变又未变
(变又未变)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v5.0.0-rc
【问题描述】
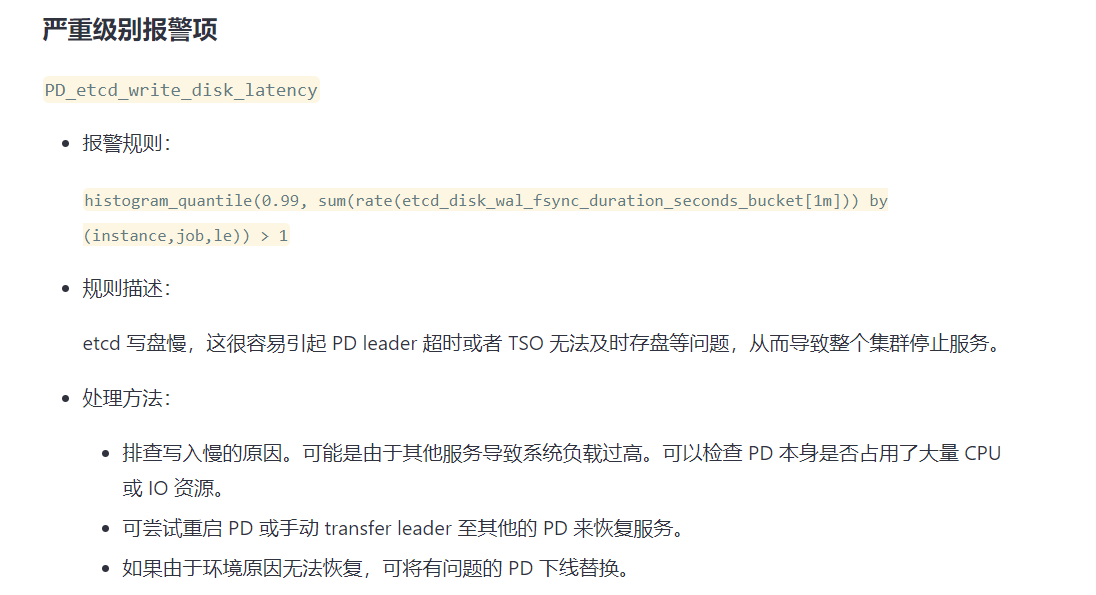
现在想要把prometheus中的一些信息单独拿出来,放到shell脚本中,如下面这个信息:
现在我执行:curl
http://172.20.146.145:9090/graph?g0.range_input=1h&g0.expr=histogram_quantile(0.99%2C%20sum(rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m]))%20by%20(instance%2Cjob%2Cle))&g0.tab=1
有问题:-bash: syntax error near unexpected token `0.99%2C%20sum’
这个想请教一下,怎么把prometheus中这个界面的数据拿出来?
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yilong
(yi888long)
2
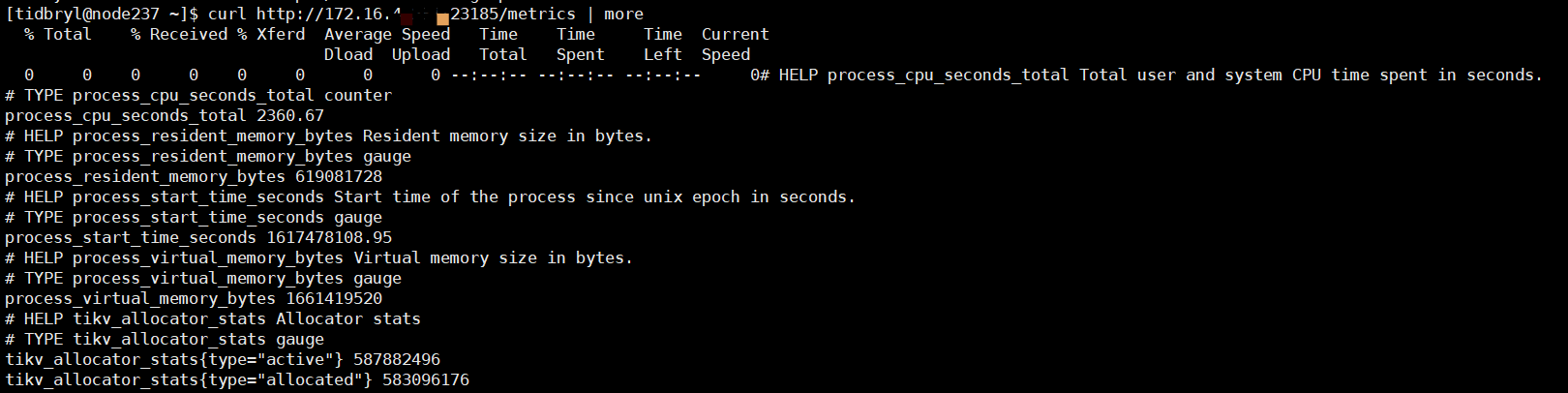
这里没法取数据吧,取到的包括网页信息。 如果想要具体某个实例的参数,感觉还是直接在具体的节点取值是不是好一些。 比如 tikv 节点 curl http://:<stauts_port>/metrics | more 找到具体想要的值。
如果你要的是 Prometheus 存储的指标,需要用 PromQL (Prometheus Query Language) 去查,有 HTTP API 可以用,参考官方文档
不知道 你拿到这个信息是要做什么呢?展示指标有 Grafana ,报警有 Grafana 和 Alertmanager,感觉没有必要再手动取了吧
变又未变
(变又未变)
5
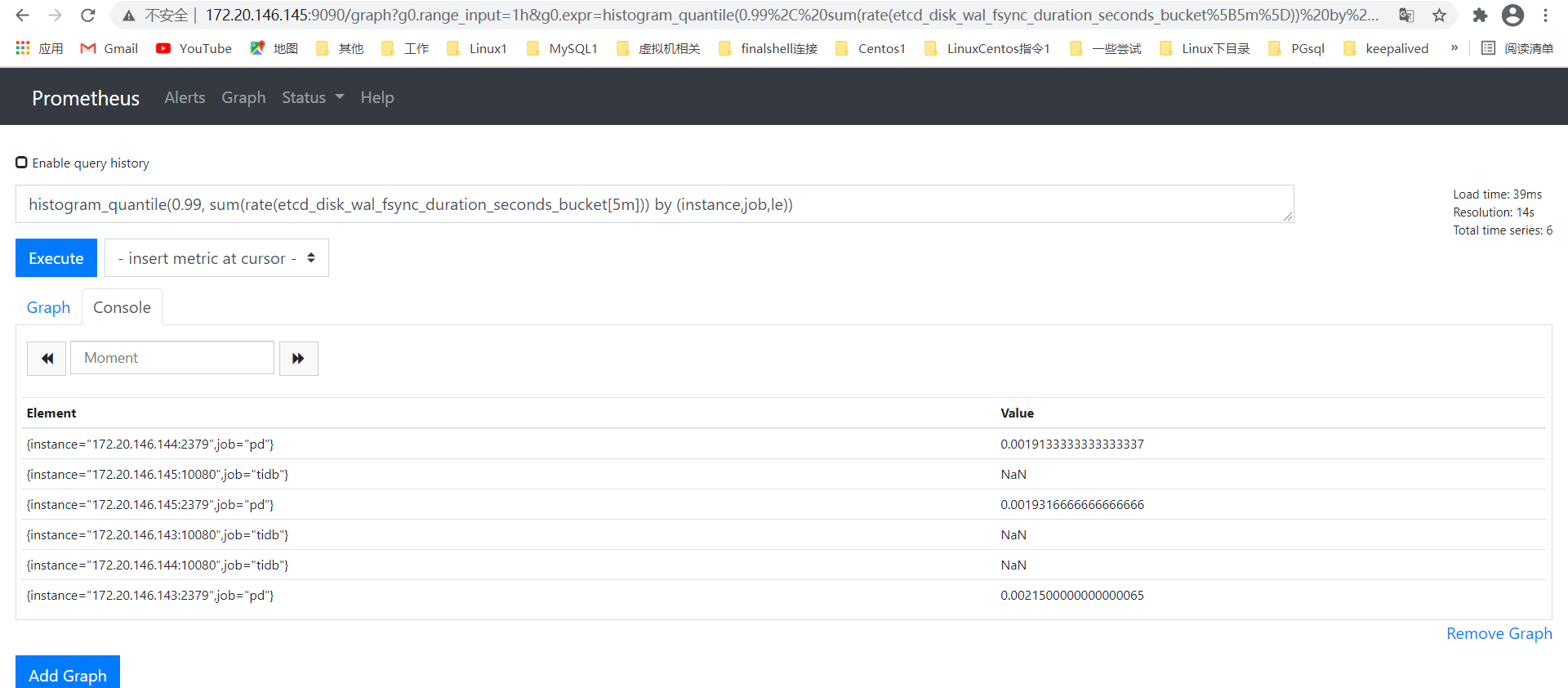
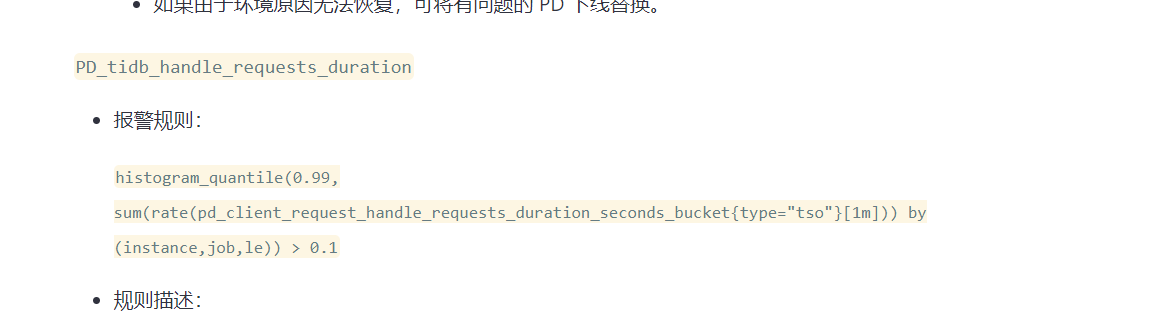
我发现grafana和官网上的一些指标不一样,我这个按照哪个看呢?
如:
grafana:
官网上:
是不一样,因为官网说的表达式是报警规则表达式,Grafana 上的表达式是作图展示的查询表达式
我觉得你得先好好熟悉一下 prometheus, grafana , alertmanager 这些组件不是 tidb 的
变又未变
(变又未变)
7
那这个报警规则不是在grafana中显示的嘛?但是有的报警规则的值官网上和grafana中是对应的。。。
https://docs.pingcap.com/zh/tidb/stable/tidb-monitoring-framework
文档内容不知道是不是最新的,但是不影响理解 tidb 的监控思路
你先好好看看这些,上手用用。
不是,报警规则是给 alertmanager 的
报警规则的值就只有 true 和 false
变又未变
(变又未变)
9
额,好吧,还是先谢谢你了,框架我看过了,有些不太清除的地方才问了,说句实话,
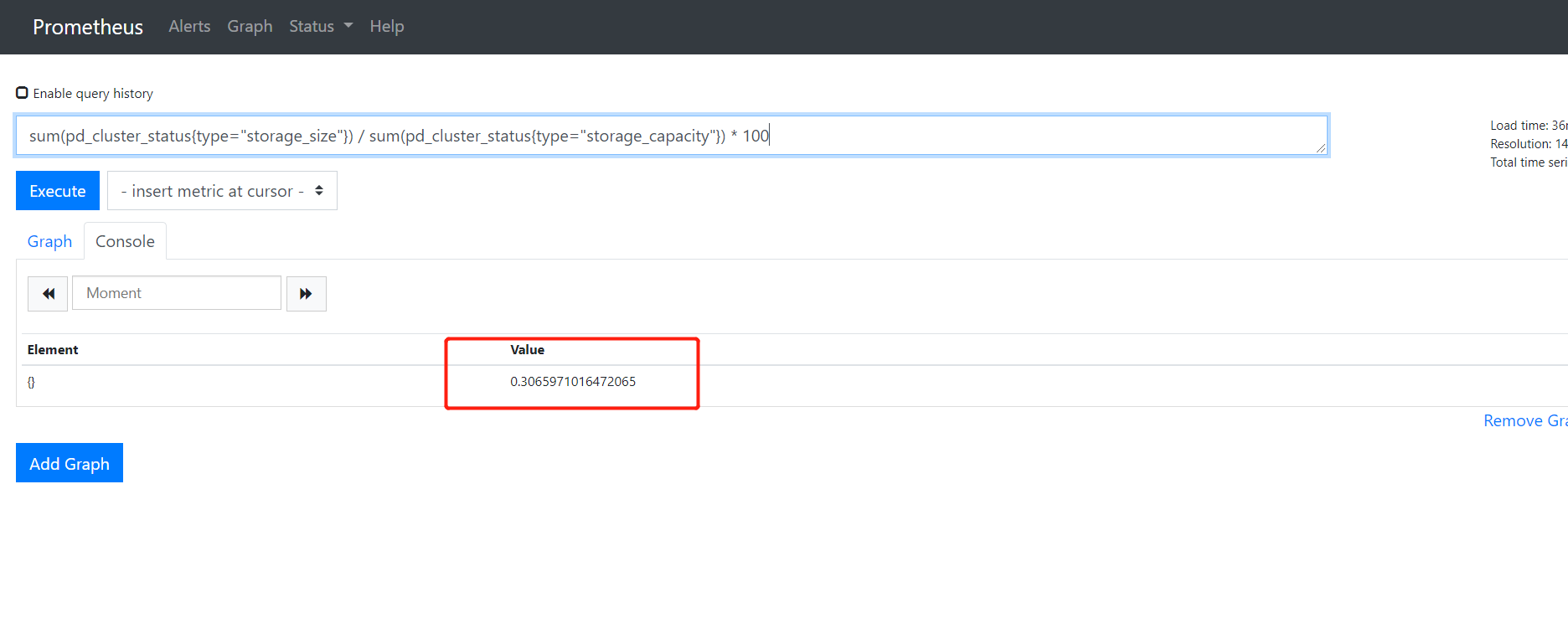
1、我在premetheus找到了一些监控指标的值,其中一些是与grafana中值一致的。。。
2、prometheus中的值并不是只有true和false,是可以有数值的:
呃,查询语句 和 报警规则,是不同的。
你得自己用用这些东西,收集收集指标,查一查,自己设置个报警,一开始看不懂 tidb 的文档没关系,因为那些文档有个前提就是你对这些工具得达到一定的熟悉程度。
system
(system)
关闭
12
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。