
上面两种说法,麻烦再确认下哪种是正确的?
麻烦在 pd-ctl 中反馈下各个 store 的状态,以及 tikv_stderr.log 看下是否有信息,多谢。
抱歉 之前看错了 tidb集群的时间比真实时间慢12小时 而lightning机器的时间比真实时间慢约四个小时
集群已经清理掉又重新导入了,原来集群的store,tikv_stderr.log已经被覆盖了。
集群清理是因为我们的恢复数据需求较紧急,所以想尝试了一下重新导入,发现即便是在sync-log=true时又出现了sst丢失的问题,和https://asktug.com/t/topic/68165描述的情况一致,该贴的方法可以使kv恢复为up但却不能保证数据完整性,我们希望重新导入的数据是全部完整可用的。所以可能无法用此方法解决。
麻烦您看一下这个问题能否解决,我们这边先开始用backend方式导入了
这个 sync-log 如果是 false 不保证导入数据的可用性,如果 sync-log 为 true,我理解是没有问题的。
并且 FAQ 中的问题主要是在在线集群使用 lighting 导入数据,可能会造成 lightning 与 tikv 对导入结果的共识不一致情况,此时 lightning 认为导入 sst 错误会重新导入,tikv 认为导入成功会删除 对应 sst。最终导致 tikv panic。这块看了下 issue 是在 5.0 修复的,https://github.com/tikv/tikv/issues/9496
你这边着急的话先用 backend 模式导入吧
好的 非常感谢 主要是每次用local导入要等个好几小时才报错 试错成本有点大。
不好意思影响到你们这边数据导入进度。请问数据量大概有多少,backend 导入是否成功?
您好,用backend方式导入状况如下,运行了一晚上,总的来说应该不会报错,因为它是把语句一条条insert进去的

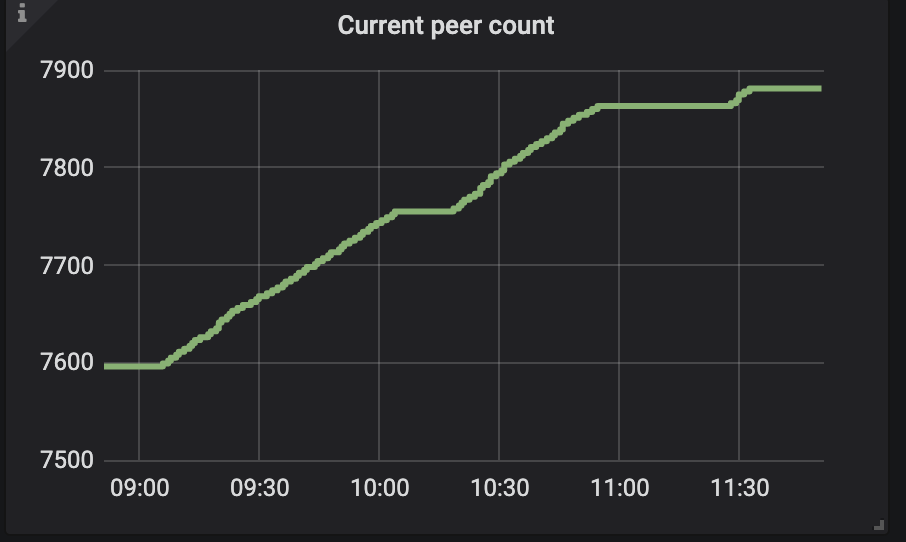
今天早上起来看了一下,如上图所示发现速度越来越慢,于是kill -2掉进程后重新执行了一下,大概速度如下图

我们的导入数据状况如图,共有9个库,总量大约2个多t

借此提一下几个问题:
1、从昨天晚上导入开始到今天早上这一过程速度越来越慢,这是正常的吗?
2、重新导入后速度没有快很多,但为何remaing显示时间差距会如此之大?
3、目前导入速度是否正常,backend导入模式有什么提速的方法吗?
lightning配置文件
tidb-lightning.toml (855 字节)
由于backend的速度实在是太慢了,关于local方法我还有如下几个问题
1、我们的机器没有ssd,您提到说local方法sst丢失的bug在5.0版本中解决了,我尝试建立5.0版本集群,但是报了https://asktug.com/t/topic/69762的错误,应该是磁盘类型的问题,这是否意味着我们现在无法建立5.0版本集群,也就无法解决lightning导入的sst文件缺失问题?
2、您提到说sync-log为true可以保证导入数据可用性,我能否理解为出了这个缺失sst的问题后用给的方法恢复能保证继续导入并且导入的数据都完好无缺?
lightning backend 模式是把语句 insert 插入到下游 tidb 中的。如果速度比较慢,可以看下下游 tidb duration 的延迟情况。下游 tidb 集群写入慢可以按照排查下瓶颈问题点。 TiDB 写入慢流程排查系列(一)— 前言
- 1.请问你们这边机器配置是什么样的,是否是使用的物理机,磁盘类型是什么?你上面提到的帖子问题是 磁盘故障了吧。
- 2.上面提到 5.0 具体使用的是哪个版本?
- 3.使用 5.0 导入报错是否是和 4.0.12 是相同的报错?目前 5.0 版本 sync-log 是代码中写死的,该参数为 true,不可修改了。
另外我看这边问题比较多,方便的话,建议填写下 “联系社区专家”,后台评估后看下是否可以快速反馈。
1、我们的机器是虚拟机,其中备份数据源和三个kv节点的存储路径都是通过华为云存储路径挂载的。
2、指的是使用 tiup cluster deploy tidb-test v5.0.0 topology.yaml --user root -p命令创建5.0版本的集群,创建成功后发现kv无法启动,查看日志报了 IO snooper is not started due to not compiling with BCC的错误
3、5.0版本的集群创建就没有成功。
关于联系社区专家,之前已经由Gangshen先生联系填写过了。

您好,我亲测是影响启动的,kv节点会down掉,集群起不来
内部确认了下,这个确实不会影响启动的,应该还有别的报错信息,如果跟上述帖子报错内容相同,该报错的第二个报错信息,那应该是盘有问题,建议检查下。
嗯,我当时是看到这一行报错就去社区搜索了,建立4.0.6版本的集群可以成功,5.0版本的会失败,应该是盘的问题。
现在我们的情况是,机器本身的存储不够容纳所有数据,因此存储路径必须通过网络挂载。现在已知local导入方式中的sst删除的bug在rc版本和5.0版本集群中被修复,但这两个集群部署要求必须将存储盘格式化为ext4,我想请问您以目前的状况我们是否还有办法使用local方式导入?
如果无法按照要求进行部署,那可能没办法进行下一步操作了。
你这块看起来用4.0导入时,该问题必现的对吧?
对,集群版本试过从4.0.6和4.0.12,lightning工具则试过4.0.6,4.0.12, 5.0.1三个版本,sst缺失问题必现
- 这个问题有没有看过集群的配置?tikv 空间是多大? 上面 IO snooper 的报错有可能是空间不足了。
- 要导入的数据量有多大?
- 如果测试导入少量数据是否报错?
1、集群配置为最小拓扑架构,tikv存储空间是足够的
2、要导入的数据量总共1.6T
3、该问题不定期出现,每次都要通过重新执行lightning命令才能继续跑