为什么 region 持续增长? 分析如下:
-
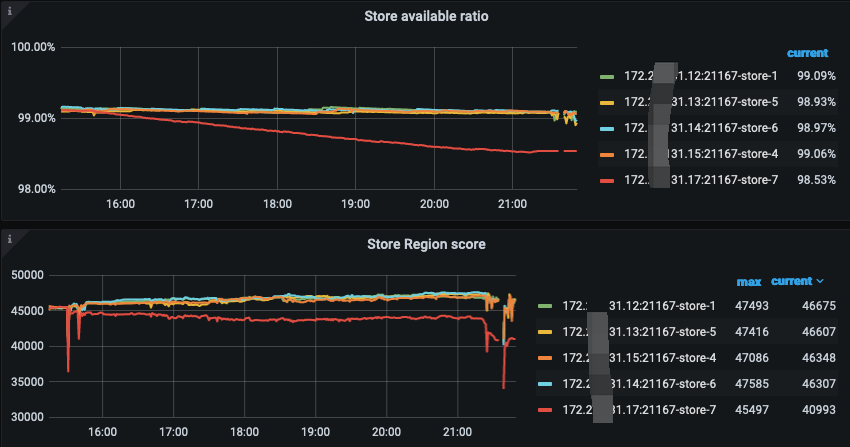
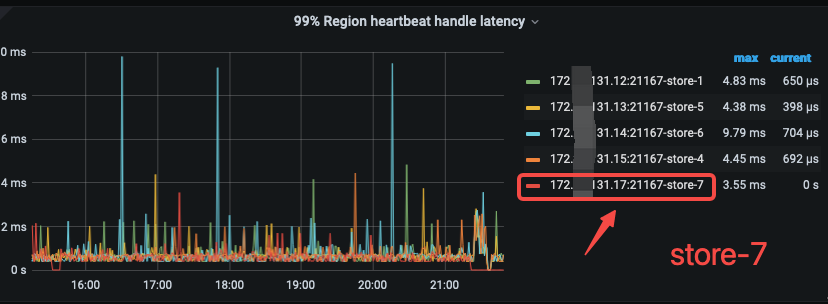
从这个面板我们能看到 出问题的解节点是 store-7
-
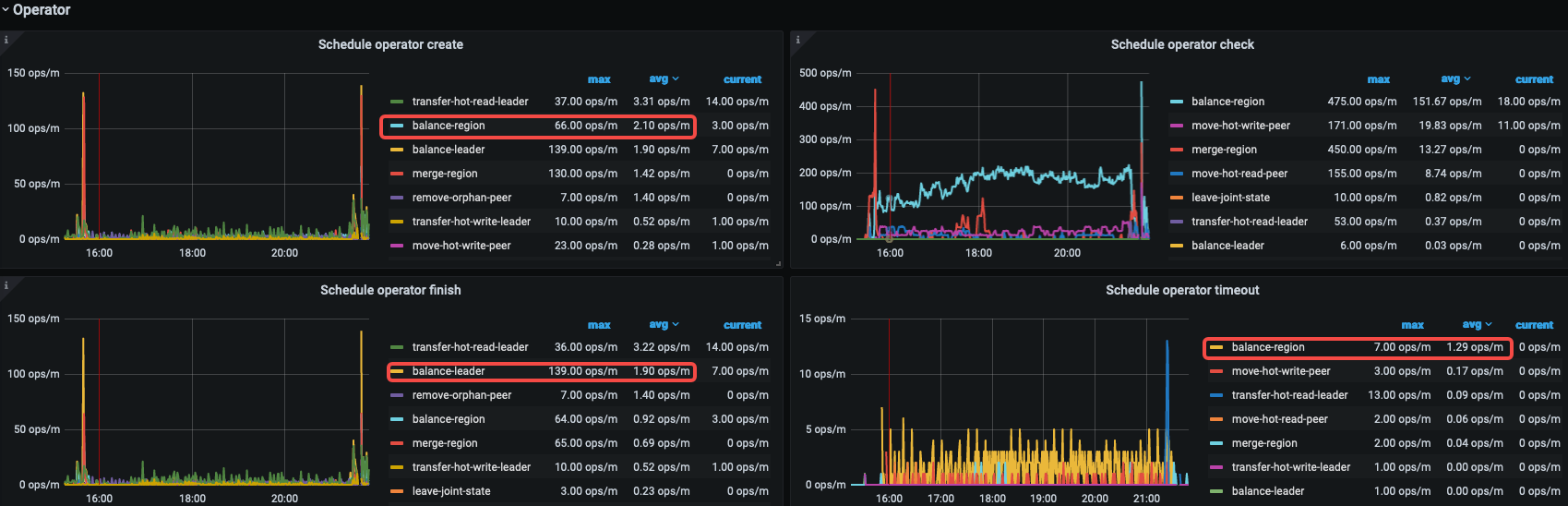
从 PD Operator 看 PD 发起的比较耗资源的就是 balance-region 面板,avg 2.1 ops/m create,avg 0.9 ops/m finish,avg 1.29 ops/m timeout,这说明 balance-region operator 失败存在积压。
-
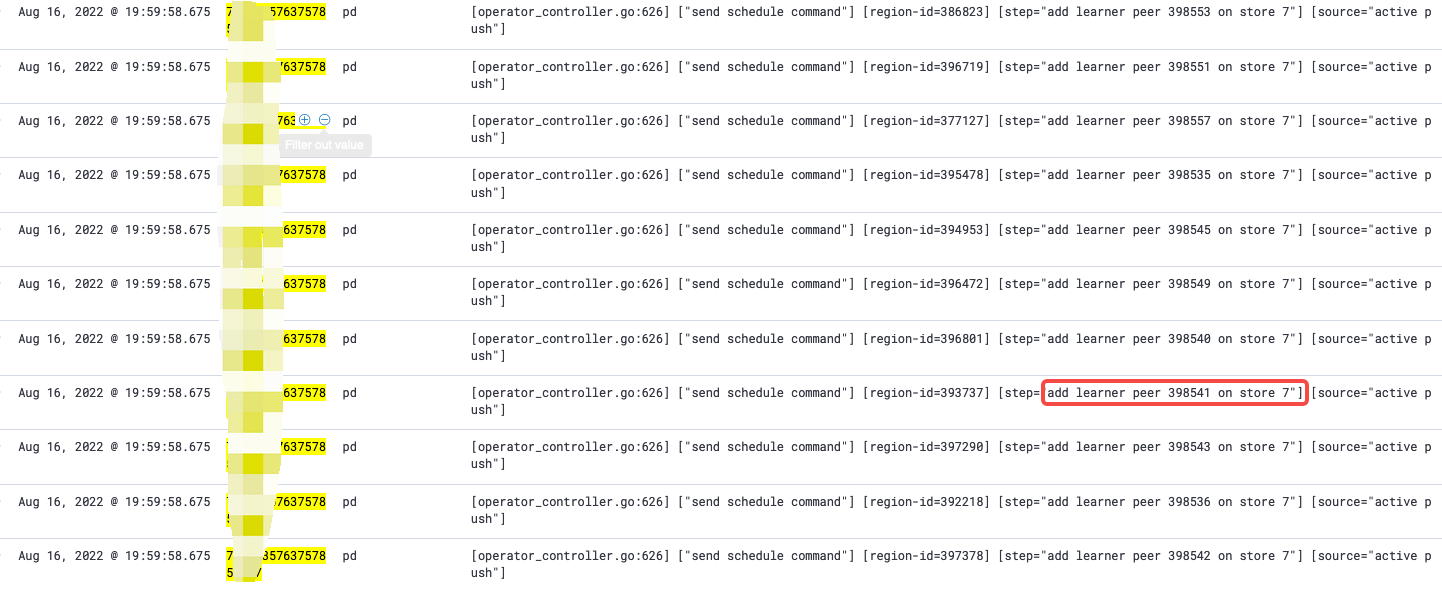
如果查看 PD 日志会发现通篇大量 add peer to store 7(有问题的 store)
-
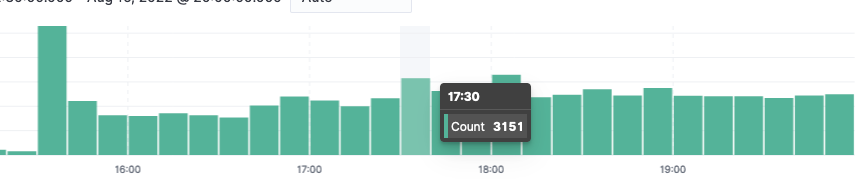
从该日志数量上看,add peer 日志非常多,其中应该包含 timeout
-
但是从 pd_scheduler_store_status 算出来的 store region count 实际是在减小的,也就是 PD 感知到的 region 是在减少的。
-
而 tikv_raftstore_region_count 算出来的 store region count 确是增加的,表示的是 tikv 在 region_collector 中感知到的 store region count 是增加的。

综上,pd 感知到 tikv region 数在减少,并疯狂往 store 7 补 peer,补到 tikv 处理不过来。
原理:
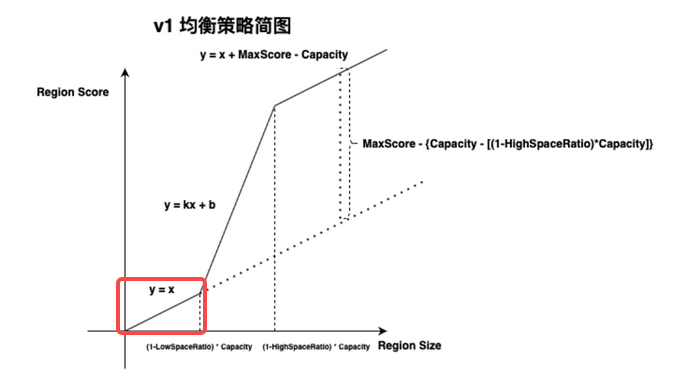
在消耗磁盘空间较小的情况下,region size 近乎等于 region score ,from–>专栏 - 加载中 | TiDB 社区
也就是说,可能因为 store down 的那几分钟(region 的 raft 变更落后了,或者因为什么其他原因,因无日志便无法追溯了)导致 pd 感知到的 region 变少,进而降低 region score。 PD 调度的原理是把 score 从大变小,而现在 store 7 最小,其他 store 的 region 就疯狂的往 store 7 上转移,直至打到 server is busy.