为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.12
【问题描述】
如下sql执行时未加limit选择了正确的索引但是加上limit就变成全表了,如果使用use index 便可以一直使用正确的索引。我想知道出现这种情况的原因

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.12
【问题描述】
如下sql执行时未加limit选择了正确的索引但是加上limit就变成全表了,如果使用use index 便可以一直使用正确的索引。我想知道出现这种情况的原因
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
可以将 limit 提前,order by 放后面试试,包个子查询,例如 select col_name from (select … limit 10) t order by t.col_name ;
把order by去了或者修改为order by jcsj desc , jlzj desc 就能走真确索引了,这是为什么呢
jcsj 是索引,jlzj不是索引,order by 要用索引字段
执行顺序上来看,order by不应该是在where条件之后么?
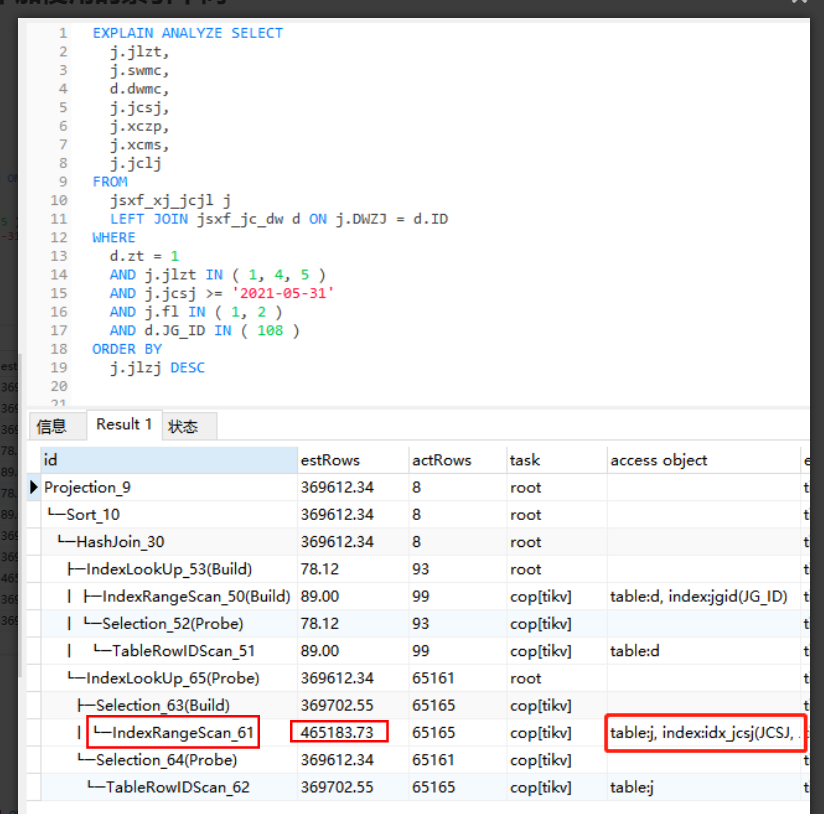
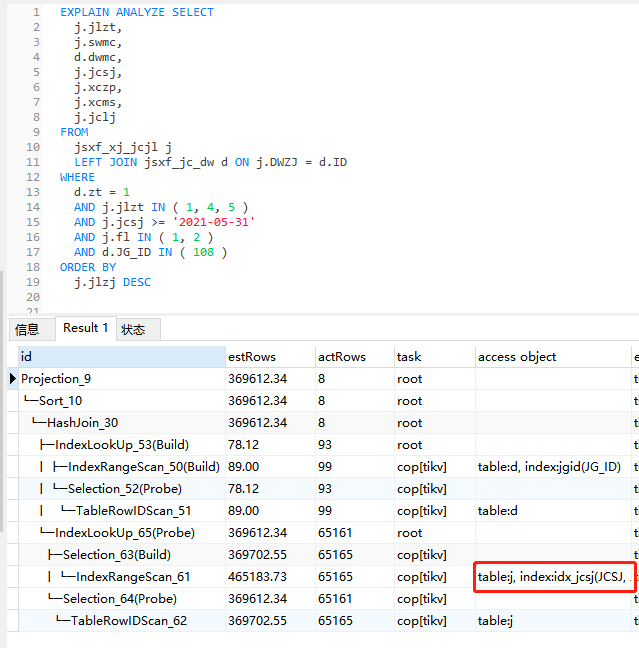
是在where 执行之后;如果order by是索引字段,那么where 和 order by都走索引。如果order by不是索引字段,这时候需要回表找数据再排序,成本优化器估算认为全表扫成本更低,会不走索引;看下 estRows 这列估值,优化器认为全表扫是低成本的,实际值 actRows 行数较大
不符合逻辑啊,排序应该是排序where筛选之后的数据,不应该是在where使用索引之后,再判断order by是否使用索引?
他这个估算的3w行是我关联表的数据量,而非主表的数据量,这个估算是不是不对
目前看估算有误差
是的,正常应该是先where 走索引拿到过滤后的数据,但是order by的不是索引列,需要回表对该列值再做排序。按照预估来看,预估走索引要扫40w的数据,不走索引扫表只要3w的数据,优化器选择了全表扫
没毛病,咱说的是一个意思。
40W跟4KW,相差一个数量级了