课程链接
课程大纲
-
数据库、大数据与 TiDB 的发展简史
-
01: 数据库、大数据发展历史与趋势
-
02: 分布式关系数据库的发展
-
03: TiDB 产品与开源社区演进
-
-
TiDB 整体概述
-
04: 我们到底需要一个什么样的数据库
-
05: 如何构建一个分布式存储系统
-
06: 如何构建一个分布式 SQL 引擎
-
-
新一代 HTAP 数据库选型
-
07: 基于分布式架构的 HTAP 数据库
-
08: TiDB 关键技术创新
-
09: TiDB 典型应用场景及用户案例
-
-
TiDB 初体验
- 10: TiDB 初体验
课程笔记(中)
-
存储引擎
-
更细粒度的弹性扩缩容
-
高并发读写
-
数据不丢不错
-
多副本保障一致性及高可用
-
支持分布式事务
-
-
数据结构是数据库的核心基础技术
-
BTree与LSM-tree
-
LSM-tree结构本质上是一个用空间置换写入延迟,用顺序写入替换随机写入的数据结构。
-
TiKV单节点选择了基于LSM-tree的rocksdb引擎
-
-
-
数据副本
-
共识算法:raft、paxos
-
实现扩展:预先分片(静态)、自动分片(动态)
-
分片算法:hash、range、list
-
range分片
-
更高效地扫描数据
-
简单实现自动完成分裂与合并
-
弹性优先,分片需要可以自动调度
-
会遇到热点分片问题
-
-
-
-
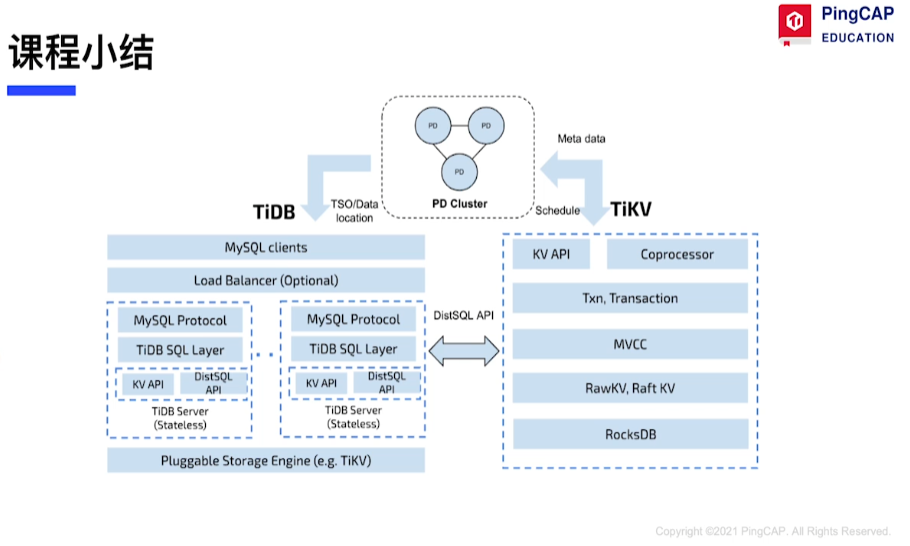
TiKV
-
一个 Multi-Raft 系统,其数据按 Region(默认 96M)切分
-
每个 Region 是一个 Key 的范围,从 StartKey 到 EndKey 的左闭右开区间。
-
数据的存储/访问/复制/调度都是以region为单位
-
多版本控制:TiKV的MVCC实现是通过在Key后面添加版本号
-
coprocessor是tikv中读取数据并计算的模块,每个tikv存储节点都有一个协调计算器
-
-
分布式事务模型
-
去中心化的两阶段提交
-
Google percolator事务模型
-
TiKV支持完整事务 KV API
-
默认乐观事务模型
-
默认隔离级别 snapshot isolation
-
-
在KV上实现逻辑表,基于KV的二级索引
-
基于成本优化器
-
分布式SQL引擎主要优化策略:push down
-
关键算子分布式化
-
online ddl 算法
-
tidb里没有分表概念
-
把ddl过程分成public、delete-only、write-only等几个状态,每个状态在多节点之间同步和一致,最终完成完整的DDL
-
-
tidb-server是一个对等、无状态的、可横向扩展的,支持多点写入的,直接承接用户SQL的入口
-
tidb-server的其他功能
-
前台功能
-
管理连接和账号权限管理
-
MYSQL协议编码解码
-
独立的SQL执行
-
库表元信息,以及系统变量
-
-
后台功能
-
GC
-
执行DDL
-
统计信息管理
-
SQL优化器与执行器
-
-

参考资料