完整的 query-status 结果看一下,worker 是正常的吗?
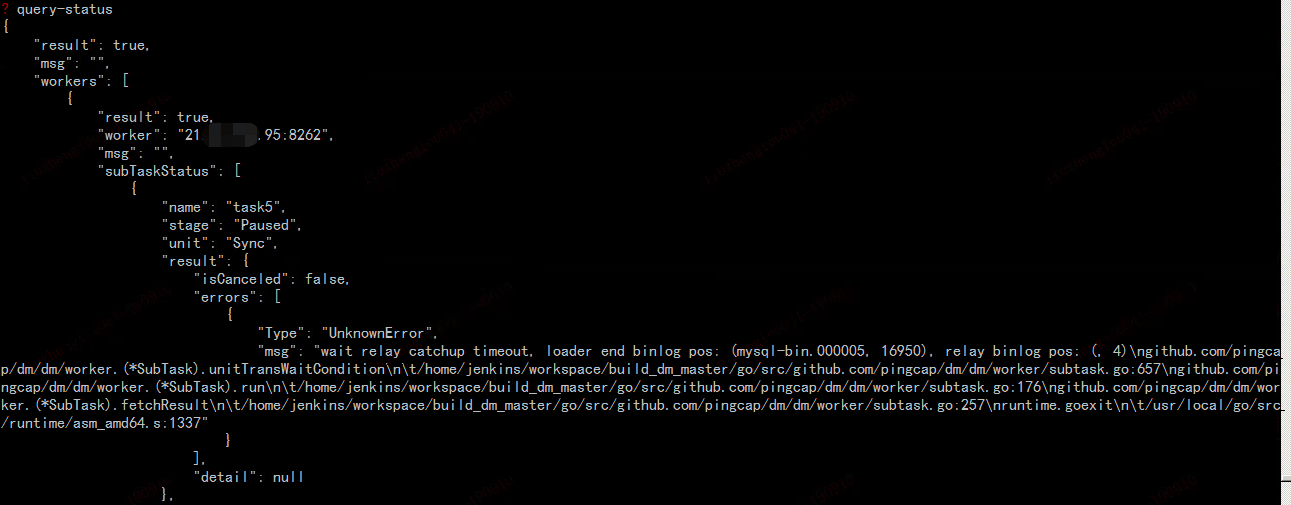
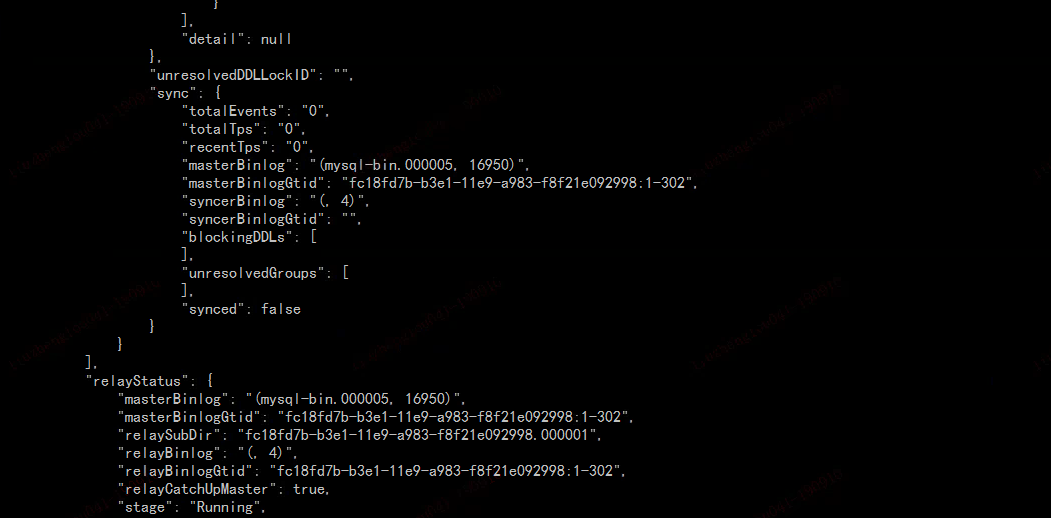
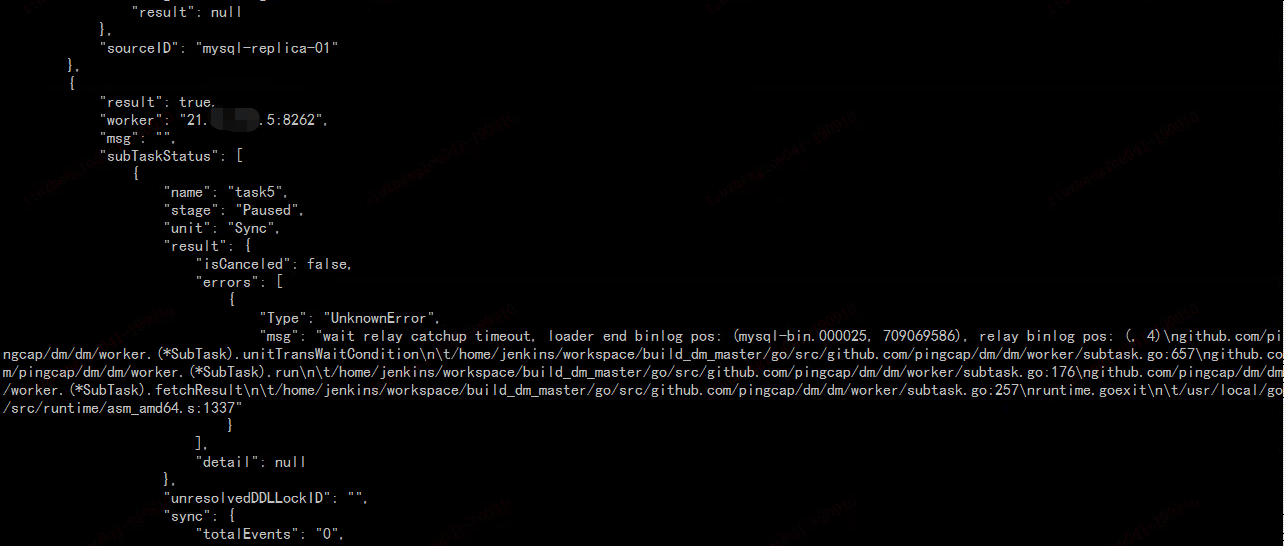
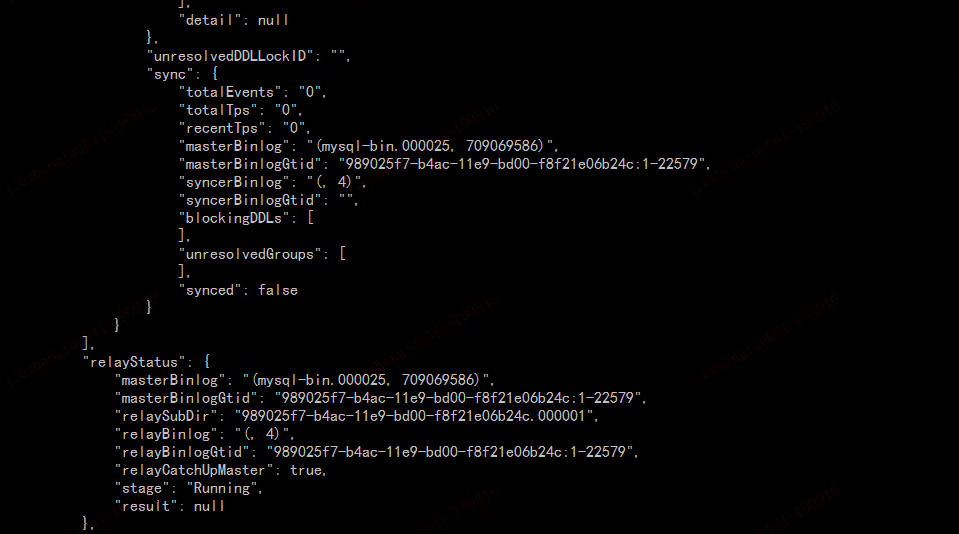
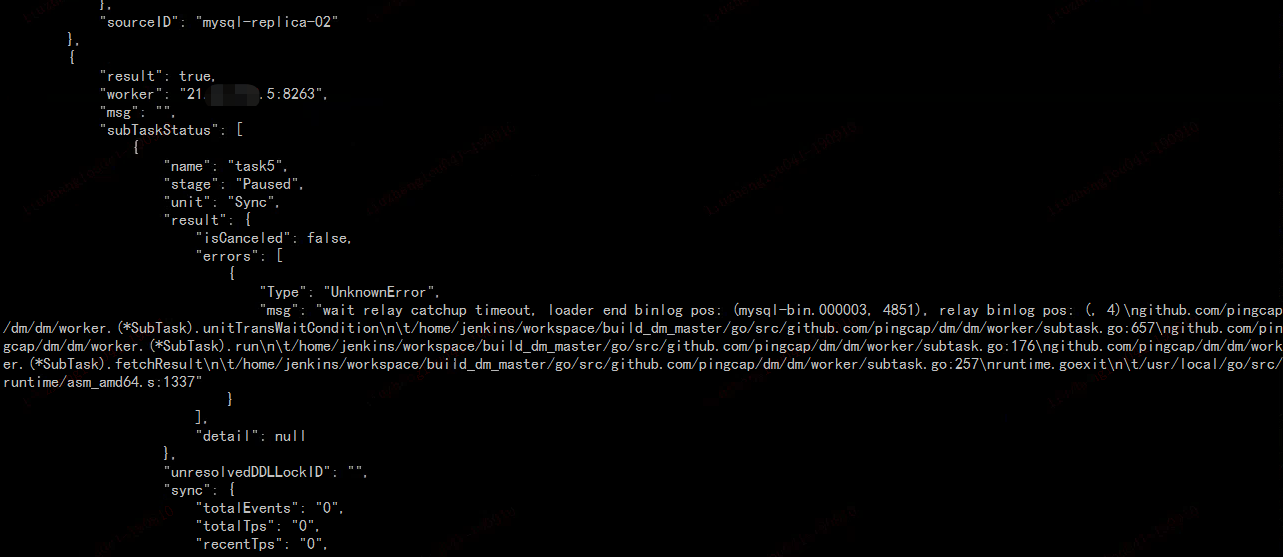
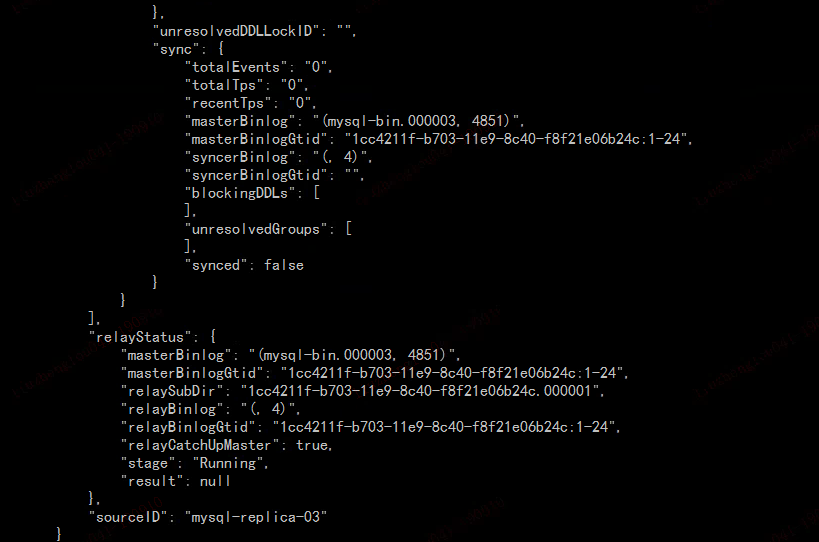
这个不是新部署的吗? 看状态是 paused 的,这个是做了什么操作? 另外重新部署的话,把之前产生的 relay log 删掉
是新部署的啊,部署完之后,就启动了,然后loader阶段没有问题,到sync阶段就报错了,上面的沟通记录里面都有截图,我新部署之前都是unsafe_clean命令,所有dm-worker和dm-master上面的目录都是删除掉的,所以relay-log 目录都没有的。
现在报错说relay-log的问题,但是我手动把dm-worker里面的relay-log修改成源端的binlog位置,resume-relay还是显示成 binlog-name = “” binlog-pos = 4 binlog-gtid = “”
relay log 的目录里面能看到文件吗?
三个dm-worker对应的relay-log目录都有query-status上面提示的binlog文件,其中一个worker的截图如下:
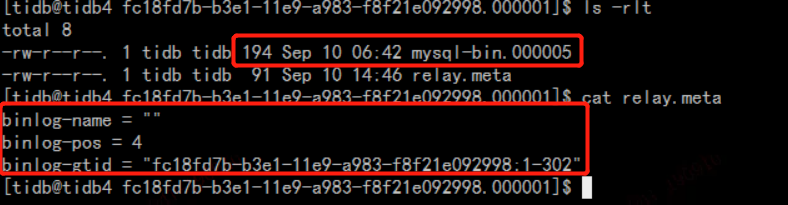
出现这种情况,是不是我哪里配置有问题吗?既然loader阶段正常了,那卡在sync阶段,可以从哪些方面找原因呢?我已经unsafe_clean 两遍了
在对应的 mysql 库里 show slave status 有什么异常吗?
修改 relay.meta 的时候,需要停掉 worker, 再修改,然后再启动 worker
AnyUpdate ?
“修改 relay.meta 的时候,需要停掉 worker, 再修改,然后再启动 worker”
那个时候worker的状态都是pause的,还需要停吗?而且我并不想手动修改relay.meta 文件,我就好奇为啥会自动更新成空了
在源端的MySQL库上执行slave status没有返回,但是slave hosts有结果
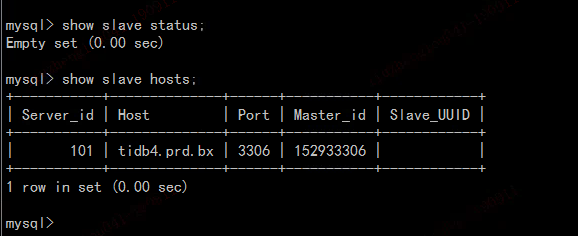
- pause 和 stop 是两个概念,pasue 在修改 task 任务时候是可行的,但是修改 relay.meta 不可以的,涉及到 checkpiont 点;
- 如果已经出现 relay log 不一致的情况,出现断点,就需要重制。
噢,我想我已经找到原因了,我源端有三个MySQL实例,第一个的sql_mode跟tidb的一致,另外两个sql_mode 不太一样,不管怎么修改relay.meta或重新部署dm cluster,都会出现前面描述的那种错误,我刚才只同步了第一个MySQL,发现没有问题了
但是我还有一个疑问,我三个单独的worker,后面两个就算有问题,为啥会影响到第一个worker也不能正常同步?你们可以帮忙验证下,谢谢
是启动 dm-worker 时候?还是执行 task 时候 ?
启动dm-worker没有问题,start-task 的时候报错
分库分表场景要保证数据写入的一致性,这里执行 task 任务中配置了上游 3 个 MySQL 实例分别通过 3 个 dm-worker 来完成合库合表,如果 task 任务报错,那么任务里面的订阅操作都会暂停。
单独拉起独立的 task,只涉及这个 dm-worker 的操作吗 ?
嗯,是的,另外两个dm-worker的内容在task.yaml文件中都删掉了
task 性质已经变化,所以可以的,也是预期的。可以在公众号或者博客找一些 DM 原理文章,相信你会对这些地方就有新的认识。