为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
V4.0.8
【问题描述】
如题所示,想知道当前某张表正在写入的regionID,从而去分析对应tikv节点是否有硬件或者其他性能方面的问题。
通过show table regions,我看到有不少region当前的’WRITEN_BYTES’非0,这个应该不是作为判断的依据吧?或者说,结果中最后一个region即正在写入的吗
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
Kongdom
(Kongdom)
2
谢谢你的回答。不过我看了下,正在写入的表,scattering这个字段也是0。
我理解这个字段的含义是pd是否在将某个region做调度(由于split或某个store节点挂掉需要迁移等),与写入没有关系。欢迎继续探讨~
xfworld
(魔幻之翼)
5
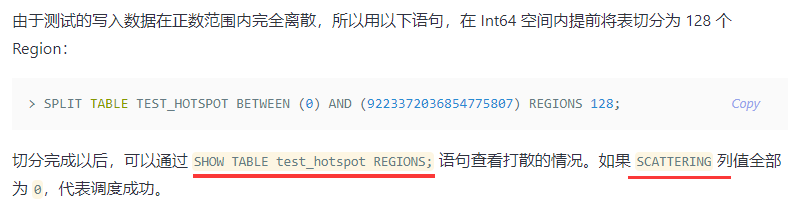
参考下这个,或许有帮助
URI:https://docs.pingcap.com/zh/tidb/v4.0/sql-statement-show-table-regions#示例
SHOW TABLE REGIONS
SHOW TABLE REGIONS 语句用于显示 TiDB 中某个表的 Region 信息。
语法
SHOW TABLE [table_name] REGIONS [WhereClauseOptional];
SHOW TABLE [table_name] INDEX [index_name] REGIONS [WhereClauseOptional];
结果显示示例表被切分成多个 Regions。 REGION_ID 、 START_KEY 和 END_KEY 可能不完全匹配:
Copy
SHOW TABLE t1 REGIONS;
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 94 | t_75_ | t_75_r_31717 | 95 | 1 | 95 | 0 | 0 | 0 | 112 | 207465 |
| 96 | t_75_r_31717 | t_75_r_63434 | 97 | 1 | 97 | 0 | 0 | 0 | 97 | 0 |
| 2 | t_75_r_63434 | | 3 | 1 | 3 | 0 | 269323514 | 66346110 | 245 | 162020 |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
3 rows in set (0.00 sec)
解释:
上面 START *KEY 列的值 t_75_r_31717 和 END_KEY 列的值 t_75_r_63434 表示主键在 31717 和 63434 之间的数据存储在该 Region 中。t_75* 是前缀,表示这是表格 (t) 的 Region,75是表格的内部 ID。若START_KEY或 END_KEY 的一对键值为空,分别表示负无穷大或正无穷大。
然后 Split Region 使用文档 也可以参考下 https://docs.pingcap.com/zh/tidb/v4.0/sql-statement-split-region#split-table-region
可以自己控制分裂的方式,也可以通过上面的方式来定义
数据的写入,是通过键值和region之间的关系来表达的
希望对你有所帮助!
那是不是可以这样理解:如果end_key为空,表示当前region正在写入?
不过我看了线上一张表,好像不是这样的
xfworld
(魔幻之翼)
7
若 START_KEY 或 END_KEY 的一对键值为空,分别表示负无穷大或正无穷大。
我关注的是,如果判断当前写入的region是哪一个…
xfworld
(魔幻之翼)
9
你通过SHOW TABLE t1 REGIONS
和你设定的分割方案,不能确定写入到那一个Region 么?
没有配置过split规则,这种情况那就是最后一个region为当前写入的, 而且也仅有这个region?
谢谢。 这种情况下,已经运行了很长时间的,还能设定split方案么?
这个表运行到现在,加上索引总共有6000+region了;业务场景有大量的upsert动作,性能很差…
xfworld
(魔幻之翼)
13
你最好找个测试环境,把数据都转过去,
然后利用DDL 的方式 (分区的方式),修改regions,或者 用 spilt 试试
分区方式有两种:
-
hash (无法调整)
-
区间(区间可以调整)
建议你用区间的方式,操作文档在官方文档中有,可以按照步骤操作看看
谢谢你详尽的答复。
第三个问题其实我想问的是:当达到96M拆分之后,客户端读写压力仍然会分散到多个region上吧
xfworld
(魔幻之翼)
19
对,会自动的分散
不过,能够按照规则来分散,这样的读写压力会更均匀,对于整个数据库来说会更稳
不然,会有峰值的情况,就会出现一个 慢 SQL 影响了其他正在执行的 SQL,效率会很低,这种情况要杜绝掉
xfworld
(魔幻之翼)
20
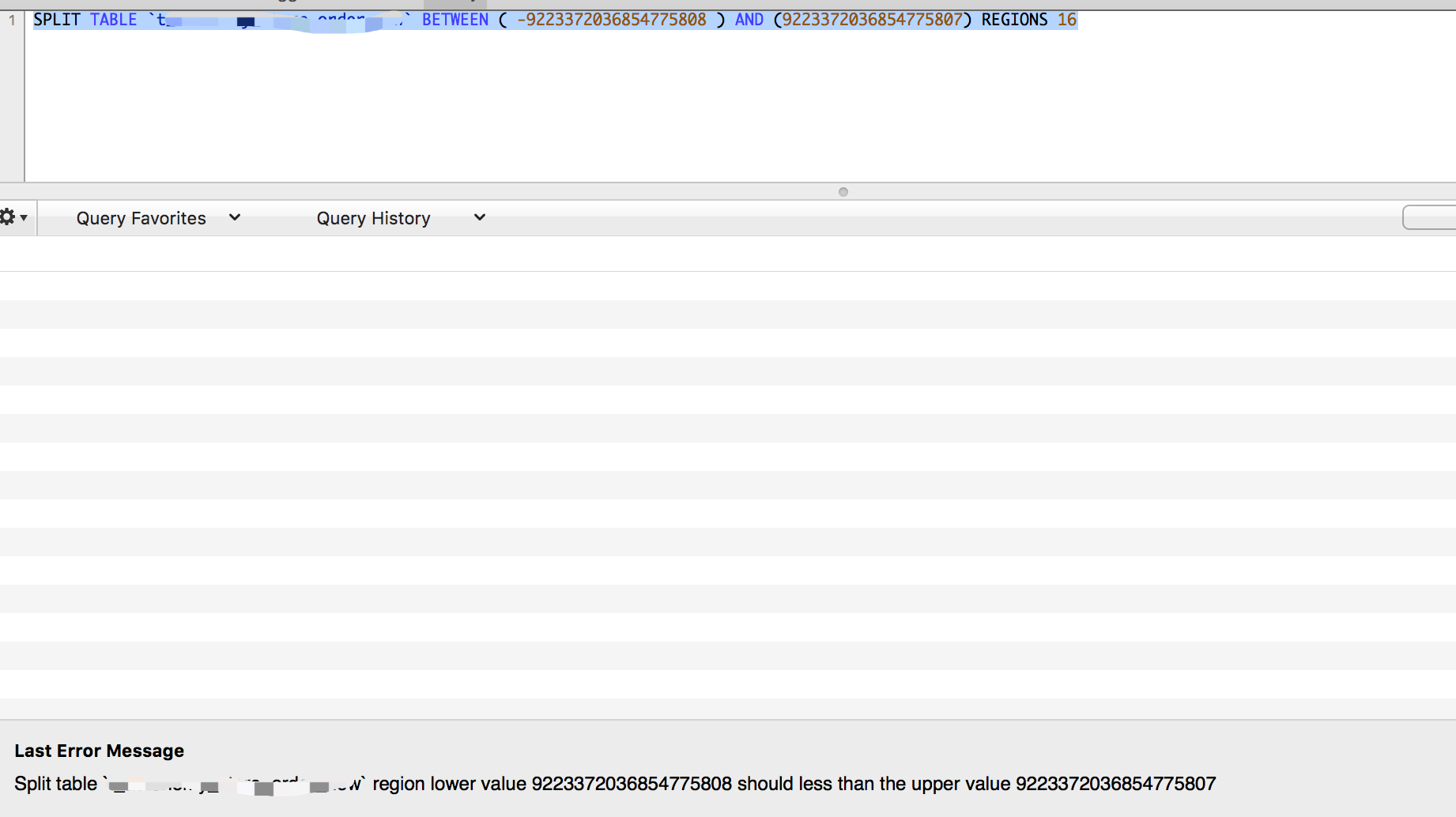
你在玩最大长度的上下边界么~ 
这明显就溢出了 
按照标准的方式,都会按照时间,或者业务类型,或者 连续key区间,来设定分区的模式
这样设定的话,查询可以按照分区来查,范围更小,效率会更高