为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】4.0.12
【问题描述】我们的case:
- 9台cdc机器,内存90G,64核,cdc只同步一张表。
- 实时任务,一直更新tidb,ops1k~3k,cdc很稳定
- daily job,ops大约8 9k,cdc也可以扛住
- weekly job,ops大约16k,观察下来,cdc性能不够。这个job负责刷新整张表,都是update操作,单条更新tidb,一般会跑两三天。
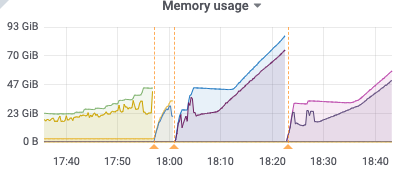
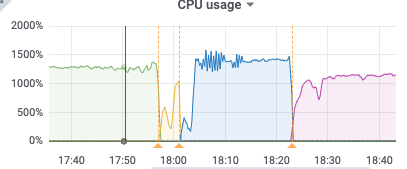
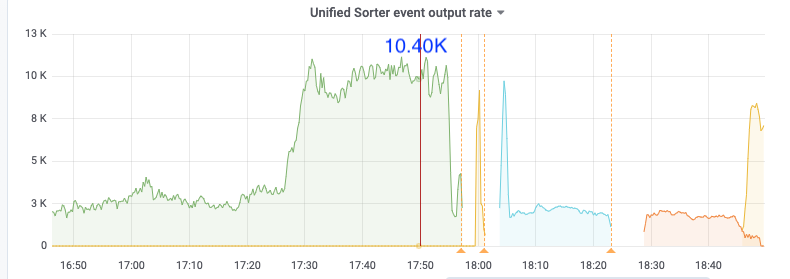
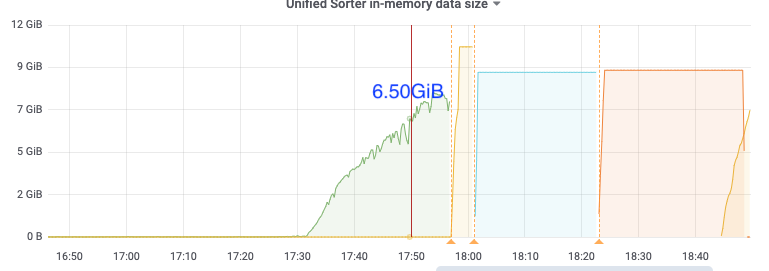
比如下面17:50分的metric,kv client、pull receive、pull out、sort input的速度都是14k/s,但sort output只有10k/s,sink也是10k/s,之后cdc开始频繁崩溃
17:50
kv client receive: 14k/s
puller in: 14k/s
puller out: 14k/s
sort in: 14k/s
sort out: 10.4k/s
sort memory: 6.5G
sink: 10k
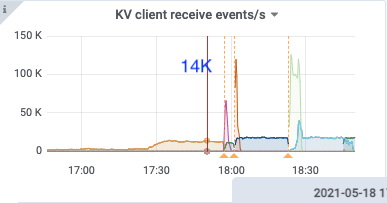
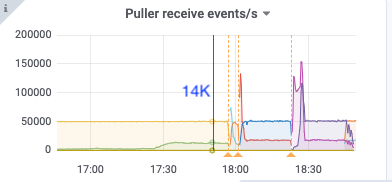
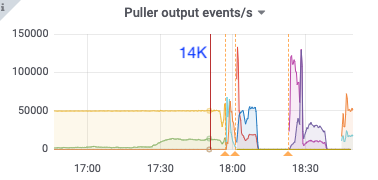
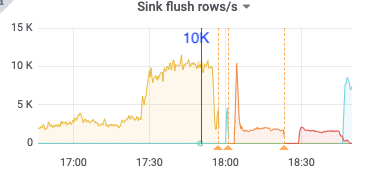
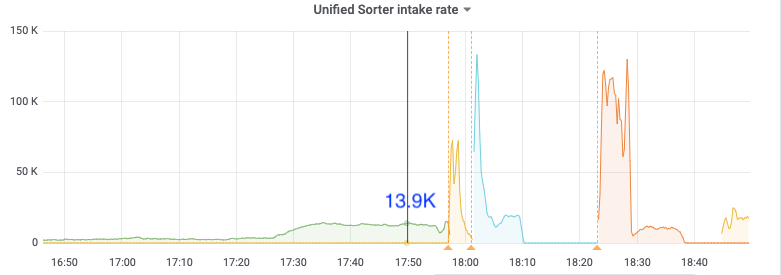
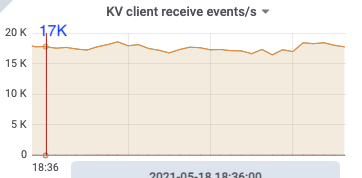
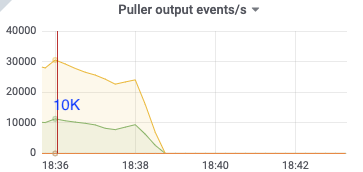
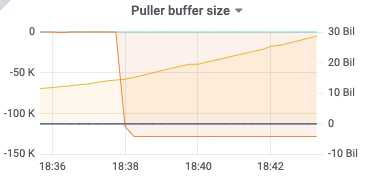
18:36
kv client receive: 17k/s
puller in: 17k/s
puller out: 10k/s
sort in: 10k/s


我自己也调整了一些参数,但是效果不佳:
defaultMemBufferCapacity:默认10G,改成了50G
sorter-num-workerpool-goroutine:默认16,改成了256
sorter-num-concurrent-worker:默认4,改成了32
sorter-max-memory-consumption:默认8G,改成了50G
请问还有哪些性能瓶颈?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。