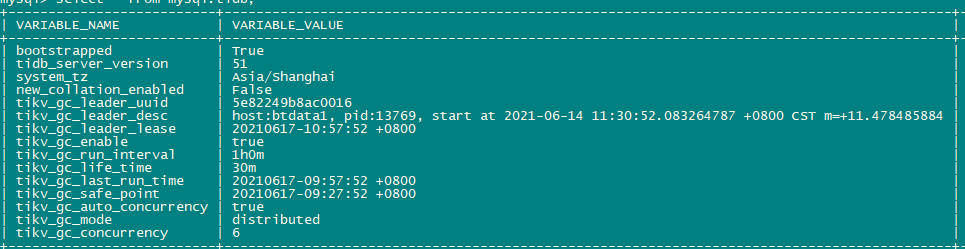
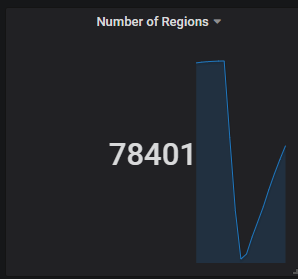
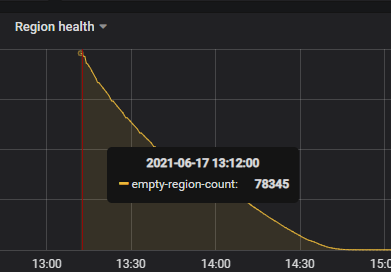
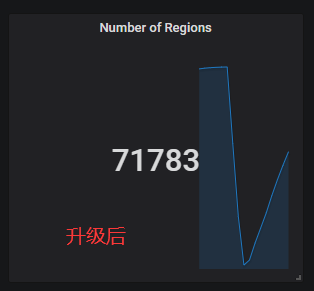
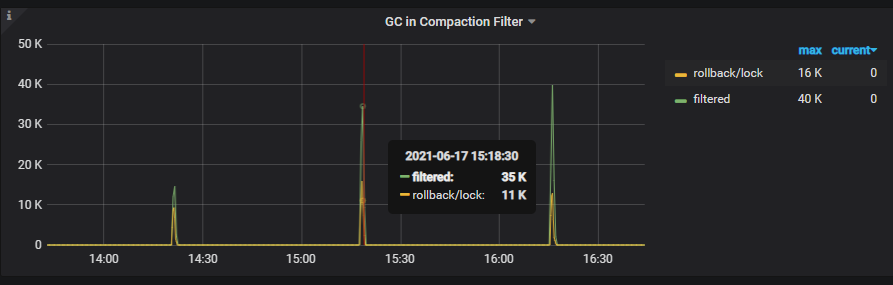
【问题】:使用kafka进行数据消费同步,tidb集群中3个tikv节点,每节点4块SAS盘,其中67.80节点IO利用率高,GC时间长。监控见附件
【业务影响】:
【TiDB 版本】:4.0.13
【附件】:
grafana.rar (3.8 MB)
pd-ctl store|grep -E ‘id|address’
“id”: 4,
“address”: “10.161.67.80:20160”,
“status_address”: “10.161.67.80:20180”,
“id”: 5,
“address”: “10.161.67.85:20160”,
“status_address”: “10.161.67.85:20180”,
“id”: 1,
“address”: “10.161.67.84:20160”,
“status_address”: “10.161.67.84:20180”,