DML (Data manipulation language) 是 SQL 里面重要的一部分,也就是增删改查
数据写入原理
- DML 语句执行流程
- insert executor
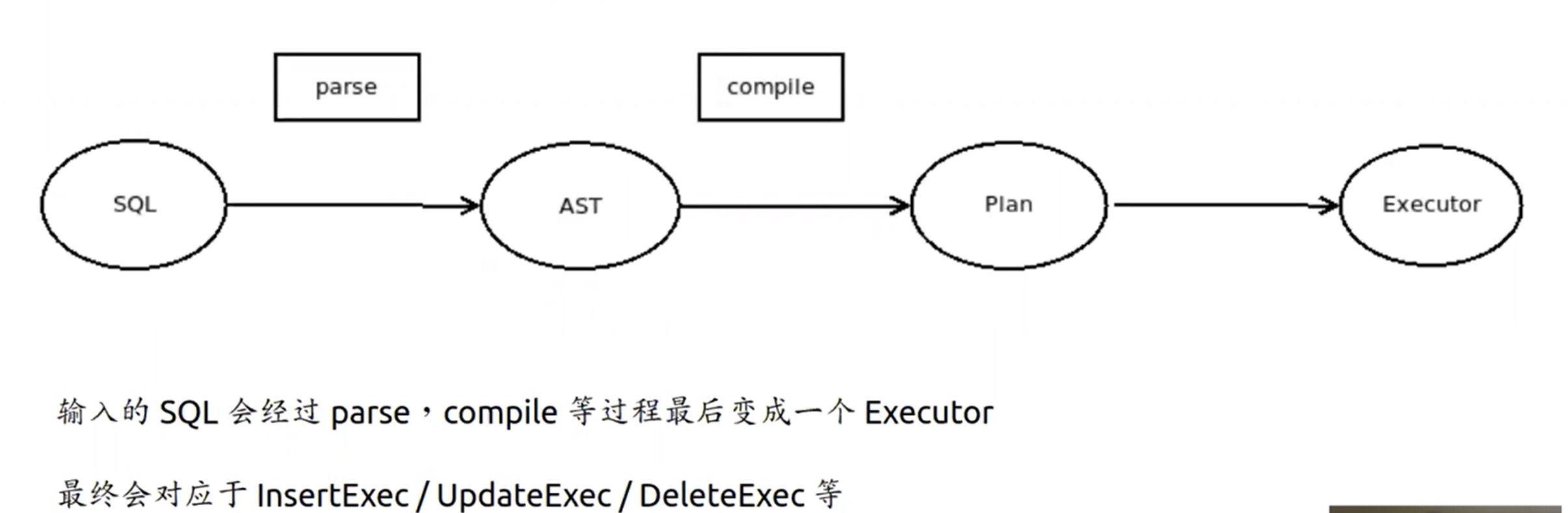
- Table 接口的作用
- insert executor 会通过 调用 table 接口写入数据
- table 接口的主要作用
- 将Row 转换为 key- value
- 通过 Add 、update、remove 等接口函数
- 调用 tablecodec 编码规则
- 写入 UnionStore
- 想象成一个 key - value 容器
- 缓存所有的修改直到事务提交
- 维护数据和索引的一致性
- 写入数据时,同时写入索引
- 删除数据时,同时删除索引
- 对调用者屏蔽 Table 细节
- 保障DDL 变更过程中的 Schema 可见性
- table schema 不是一成不变的
- 添加删除列,添加删除索引
- schema 变更期间的一致性保证
- 将Row 转换为 key- value
- Union Store 的概念
- snapshot + membuffer
- 事务所有的修改,提交前缓存在内存
- 读操作需要先读缓存,在读快照
- 乐观事务的行为和影响
- 写入时不报错,提交才出现事务冲突
- 主键和唯一索引冲突的检测时机可能退后

事务提交
- 收集事务的修改
- 按Region 切分
- 事务的修改可能涉及多个 region
- 不同的region 落在不同的 tikv
- 重新组织,将请求发送到真确的tikv
- 批量发送
- 执行两阶段提交
- 同步写入 Primary key 所在的 region
- 异步(同步)写secondary 的 regions
- Primary key 可以确定事务最终的成功和失败

语句级别回滚
statement 有自己的缓存,只有当语句成功执行完成时,才会刷到 union store 里面
保证statement 执行失败时,不会留下脏数据
数据读取原理
- DistSql
- 流失接口
- 对上层屏蔽从各个region 获取数据的细节
- 数据分布在多个region中,因为请求也要发送到各个region 中

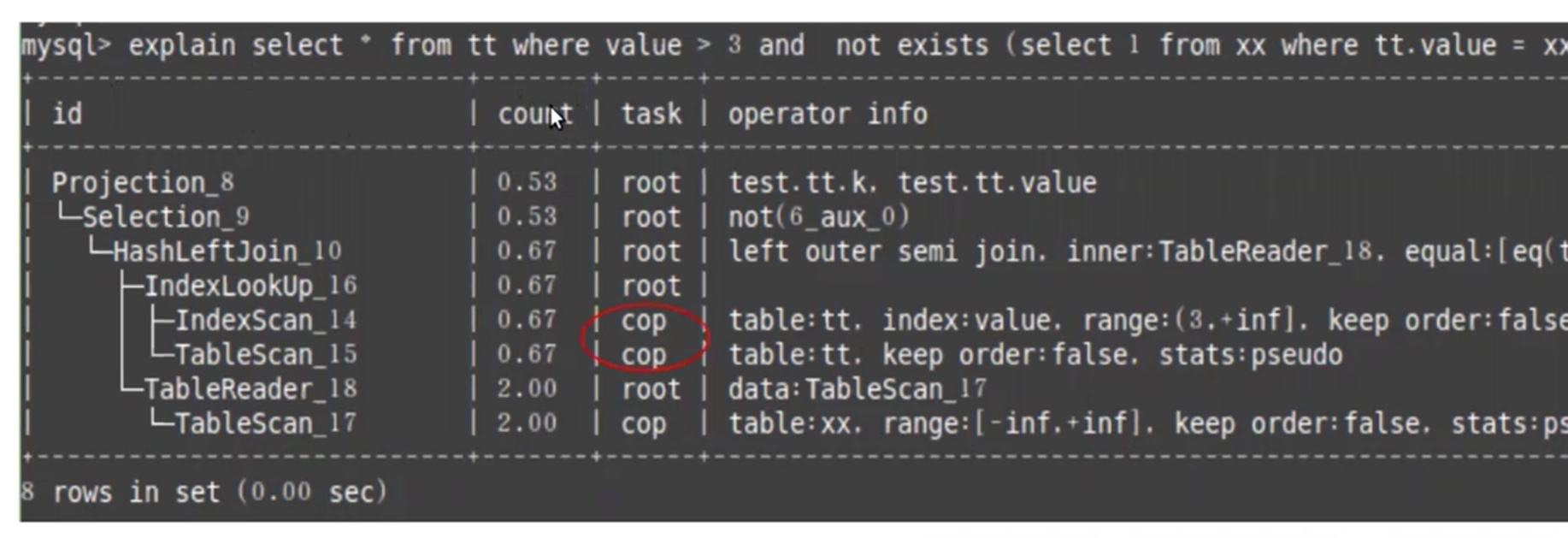
- 生成查询计划
- 查询计划中task 分为 root 和 cop
- root 会从tikv 拿到数据后,传递到tidb 去做相应的处理
- cop 会在tikv 完成数据的处理
- 执行器和火山模型
- Executor 形成一棵树结构
- 不停调用 Next() 获取数据
- 数据由下往上流动
- 每个算子里面执行相应的计算
- TableReader
- Filter
- topN
- HashJoin,indexLookup,etc…
- Coprocessor
- 逻辑上数据Tidb,物理上由 tikv 实现
- 移动数据不如移动计算
- 计算下推到离数据近的地方
- 节省网络数据传输开销
- 发挥分布式的优势
- 单个tidb 节点执行计算,系统不是 Scalable 类型的
- region 分散在各个tikv,让所有的tikv 参与计算
- 不少executor 都可以下推或者 部分下推到 tikv 里面
- filter, Projection,topN,Aggregate, etc…
Misc
- 几种不同的insert 语句语义区别
- insert 遇到冲突的行返回失败
- insert ignore 遇到冲突的行忽略本条插入,不返回失败
- insert on duplicate update 遇到冲突的行执行更新操作
- replace 遇到冲突的行则覆盖旧的
- replace 和 insert on duplicate 的区别
- 当不发生冲突时,replace 和 insert on duplicate 等价于 insert
- 当发生冲突时
- replace 等价于 先delete 冲突行,在插入现有行数据
- insert on duplicate 等价于直接更新冲突行,并且还有可能再次发生冲突

- 何时检测冲突,insert 语句的 lazy check
- 默认是两阶段提交前,才去检查冲突
- 变量 tidb_constraint_check_in_place 可以控制检查冲突行为
- 同一事务你没自身冲突可被检测到
- 怎么改写语句让执行更快
- Sql 改写
- 优化器加 hint