复制链接完成认证,获得“加急”处理问题的权限,方便您更快速地解决问题。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【概述】 场景 + 问题概述
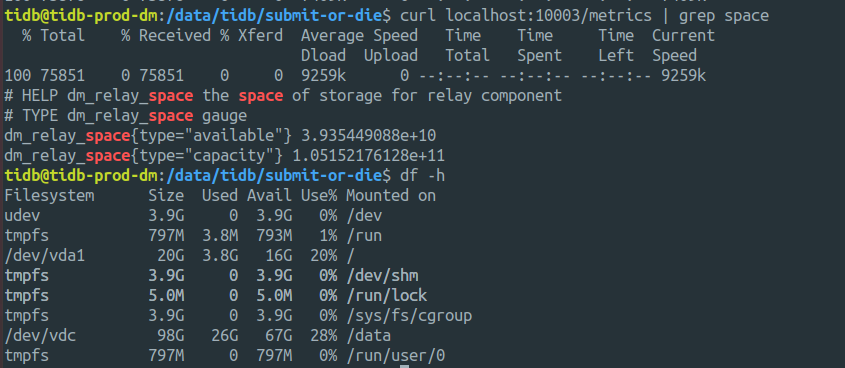
DM 监控 dm_relay_space 指标不更新
【备份和数据迁移策略逻辑】
【背景】 做过哪些操作
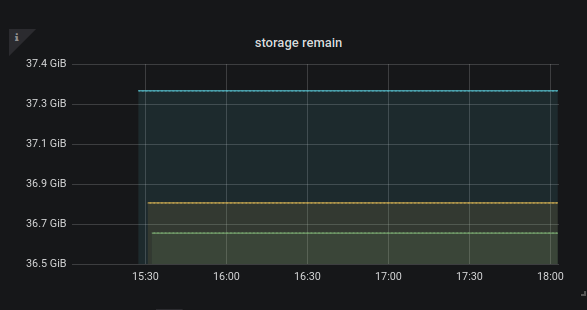
将 v1.0.* 的集群手动迁移到 v2.0.3 的版本后观察监控,图表上一直展示的是部署完启动完毕时的硬盘可用容量。其后我手动删除了旧版本的一些 relay-log 释放了几十G的空间,但监控上并没有产生变化,观察时间约2个半小时
【现象】 业务和数据库现象
指标不正确
【问题】 当前遇到的问题
指标不正确,希望确认是否为 bug
【业务影响】
暂无影响
【TiDB 版本】
v4.0.13
【附件】
- 相关日志、配置文件、Grafana 监控(https://metricstool.pingcap.com/)
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
- TiDB-Overview 监控
- 对应模块的 Grafana 监控(如有 BR、TiDB-binlog、TiCDC 等)
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yilong
(yi888long)
2
应该相当于是一个全新的部署,之前是v1.0的dm,tiup 直接部署到新的实例上之后手动迁移了一遍 task。
我明天试一下重启 relay log
小王同学
4
2.0 默认 relay_log 是关闭的,需要手动打开。如果你这边是全新的部署。那需要你这边手动开启下 relay_log。
对 我当然是开了 relay_log 然后看监控的,不开的话监控里这个指标是没数据的,有数据就说明开了。现在的问题是这个指标并不更新,不体现真实的硬盘容量。
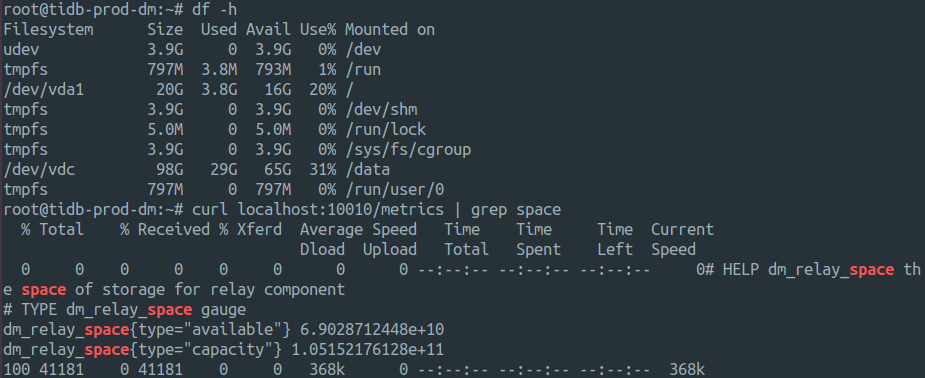
我刚才将三个开了 relay 的实例中的一个 stop 再 start relay,硬盘指标更新了。
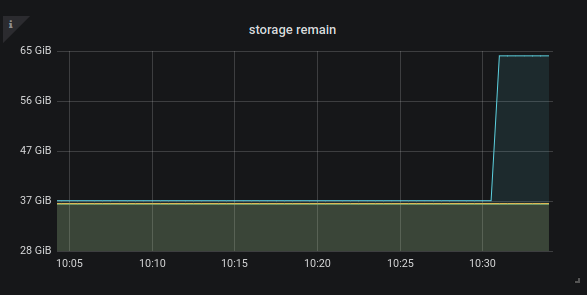
我手动用 curl 读监控指标也是启动时候的硬盘容量。
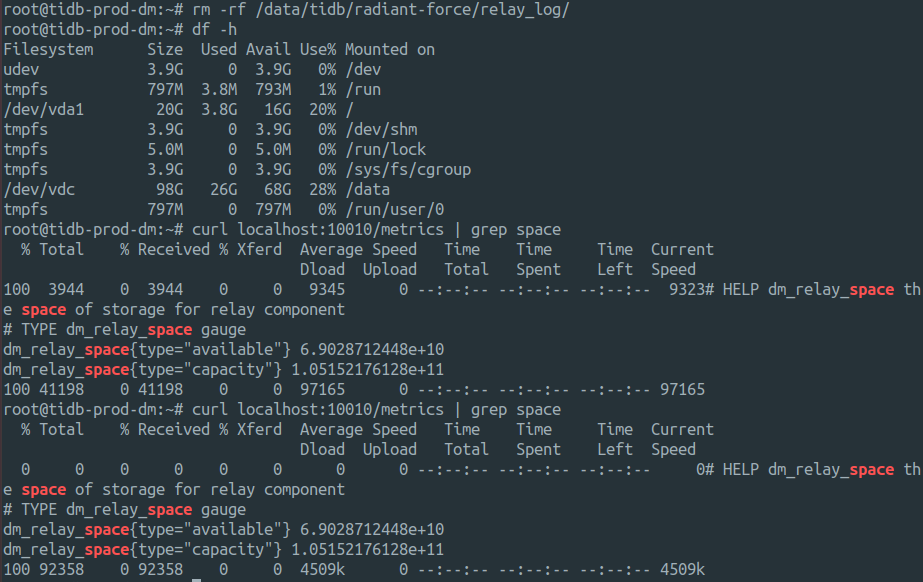
但我再次清理出一些容量,指标并不会更新。
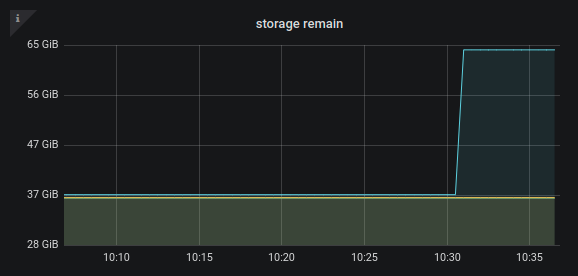
感觉就是这个指标采集有问题,或者就是这个指标的刷新需要一段时间,但实际上经过昨天一夜这个指标也没有变化。
yilong
(yi888long)
6
请问怎么清理的呢? 是直接 rm 删除的还是用dmctl命令清理的?
我清理的是旧的 v1.0 时候的数据,直接 rm 的,旧版本的所有硬盘上的东西其实都已经没有用了。
升级是在同一台机器上,在不同的目录部署的。把低版本的进程都停了之后手动在高版本的dm上启动task
小王同学
8
现在指标也是有问题的吗?我这边先确认下是否存在已知问题。