SURZ
(Zee)
1
【DM 版本】 2.0
【问题描述】
我们使用dm2.0做mysql到tidb的同步,昨天部分mysql做了切换,dm的source做修改,重启后source绑定的worker改变了。
重新启动task发现存在两条监控数据。
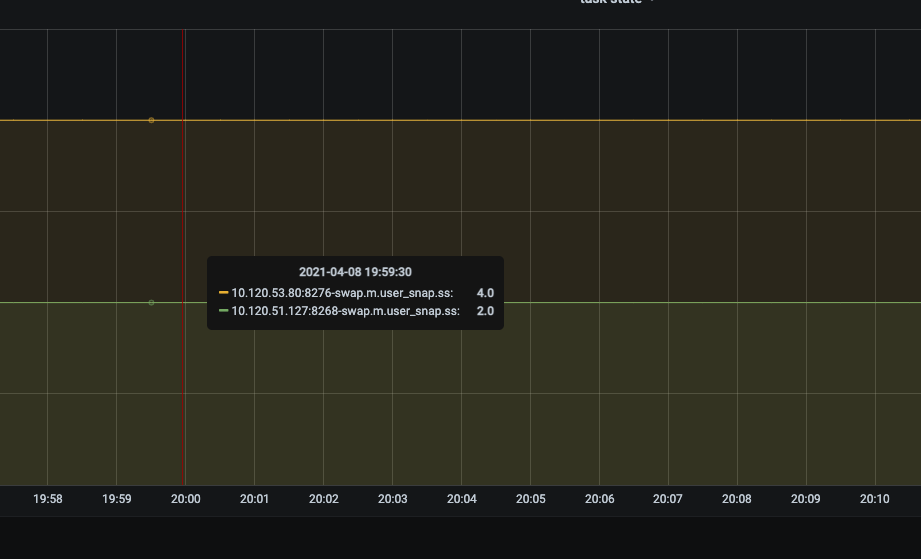
task status 如下:
old_worker-taskname [4]
new_worker-taskname [2]
我们的会判断task状态为4电话告警,导致当前task状态正常电话告警乱告的情况出现。
请问有什么办法去掉历史的task,或者更新监控?
SURZ
(Zee)
3
1.当前状态是正常的。
2.改变了source的地址,批量的重启。
3.dm集群没有重启。
task名相同,重启后bound的worker做了改变,导致监控有两个。现在是想消除掉之前bound的worker信息,图片上task status 为4的监控。
SURZ
(Zee)
4
我们又发现,大部分task status是有两个监控值,但是极少数几个query-status查看task当前状态是正常的,但是task status是4,监控值是不对的。
SURZ
(Zee)
6
# 1. 修改 source 的配置文件
enable-relay: true
relay-binlog-name: 'mysql-bin-changelog.000002' # 拉取上游 binlog 的起始文件名,可以通过查看当前任务的masterBinlog、syncerBinlog;或者直接去上游查看master status
# 2. 停止相关的task
dba_dmctl stop-task db3.task2
# 3. 停止source
dba_dmctl operate- source stop database-3
# 4. 启动soruce
dba_dmctl operate- source create source -database-3.yaml
# 5. 启动task
dba_dmctl start-task .. /conf/db3 .task1.yaml
以上是我们的操作步骤,我们是为了解决同一个source 多个dump thread问题,添加了enable-relay参数后。重启worker和task。
SURZ
(Zee)
8
1.我在dm1.06有关注到报错的task,有的时候状态会是stopped状态,所以我们的设置task status大于2的都电话告警。dm2.0沿用的之前的告警规则。
2.我查阅文档没有发现dm-worker如何重启,是下线再上线吗?
3.另外我也还有一个疑问,如果task我们废弃了,如何下线掉废弃task的监控?
DM 于 4/9 发布了 v2.0.2 版本,短期内暂时不会发布新版本。
我建了一个 issue trace 这个问题: https://github.com/pingcap/dm/issues/1594
你可以在 dm repo 里 trace 这个问题以及新发版计划
BoobooWei
(Booboo Wei)
12
@lichunzhu-PingCAP 我是 @SURZ 的同事,我们还发现一个问题,Task的延迟指标数据没有了,grafana上为空,prometheus中也没有这个指标了。
例如:10.120.51.127:8263 这个worker
curl ‘http://10.120.51.113:9090/api/v1/query?query=dm_syncer_replication_lag&time=2021-04-15T03:44:00Z’
{“status”:“success”,“data”:{“resultType”:“vector”,“result”:[]}}
是说新 worker 上没有了?这个不开 heart-beat 的话应该就是没有的,现在 dm2.0 还没有支持 heart-beat
BoobooWei
(Booboo Wei)
14
因为开启后,遇到无法重新启动的问题,看到你们文档后我们就关闭了:
如果用户在同步任务配置文件中开启 enable-heartbeat 会干扰高可用特性,在配置文件中关闭该项(通过设置 enable-heartbeat: false,然后更新任务配置)即可解决。DM 将会在后续版本强制关闭该功能。
那究竟是关还是开呢?
现在 dm-2.0 保持关闭就可以了,后续等这个功能支持后再开吧
BoobooWei
(Booboo Wei)
16
如果开启影响高可用
如果不开又缺少监控,这怎么看延迟呢?
BoobooWei
(Booboo Wei)
19
请问具体的指标名称是什么?我没有找到 和 gap 有关的metric
在后两个月内有开发这个的计划。enable-heartbeat 后面可能后续不会支持,因为这个功能写了上游数据库,后续会考虑用别的方式来计算延时