为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
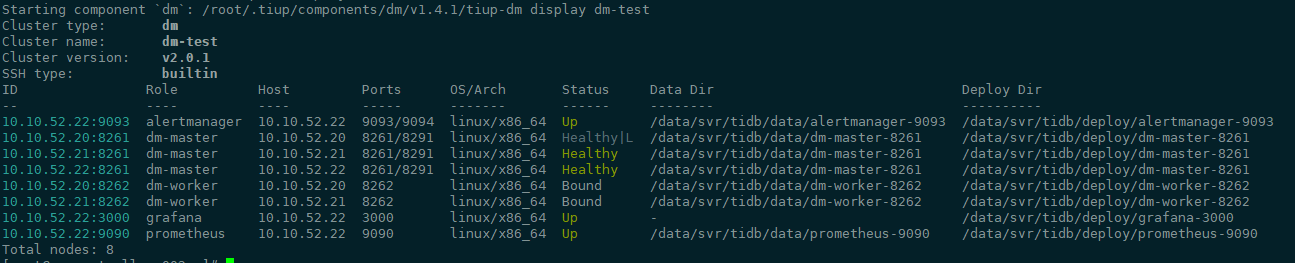
TIDB v5.0.0
DM v2.0.2
【问题描述】
DM 全量加增量迁移全库,大概4G的测试环境库,从00:07:00运行到04:53:00 结束了。发现未完全成功,迹象如下:
- 发现有些大记录表记录未完全迁移,比如500w的只迁移了300w
- query-status task显示如下错:code=40070 Message: no mysql source is being handled in the worker
{
"result": true,
"msg": "",
"sources": [
{
"result": false,
"msg": "[code=40070:class=dm-worker:scope=internal:level=high], Message: no mysql source is being handled in the worker",
"sourceStatus": {
"source": "staging-mysql-slave-replica",
"worker": "dm-10.10.52.21-8262",
"result": {
"isCanceled": false,
"errors": [
{
"ErrCode": 50000,
"ErrClass": "not-set",
"ErrScope": "not-set",
"ErrLevel": "high",
"Message": "context deadline exceeded",
"RawCause": "",
"Workaround": ""
}
],
"detail": null
},
"relayStatus": null
},
"subTaskStatus": [
]
}
]
}
- 上游mysql数据源是正常的,都可以访问和操作。operate-source show显示数据源结果如下:
Starting component `dmctl`: /root/.tiup/components/dmctl/v2.0.2/dmctl/dmctl --master-addr 10.10.52.20:8261 operate-source show
{
"result": true,
"msg": "",
"sources": [
{
"result": true,
"msg": "",
"source": "dev-a-mysql-slave-replica",
"worker": "dm-10.10.52.20-8262"
},
{
"result": false,
"msg": "[code=38032:class=dm-master:scope=internal:level=high], Message: some error occurs in dm-worker: ErrCode:50000 ErrClass:\"not-set\" ErrScope:\"not-set\" ErrLevel:\"high\" Message:\"context deadline exceeded\" , Workaround: Please execute `query-status` to check status.",
"source": "staging-mysql-slave-replica",
"worker": "dm-10.10.52.21-8262"
}
]
}
后面我尝试resume-task想继续任务,报
{
"op": "Resume",
"result": false,
"msg": "task /data/conf/tidb/dm/saofu-staging.yaml has no source or not exist, please check the task name and status",
"sources": [
]
}
又尝试stop,再start task,报
{
"result": true,
"msg": "",
"sources": [
{
"result": false,
"msg": "[code=38045:class=dm-master:scope=internal:level=medium], Message: fail to get expected result",
"source": "staging-mysql-slave-replica",
"worker": "dm-10.10.52.21-8262"
}
]
}
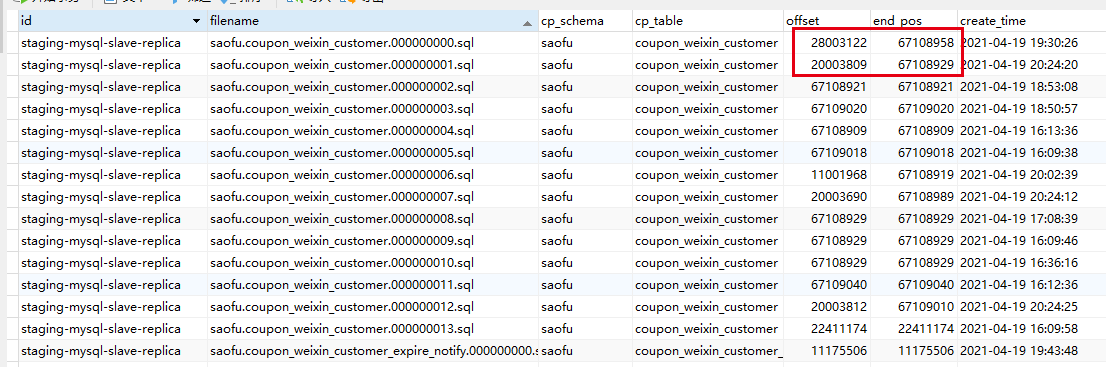
另外dm_meta表里,syncer_checkpoint没记录,loader_checkpoint有记录,截图中是1张500w的大表(最终下游比上游漏了记录),红圈处不知道是否是异常情况
所以现在会是什么问题? 要怎么处理呢?