作者:王军、苏立
Parser 基本原理
什么是 TiDB Parser
TiDB Parser一般是做两件事:
- 检查关键字的正确语法和拼写
- 将文本解析为 AST (抽象语法树)
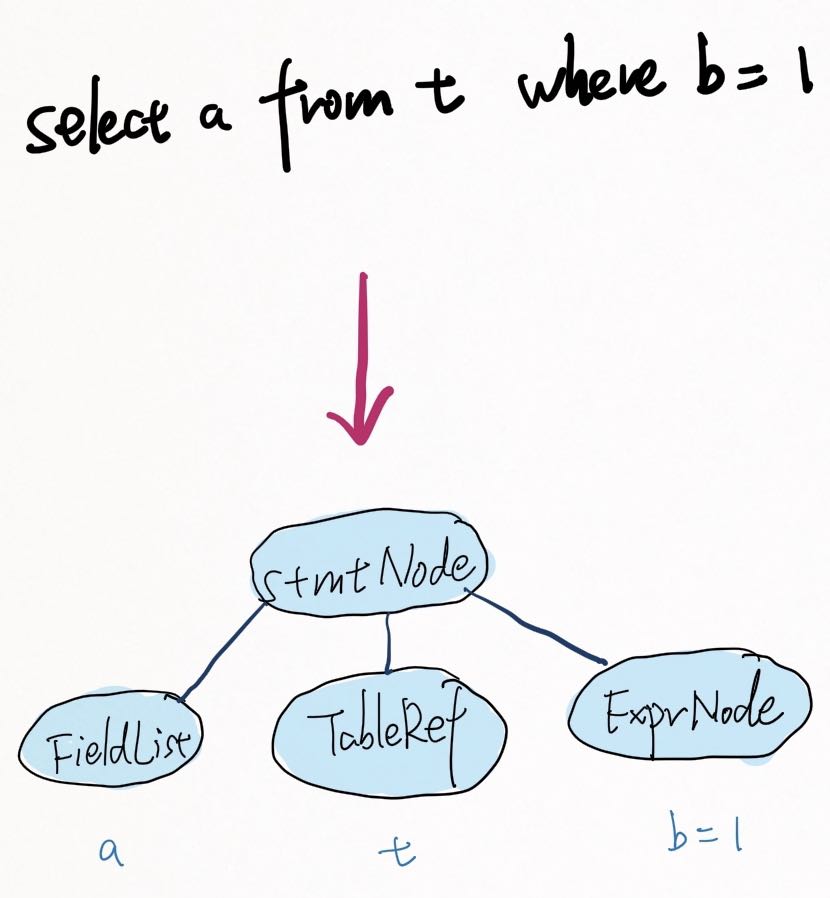
收到 SQL 之后,Parser 在完成语法校验后将 SQL 文本转换类似上图的语法树,之后 Planner 根据语法树来做 Plan。
Parser 的基本组件
TiDB Parser 主要有两个组件:
- Lexer: 将文本转换为 Token 序列
- Parser: 消费 Token 序列,检查语法并构建 AST
Lexer 实际是一个词法分析的组件,主要是将一个 SQL 做分词,每个 Token 都有自己的值和Token 类型,比如下图中 “select” 就是一个关键字 Token, “a” 是标识符 Token…SQL 文本在通过 Lexer 后转化成一个 Token 序列。
Parser 持续消费 Lexer 产生的 Token 序列, 并根据 BNF 定义的语法上下文校验语法并构建语法树。
比如以上图的语法树为例,这个 select 语句为会转换为一颗以 stmtNode 为根节点,fieldList(select 字段), tableRef(from 后的表), exprNode(where 条件) 为子节点的语法树.
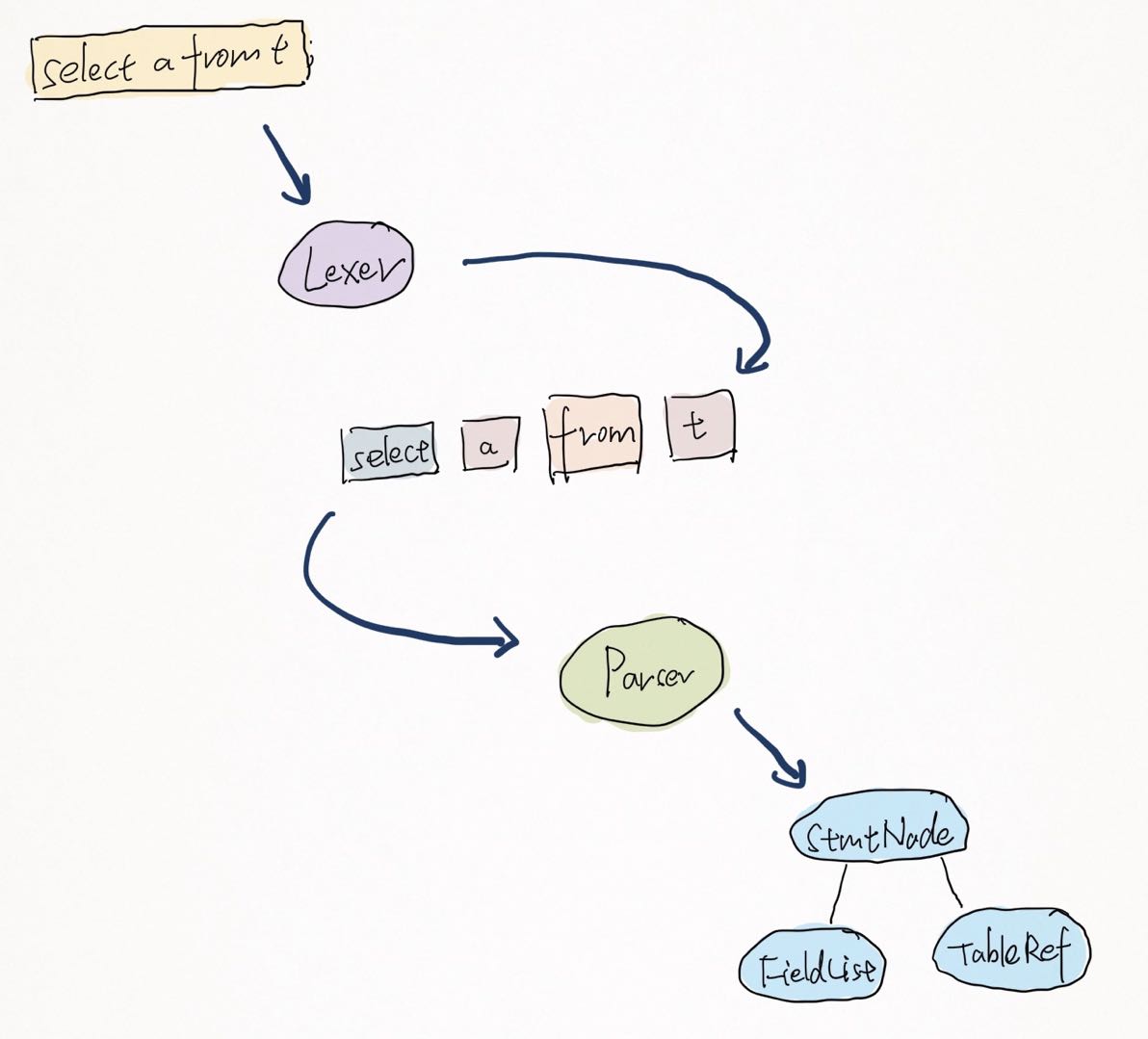
TiDB Parser
编写 Parser
经典的方法
- 传统方法:Flex/BISON, JavaCC, Antlr…
- 手工编写
TiDB 的选择
-
手写 Parser:Lexer .go 文件
-
解析器使用 goyacc 做语义分析
-
yacc用Go写
-
goyacc 的文档较少,推荐 Bison doc
Goyacc
-
Goyacc 从 BNF 中生成解析器代码
-
如何使用:
-
在 http://github.com/pingcap/parser/parser.y 中编辑 BNF 文件
-
运行 “Make” 生成 parser.go
-
如果想了解更多信息,推荐去看 Bison doc
BNF
-
全名:Backus-Naur From
-
一种描述语言的正式数学方法:
-
一组终端符号
-
一组非终端符号
-
表单的一组生成规则
-
其中LHS为非终端符号,RHS为符号序列。
-
示例:https://github.com/pingcap/parser/blob/master/parser.y#L6520
TiDB Hint
- 在旧的 TiDB(小于 2.1.3 版本) 中对优化提示进行了严格的语法检查
- 对于我们不支持的 hint 语法类型,会报错。为了兼容一些老版本的连接数据库工具,我们对于 hint 优化提示,以前的 error 改为了 warning
- 如果遇到类似 Hint 不支持的报错,升级到 2.1.3+ 可以解决这个问题
Parser 相关问题处理
报错信息解读
-
MySQL client 报错内容:“ERROR 1064 (42000): You hava an error in your SQL syntax;…”
-
说明:如果有这个报错,可以明确确认是 Parser 报错
-
语法报错 log 日志内容:“parser error” and with stack “(Parser).Parse”
Parser 报错判断
-
查看错误消息或日志,是否有报错码 1064 等。
-
在 MySQL 中是否可以执行: MySQL 5.7 语法
-
判断 TiDB 是否支持,可以看 parser 文件,来确认 TiDB 已经支持的语法
-
检查MySQL的定义
-
当发现语法是 TiDB 支持,如果有报错,可以判断为非预期,需要修复
-
当发现语法是 TiDB 不支持,但是 MySQL 支持,可以向我们提需求做兼容
性能
-
判断解析器是否成为瓶颈
-
监控中参考:tidb_session_parse_duration_seconds_bucket
-
获取 pprof 抓取火焰图,并查看“parser”。
-
优化
-
使用prepare语句遍历解析器阶段
-
简化SQL语句 (如,太多的’ ifnull() '表达式)