为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】v3.0.5
【问题描述】
因为是测试环境,我把 tipd 与 几个监控组件都部署在一起了。
扩容成功以后,运行过
ansible-playbook rolling_update_monitor.yml
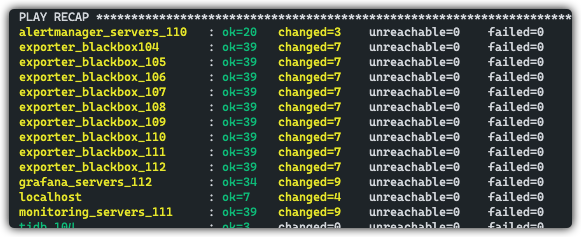
去监控里面发现重复了。

若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】v3.0.5
【问题描述】
因为是测试环境,我把 tipd 与 几个监控组件都部署在一起了。
扩容成功以后,运行过
ansible-playbook rolling_update_monitor.yml
去监控里面发现重复了。
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
麻烦参考下面这个文档,检查下扩容 PD 的步骤是否都正确:
https://docs.pingcap.com/zh/tidb/v3.0/scale-tidb-using-ansible#扩容-pd-节点
扩容是这个步骤呢,一模一样的操作,我发现,我们生产环境也是重复的策略。
上述这个现象,我在测试环境,从新部署了一下,也发现是重复的。
集群的拓扑文件方便提供下吗
## TiDB Cluster Part
[tidb_servers]
tidb_104 ansible_connection=ssh ansible_host=10.10.10.104 deploy_dir=/data/tidb/deploy
tidb_105 ansible_connection=ssh ansible_host=10.10.10.105 deploy_dir=/data/tidb/deploy
tidb_106 ansible_connection=ssh ansible_host=10.10.10.106 deploy_dir=/data/tidb/deploy
[tikv_servers]
tikv_107 ansible_connection=ssh ansible_host=10.10.10.107 deploy_dir=/data/tidb/deploy
tikv_108 ansible_connection=ssh ansible_host=10.10.10.108 deploy_dir=/data/tidb/deploy
tikv_109 ansible_connection=ssh ansible_host=10.10.10.109 deploy_dir=/data/tidb/deploy
[pd_servers]
tipd_110 ansible_connection=ssh ansible_host=10.10.10.110 deploy_dir=/data/tidb/deploy
tipd_111 ansible_connection=ssh ansible_host=10.10.10.111 deploy_dir=/data/tidb/deploy
tipd_112 ansible_connection=ssh ansible_host=10.10.10.112 deploy_dir=/data/tidb/deploy
tipd_109 ansible_connection=ssh ansible_host=10.10.10.109 deploy_dir=/data/tidb/deploy
tipd_108 ansible_connection=ssh ansible_host=10.10.10.108 deploy_dir=/data/tidb/deploy
tipd_107 ansible_connection=ssh ansible_host=10.10.10.107 deploy_dir=/data/tidb/deploy
[spark_master]
[spark_slaves]
[lightning_server]
[importer_server]
## Monitoring Part
# prometheus and pushgateway servers
[monitoring_servers]
monitoring_servers_104 ansible_connection=ssh ansible_host=10.10.10.104 deploy_dir=/data/tidb/deploy
# monitoring_servers_107 ansible_connection=ssh ansible_host=10.10.10.107 deploy_dir=/data/tidb/deploy
# monitoring_servers_111 ansible_connection=ssh ansible_host=10.10.10.111 deploy_dir=/data/tidb/deploy
[grafana_servers]
# grafana_servers_108 ansible_connection=ssh ansible_host=10.10.10.108 deploy_dir=/data/tidb/deploy
grafana_servers_105 ansible_connection=ssh ansible_host=10.10.10.105 deploy_dir=/data/tidb/deploy
# grafana_servers_112 ansible_connection=ssh ansible_host=10.10.10.112 deploy_dir=/data/tidb/deploy
# node_exporter and blackbox_exporter servers
[monitored_servers]
exporter_blackbox104 ansible_connection=ssh ansible_host=10.10.10.104 deploy_dir=/data/tidb/deploy
exporter_blackbox_105 ansible_connection=ssh ansible_host=10.10.10.105 deploy_dir=/data/tidb/deploy
exporter_blackbox_106 ansible_connection=ssh ansible_host=10.10.10.106 deploy_dir=/data/tidb/deploy
exporter_blackbox_107 ansible_connection=ssh ansible_host=10.10.10.107 deploy_dir=/data/tidb/deploy
exporter_blackbox_108 ansible_connection=ssh ansible_host=10.10.10.108 deploy_dir=/data/tidb/deploy
exporter_blackbox_109 ansible_connection=ssh ansible_host=10.10.10.109 deploy_dir=/data/tidb/deploy
exporter_blackbox_110 ansible_connection=ssh ansible_host=10.10.10.110 deploy_dir=/data/tidb/deploy
exporter_blackbox_111 ansible_connection=ssh ansible_host=10.10.10.111 deploy_dir=/data/tidb/deploy
exporter_blackbox_112 ansible_connection=ssh ansible_host=10.10.10.112 deploy_dir=/data/tidb/deploy
[alertmanager_servers]
# alertmanager_servers_109 ansible_connection=ssh ansible_host=10.10.10.109 deploy_dir=/data/tidb/deploy
alertmanager_servers_106 ansible_connection=ssh ansible_host=10.10.10.106 deploy_dir=/data/tidb/deploy
# alertmanager_servers_110 ansible_connection=ssh ansible_host=10.10.10.110 deploy_dir=/data/tidb/deploy
[kafka_exporter_servers]
## Binlog Part
[pump_servers]
[drainer_servers]
## For TiFlash Part, please contact us for beta-testing and user manual
[tiflash_servers]
## Group variables
[pd_servers:vars]
# location_labels = ["zone","rack","host"]
## Global variables
[all:vars]
deploy_dir = /home/tidb/deploy
## Connection
# ssh via normal user
ansible_user = tidb
cluster_name = test-cluster
# CPU architecture: amd64, arm64
cpu_architecture = amd64
tidb_version = v3.0.5
# process supervision, [systemd, supervise]
process_supervision = systemd
timezone = Asia/Shanghai
enable_firewalld = False
# check NTP service
enable_ntpd = True
set_hostname = False
## binlog trigger
enable_binlog = False
# kafka cluster address for monitoring, example:
# kafka_addrs = "192.168.0.11:9092,192.168.0.12:9092,192.168.0.13:9092"
kafka_addrs = ""
# zookeeper address of kafka cluster for monitoring, example:
# zookeeper_addrs = "192.168.0.11:2181,192.168.0.12:2181,192.168.0.13:2181"
zookeeper_addrs = ""
# enable TLS authentication in the TiDB cluster
enable_tls = False
# KV mode
deploy_without_tidb = False
# wait for region replication complete before start tidb-server.
wait_replication = True
# Optional: Set if you already have a alertmanager server.
# Format: alertmanager_host:alertmanager_port
alertmanager_target = ""
grafana_admin_user = "admin"
grafana_admin_password = "admin"
### Collect diagnosis
collect_log_recent_hours = 2
enable_bandwidth_limit = True
# default: 10Mb/s, unit: Kbit/s
collect_bandwidth_limit = 10000
请问是后来把 pd 扩容到了 107.108,109 吗? 方便看下 107 上 tidb 的进程都有哪些吗? 如果是 tidb 用户,ps -ef | grep tidb 反馈下结果,重点看下 node 和 black 进程有几个,多谢。
1.可以尝试下将 pd-server 节点重新缩容为 3 个后,再观察下是否正常;
2.TiDB 的监控告警主要是依赖于 Alertmanager 组件来实现,grafana 中的监控信息不用太关注,毕竟它更多作用是展示监控数据而非专业告警,可以参考下:
https://docs.pingcap.com/zh/tidb/v3.0/tidb-monitoring-framework
那就先这样吧,我缩容到3个,依然是规则重复的,应该是部署工具的bug,全新的部署也会出现这个情况,所以,看看是不是要修嘛
不过目前使用的版本相对来说比较旧了,ansbile 部署方式已经不再维护了,如果方便的话可以考虑升级到 v4.0 版本,统一使用 tiup 进行集群管理。
