流量比这个集群大的也有,每个集群的流量都不一样,这个异常的集群流量和数据量都不是最大的,但是监控数据最多。
这个怎么理解?如果说采集频率是15秒,每次Prometheus向各个exporter发请求拉数据,不同集群拿到的metric应该也都是一样的,所以条目数是大致一样的吧。然后保存周期也是一样的,所以总的数据量应该差距不太大吧。
如果说因为每次采集到的数据变化量大,导致无法压缩,那应该是大部分集群大,有一个常年采集到的数据都是000000,然后好压缩,这个好压缩的量小。
怎么继续定位?
流量比这个集群大的也有,每个集群的流量都不一样,这个异常的集群流量和数据量都不是最大的,但是监控数据最多。
这个怎么理解?如果说采集频率是15秒,每次Prometheus向各个exporter发请求拉数据,不同集群拿到的metric应该也都是一样的,所以条目数是大致一样的吧。然后保存周期也是一样的,所以总的数据量应该差距不太大吧。
如果说因为每次采集到的数据变化量大,导致无法压缩,那应该是大部分集群大,有一个常年采集到的数据都是000000,然后好压缩,这个好压缩的量小。
怎么继续定位?
这个理解是对的。我怀疑的是数据的压缩比不一样导致的。
具体怎么看?这个都是tidbmonitor这个crd生成的资源,配置是一样的。或者说有什么办法调整下压缩比,直接压缩下试试?我看tidbmonitor里面有个commandOptions,我如果想加–storage.tsdb.wal-compression 或者降低采集频率,怎么处理?
我不是专门做 prometheus 的,所以可能建议不是很专业。
可以尝试一下调整 scrape_interval
也可以看一下 storage.local.max-chunks-to-persist
这个是一个 prometheus 的问题。您可以到 prometheus 社区获得专业的帮助。
这个不是 tidb 的参数,是 prometheus 的参数。所以需要在 prometheus 的配置文件添加。
主要全部通过operator管的,咨询下operator添加的方法
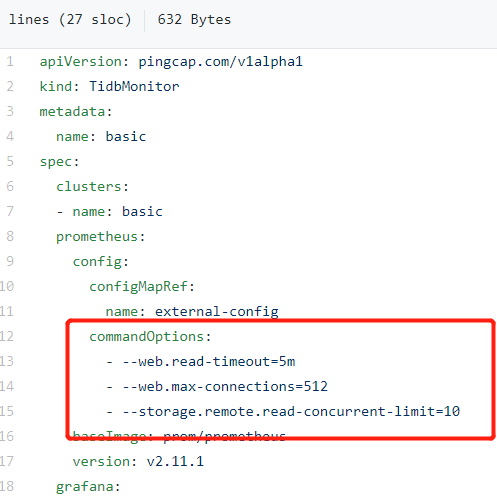
试了下模仿图中的加法增加一个–storage.tsdb.wal-compression方法,不好使,得同时把配置文件挂出来。
同时希望pingcap的大神继续帮忙定位下,具体为什么这个集群的数据超别的集群那么多。
试了下模仿图中的加法增加一个–storage.tsdb.wal-compression方法,不好使 不好使是说没有生效?Operator 版本是什么? 配置 yaml 发一下看看?
我尝试了一下加 --storage.tsdb.wal-compression, 可以加到 Prometheus 的启动项上,不知道不好使是说没有生效还是没办法解决问题,另外可以贴一下 Monitor 的相关配置
新开了个帖子,把正确的配置信息贴哪里了。
不好使的意思是上面说的,如果不加/etc/prometheus/prometheus.yaml的话,pod启动不了。
参考上一个回帖
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。