【 TiDB 使用环境】线上
【 TiDB 版本】5.0.6
【遇到的问题】大量的truncate命令夯住,pd节点oom
【复现路径】做过哪些操作出现的问题
ETL任务中的TRUNCATE任务执行慢,导致任务一直堆积。
【问题现象及影响】



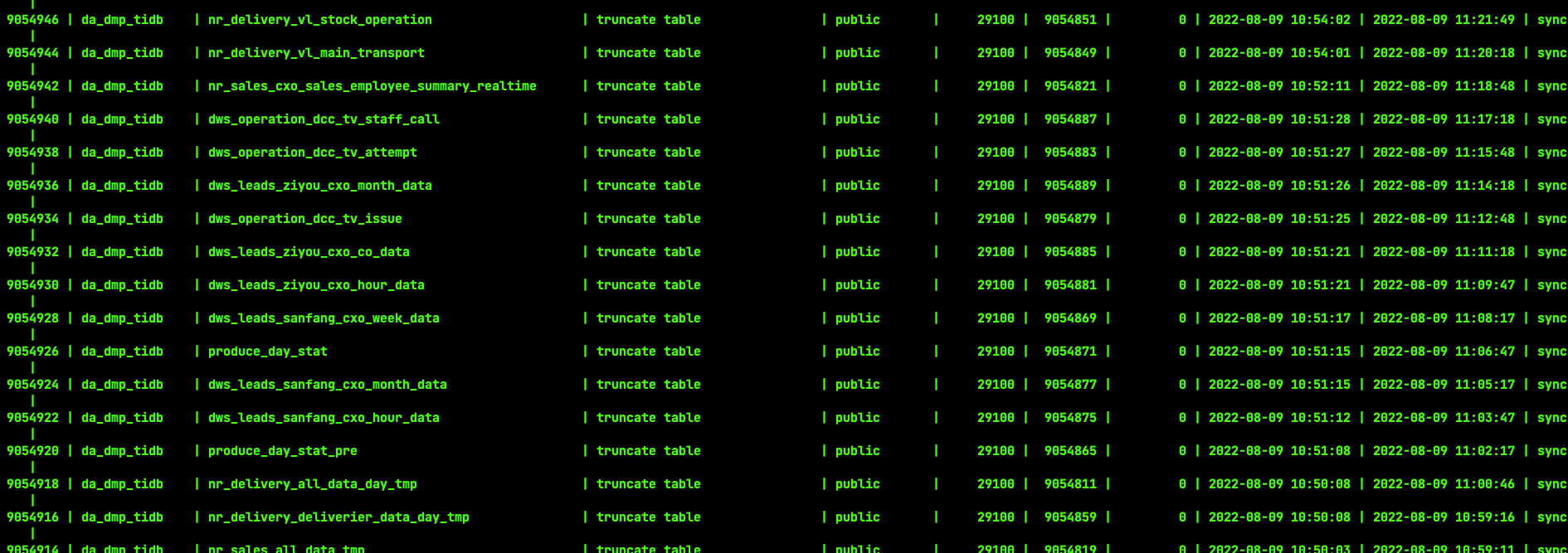
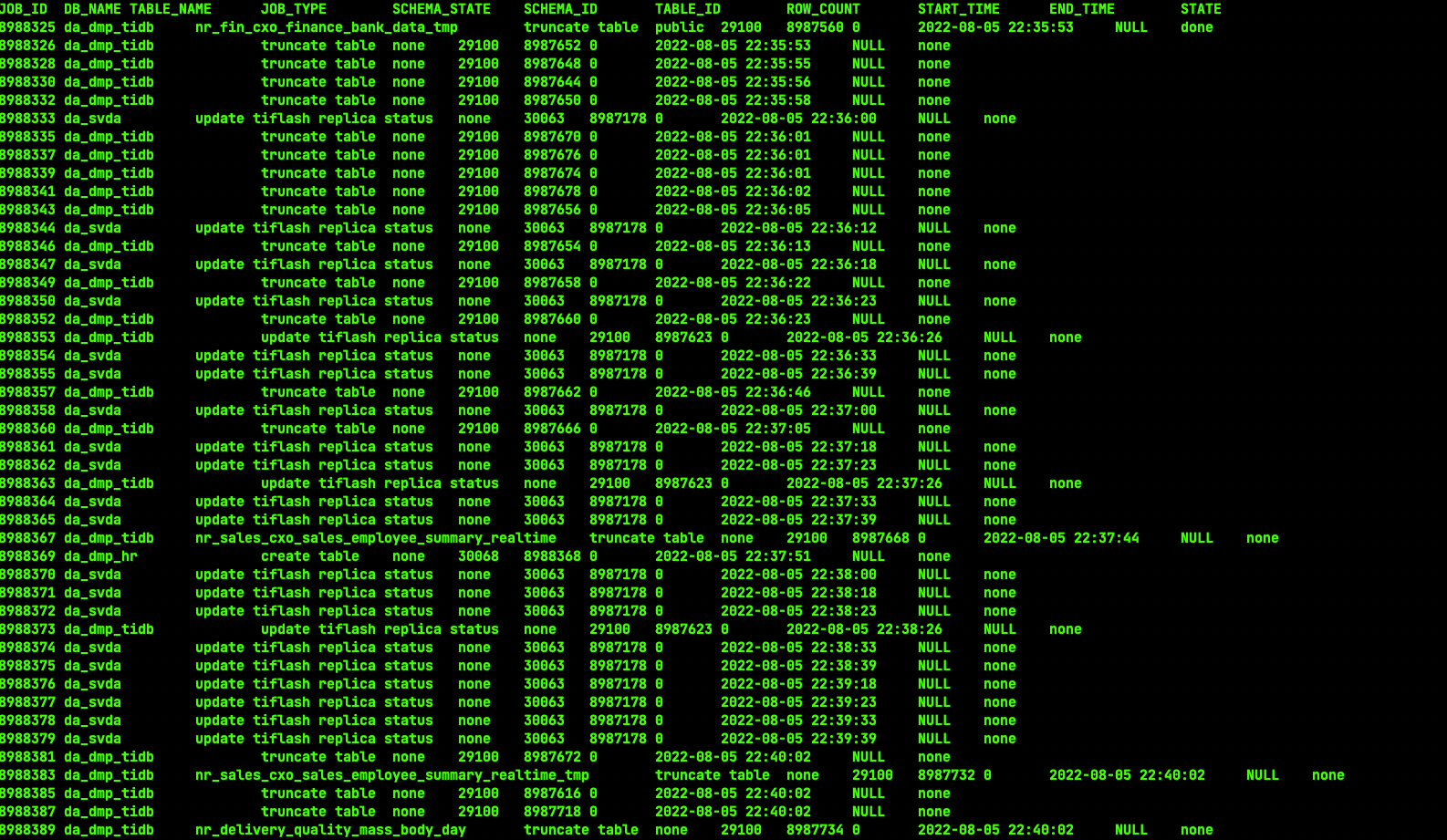
当时hang住的ddl和下图一样 ,只是时间点不一样
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
【 TiDB 使用环境】线上
【 TiDB 版本】5.0.6
【遇到的问题】大量的truncate命令夯住,pd节点oom
【复现路径】做过哪些操作出现的问题
ETL任务中的TRUNCATE任务执行慢,导致任务一直堆积。
【问题现象及影响】
当时hang住的ddl和下图一样 ,只是时间点不一样
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
先上集群信息,以及相关的配置信息
然后描述下是哪些节点出现了什么问题,最终导致了 PD 出现问题?
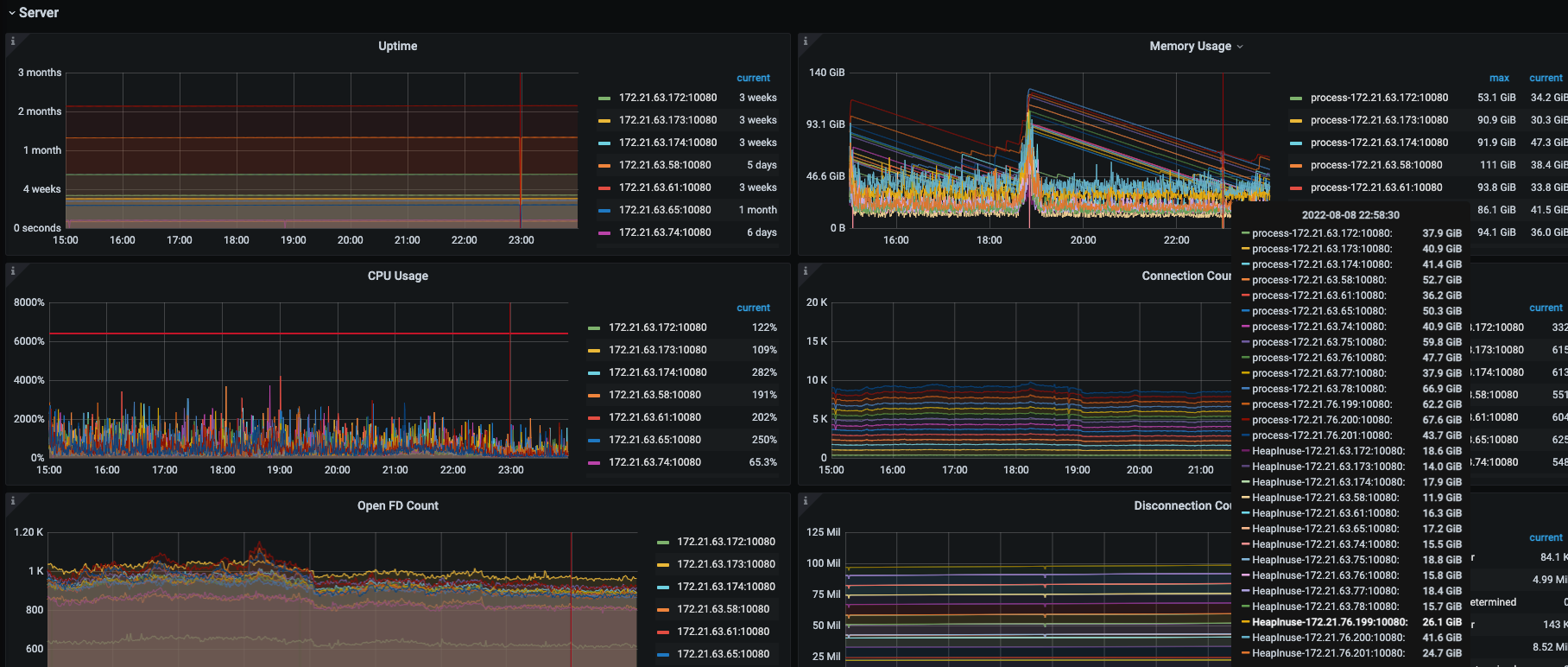
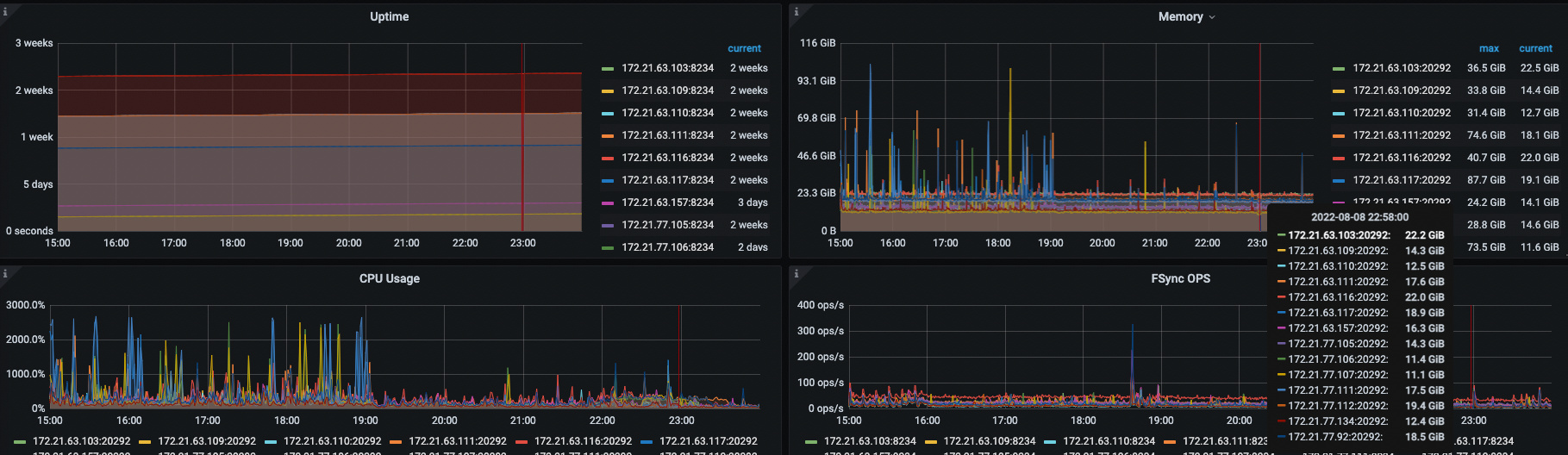
3PD节点 64c128g. 14TiDB节点 64c128g 17TiKV节点 64c64g 14TiFlash节点 64c64g
业务反馈ETL定时任务卡住,任务先做truncate,再做插入。 admin show ddl jobs看几百个truncate和update tiflash replica status状态
TiDB、TiKV、TiFlash节点CPU 内存监控看着没太大问题
truncate 是异步执行的,如果truncate没完成,就执行了插入,是否影响业务层面的逻辑要求?
看你的集群超大,那么 region 数量是否也是超大? 分布是否均匀?
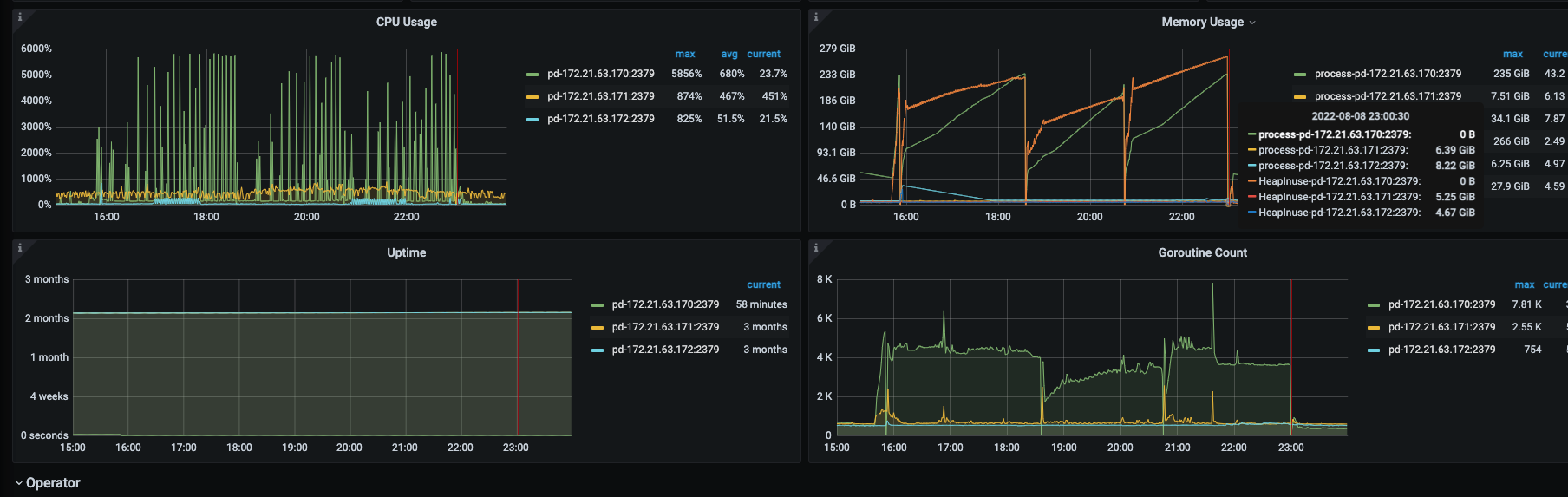
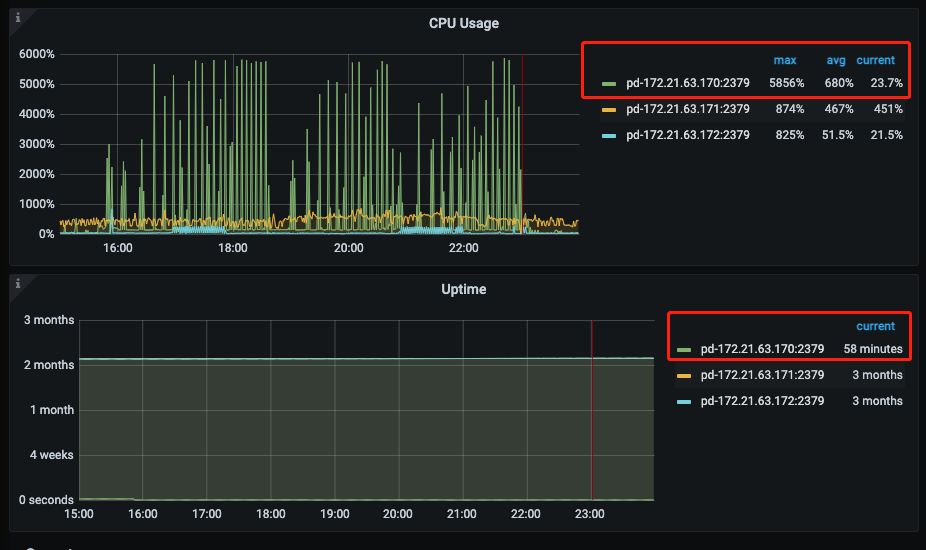
主 PD 存在高压的情况,查阅一下 empty region 是否也很多?(好像重启没多久)
1、业务层面也在改,现在是不知道为什么truncate会这么慢,虽然是异步,但是也是很快能执行完的。正常情况下的表都是秒级别。是因为truncate慢导致后续任务重试出问题了;
2、region 100W+ 目前看是均衡的;
3、里面的监控图都是8月8日15:00—23:59:59 pd节点在16:00—23:30之间重启了4次。
现在想知道truncate为啥会慢,pd为啥会内存飙升
truncate 的处理是由 tidb 来执行的,因为是异步的,需要经过 N 比对状态才能执行成功,至于快慢要查每个执行 job 的状态和记录了
Region 数量很大的时候,就会造成 PD 很重的负担,因为 每个Region 都需要上报自己的心跳和一些信息;建议参考下 海量Region 优化方案,优化一下
Empty Region 也会发送心跳和信息,建议进行快速合并
内存飙升,需要通过 手动收集数据进行分析了
https://docs.pingcap.com/zh/tidb/stable/dashboard-profiling
生成火焰图应该能很快识别的
1、怎么查记录,admin show ddl jobs有时间,有很多就要执行5分钟甚至20分钟;
2和3、这个集群目前刚接手,也打算做这块
是不是表中的数据量特别大?然后 KV 节点的 IO 有没有什么异常?
DDL 的处理确实很慢了
建议按照下面的几点进行对照排查
show variable like ‘tidb_scatter_region’ 看看这个参数