我
我是一个非常有重量的人,买衣服只买迪卡侬,是因为迪卡侬的号大。我曾经崇拜过一个技术大拿,很牛的那种,体重比我还大,所以我很释然,也觉得做技术也许体重大是标配。我是个老头,在社区里面,很自信的说,我的年龄数一数二的大。我也接触过非常多的东西,我曾经搞过ITIL、写过Flex、做过平台架构规划、研究过前端,甚至于现学现卖SEO。最近几年踏踏实实的研究数据,搞搞架构,从Hadoop入门,一直在折腾Spark。
起于2019年的那个夏天
19年我司委托我一个任务,找一个数据库,能够承担起历史数据明细查询,要求有多少数据装多少数据,以较高的并发,以及用户能够忍受的时间(3秒)返回。当时团队里面有个老大哥,对比了几个数据库,有Citus、YugaByteDB、TiDB等等,TiDB是最早开始测试,也是最早放弃的,早期的TiDB部署环境时有个check,会要求磁盘的iops大于1W(randread iops of tikv_data_dir disk is too low: 8207 < 10000),达不到要求就不能安装,我们的破烂开发机,有1K就不错了,然后测试TiDB这事就无疾而终。论坛里面有相似的问答:https://asktug.com/t/topic/2120 。虽然Citus、YugaByteDB,甚至Cassandra都有过充分的测试、争论,但也因为种种原因没有上线。
召必回,战必胜
21年,我又对TiDB做了一些研究,原来的期望是找一套云原生,兼容Spark计算的数仓View层的数据库,当时期望的架构如下:
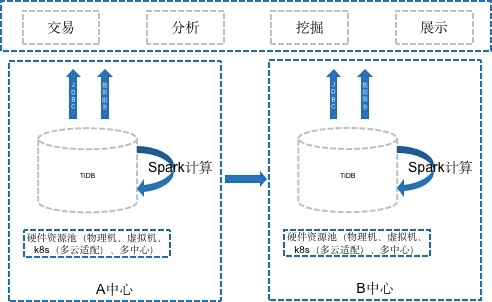
但是那一年,我们干了个奇葩事,遇到了一个很难解决的问题。
我们用大数据Hadoop这一套开始给客户算账,地球上绝对有很多人干这事,但是像我们人又少,技术又烂的团队干这事很少。然后我们就遇到了月初月末算账不准的问题。整个同步的链路很长,如下图:

我们研究了两个周,备受折磨,我就想搭建另外一个同步链路,同步数据后作对比,期望发现问题。或者说如果新搭建的同步链路稳定,直接采信新的同步链路的数据。
由于TiDB完全兼容Mysql生态,而且我们集群里面有Otter,于是我有个大胆的想法,用TiDB搭建另外一个数据同步链路,用Spark同步TiDB的数据到大数据产品中进行计算,于是同步链路变成了这样:
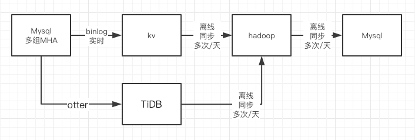
新的同步链路,从搭建生产环境,到能够正式处理数据,仅用三天时间。新链路上线后,采用两条链路互补的方式,计算账单,数据再没出过问题。经过两周的跟踪,也逐步发现了以前环境的问题,修正问题后,TiDB的同步链路完成使命。
详情:https://tidb.net/blog/55a8baf9
最接近生产的一次
22年我逐步走进了社区。在公司内部也做了一些培训,搭建了一个测试环境。由于我的布局,我们另外一个团队在需要解决saiku产品的底层查询问题时,想到了TiDB,于是做了一些测试。从结果来看,TiDB比环境里面的其他数据库,更适应saiku的查询方式。于是我们打算在生产上线TiDB,用于解决很多我们生产环境需要解决的问题,不单单是saiku,还有需要分布式关系型数据库的很多地方。但,又双叒叕因为外部环境因素,我们最终部署了Doris,毕竟测试saiku在Doris上有更好的表现。在这个过程中,我们发现了一些问题,因此提了在tidb的第一个issue,并在新版本中得到修复:
https://github.com/pingcap/tidb/issues/32626

详情:https://tidb.net/blog/de9bf174
生命不息,折腾不止
随着年龄增大,越来越认识到知识储备的重要性。汲取知识的重要方式是深度参与社区。
于是,我就:

于是,我就:

于是,我就:

还有以下,懂得都懂,hhhhhhhhh:

最后,感谢贵司,让我圆了一个分布式数据库的梦。