h5n1
2021 年5 月 31 日 03:18
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
【问题描述】
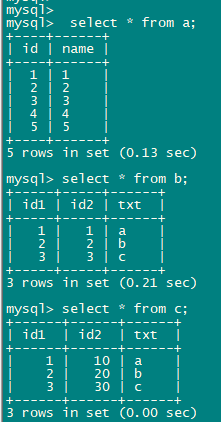
问题: TableRangScan的具体执行过程或者说是如何实现的?有什么前提条件? 官网只是解释为:一类按范围进行的扫表操作。没有其他具体说明
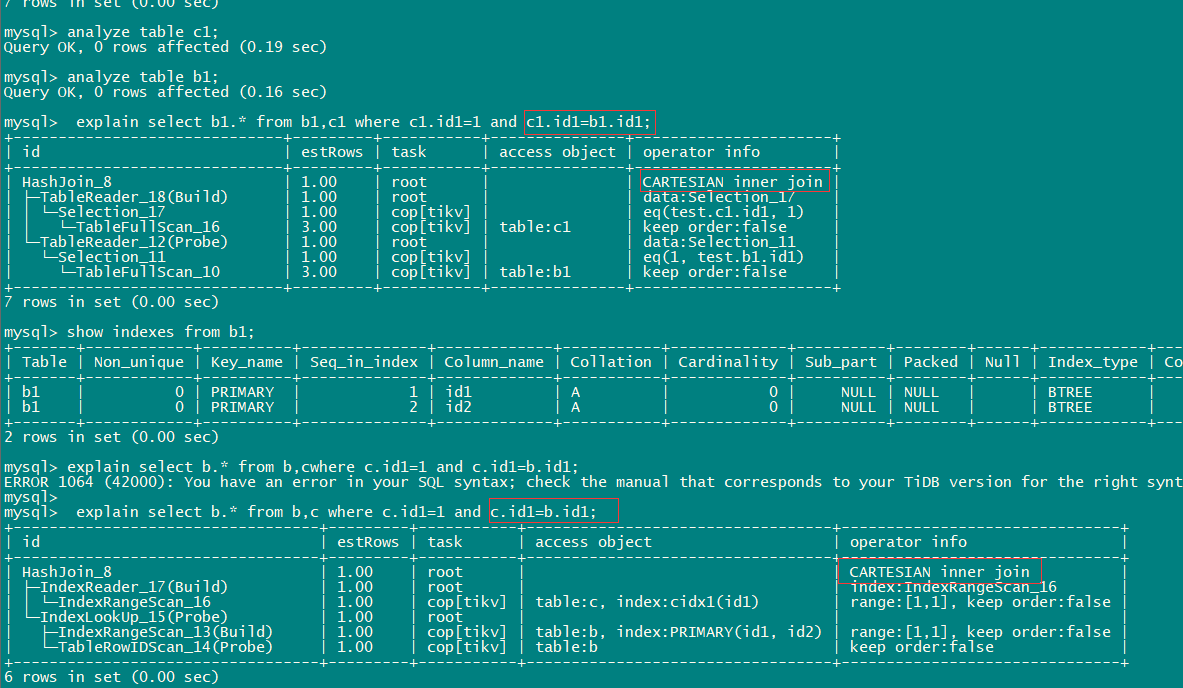
3、 a c关联(c无索引),a驱动c,a c全表扫描,hash join
问题: c有过滤条件c.id1=1,全表扫描后只有1条数据,不应该是c作为外表驱动a表更合适吗?
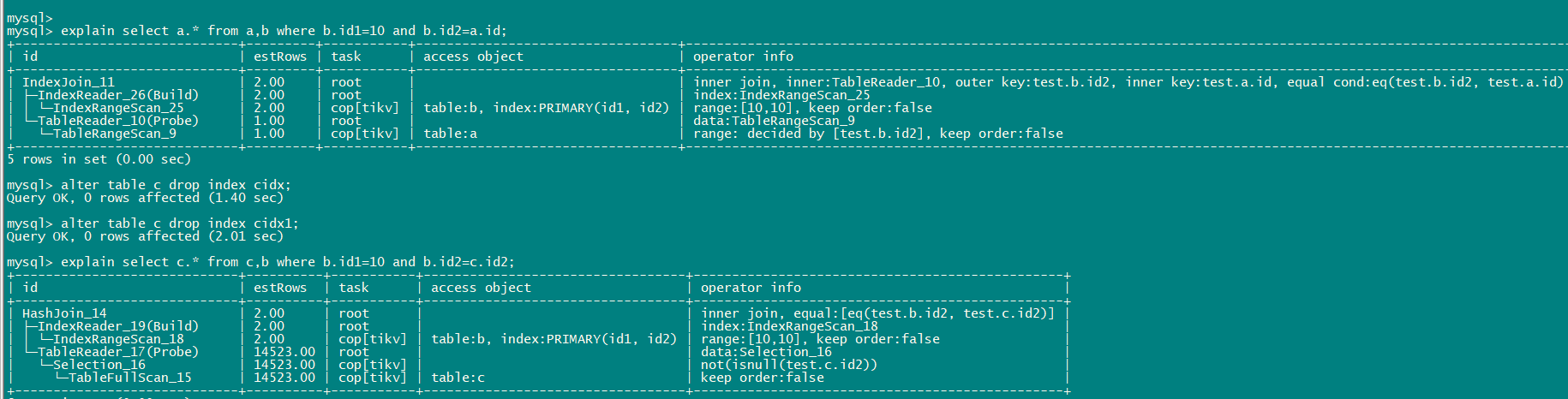
4、 a c关联(c.id1添加索引),a表TableRangeScan, c 仍然全表扫描
问题: c表id1在建立索引后,有列信息、直方图信息可以看到id1=1是bucket里只有1个值,此时优化器仍然选择了c全表扫描,只不过是c作为了驱动表,为什么c不能直接使用索引?
5、 ac关联,c强制索引后使用索引扫描
问题: c表使用强制索引后可以使用索引,如何看到c表索引扫描、全表扫扫描的估算?
问题6、 TiDB 源码阅读系列文章(十一)Index Lookup Join里对index join的解释里貌似并没有体现index,只是说驱动表分成多批,每批次计算一个范围然后根据这个范围去扫描内表,也没有说内表的扫描方式,索引index join怎么体现的index?
谢谢!
1 个赞
h5n1
2021 年6 月 1 日 02:11
3
感谢,对这些问题还是有些疑惑,
TableRangScan 问题:
c驱动a问题,在 a c表有1万条数据情况下,执行计划正常,c全表扫描后驱动A,走index join。
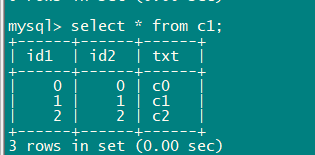
按照a b c表结构创建a1 b1 c1, 删除c1上索引,只插入3条数据,执行计划正常,c全表扫描后驱动A,走index join
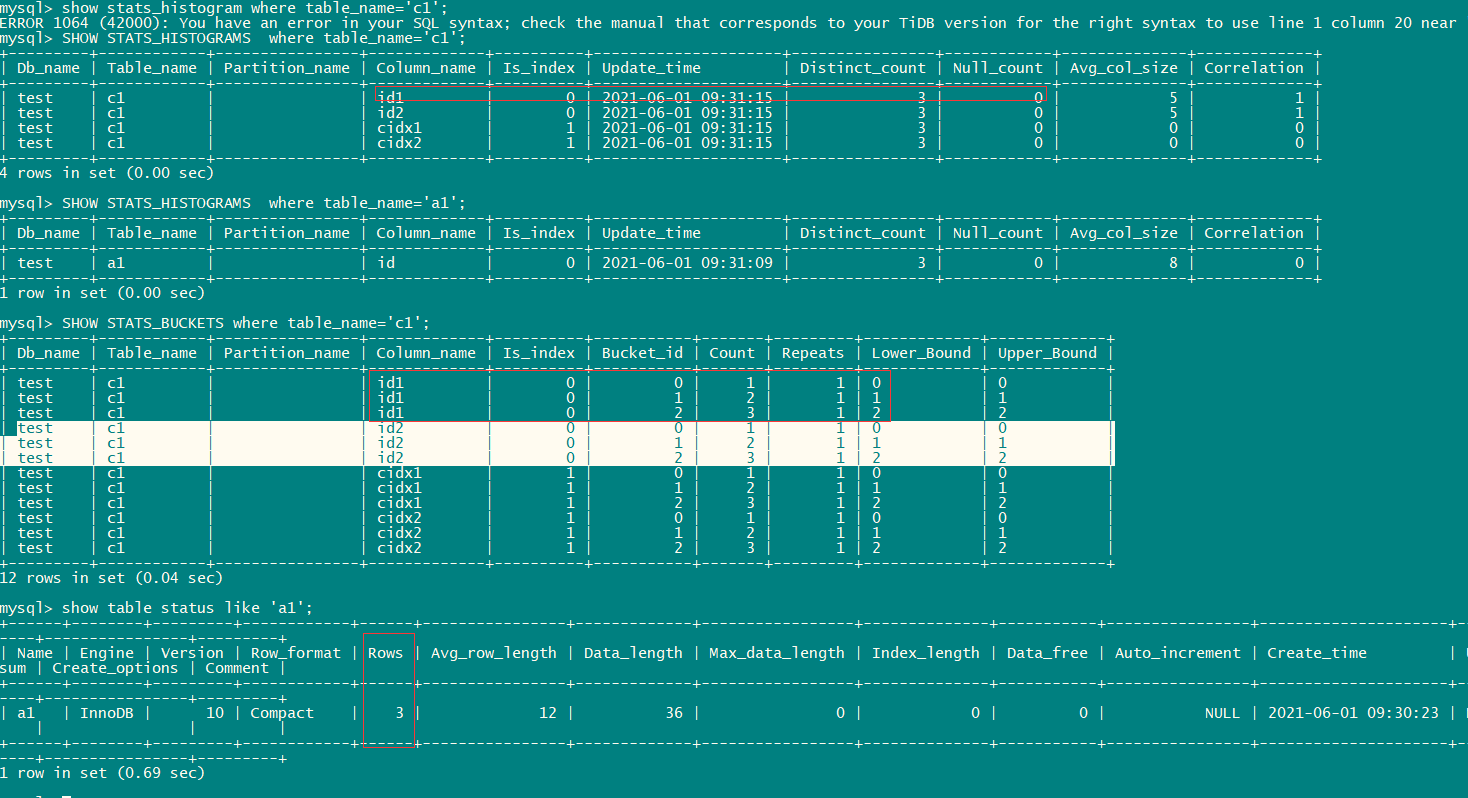
上述执行计划对c1.id1=10和c1.id1=1行数预估有误,表行数3,c1.id1唯一值3,直方图桶数3,每桶值数量1,无论id1的值是否落在直方图范围内,评估行数都是6。
官方描述“而 operator info 中的 stats:pseudo 表示可能因为没有统计信息,或者统计信息过旧,不会用统计信息来进行估算” 有2个问题要请教: 1. 没有统计信息时 如何进行行数估算? 2. 达到什么样的条件是过旧的统计信息(stats_healthy?)
看博客文章的描述 index join跟index没啥关系,如果Index join时内表一定是走索引的话,上面的测试中index join时 内表走的tablerangescan,又回到了table range scan具体执行过程的问题了。
6月2日,查询user表(此时的user表已重建为非分区)由于serial_number类型不对,导致没能走该列上的索引,产生了tablerangscan
h5n1
2021 年6 月 10 日 04:57
7
学习了, 生成执行计划时无法获得从驱动表获取记录的数量或值,所以user表的range是[0,+inf]. 就是一个全表扫描了,有统计信息评估从驱动表获取的行数和从被驱动表预估读取的行数,按理比这种[0,+inf]的rangescan成本要低很多
Lucien
2021 年6 月 13 日 12:34
8
如果楼上的同学的反馈已经帮助你解决问题,可以为该帖子设置为 “对我有用”,鼓励一下回复帖子的同学。
h5n1
2021 年7 月 6 日 01:23
9
tablerangescan具体是如何实现的,有什么条件约束? 如上面的例子SQL没有where条件,但是执行计划时走的tableRangeScan,范围[0.+inf]。 和tableFullScan扫描的差异在哪?
不懂就问
2021 年7 月 7 日 07:16
10
区别可以看下这里:https://docs.pingcap.com/zh/tidb/stable/explain-overview#如何阅读扫表的执行计划
这里什么没有带条件约束还是走的 tablerangescan 是因为主键是非负的,所以是 [0,+inf]。如果是全表扫,这里应该是[-inf , +inf]。