为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.10
【问题描述】
现在,应要求,
1、想要知道prometheus中的pd、tikv、tidb中的信息是存放在那里?可以通过curl,或这个什么工具直接在linux界面打印出来嘛?
2、grafana是通过哪些API接口调用prometheus中的数据,然后图形化
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
v4.0.10
【问题描述】
现在,应要求,
1、想要知道prometheus中的pd、tikv、tidb中的信息是存放在那里?可以通过curl,或这个什么工具直接在linux界面打印出来嘛?
2、grafana是通过哪些API接口调用prometheus中的数据,然后图形化
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
pd tikv pd 把 metric 每隔一段时间输出到一个地方。
prometheus 主动到那个地方去拿 metric 的数据,存放在时序数据库中。
额,好的,这个地方是?还有,grafana是到prometheus这个时序数据库中拿数据的,是吧,那么grafana是怎么通过API从时序数据库中拿数据,以及拿了哪些数据呢?
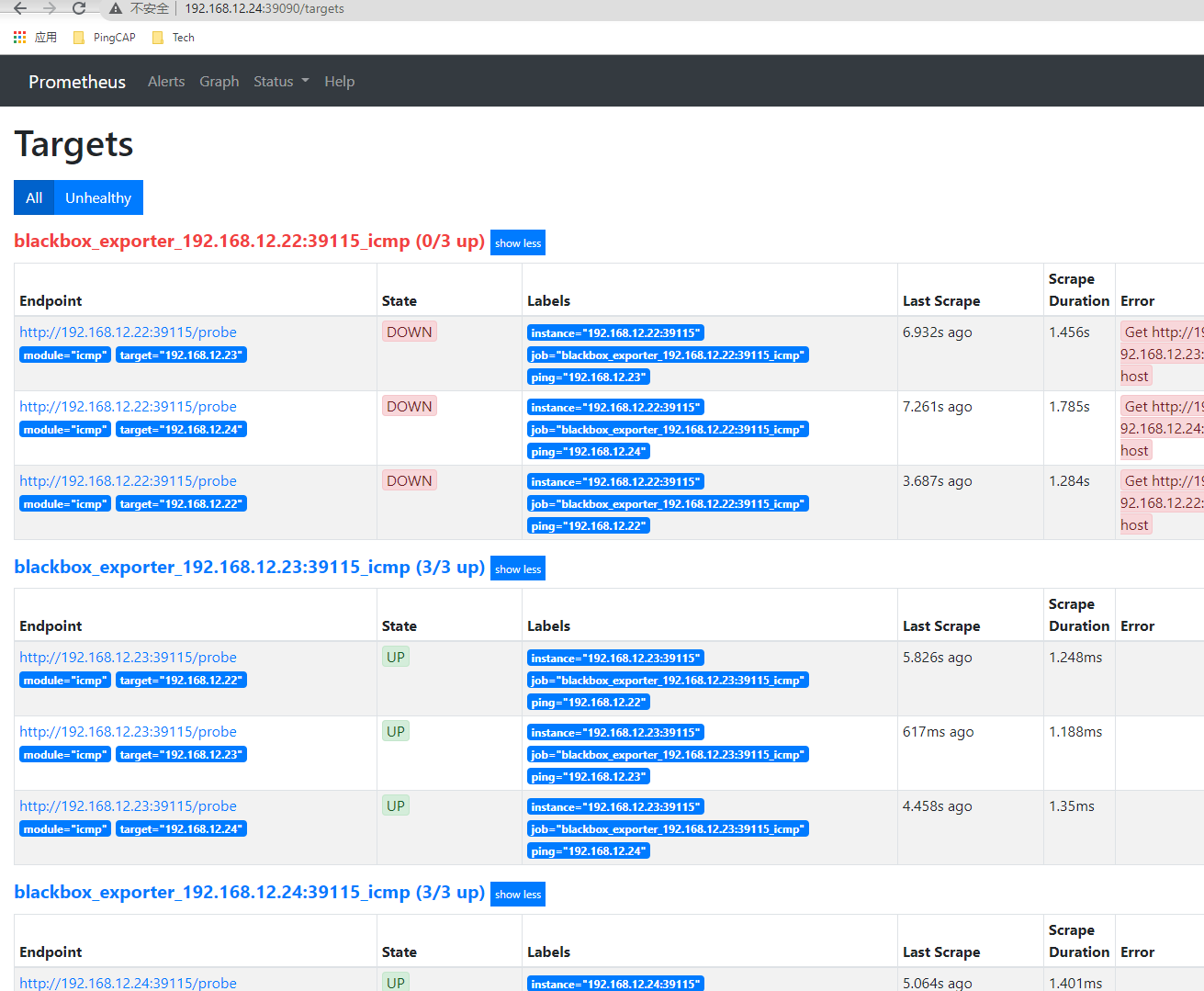
在 prometheus 的页面里面打开 status → target
右侧的 endpoint 就是 pd tikv tidb 的 metic 输出端口。
手动使用 curl 的话,也是可以去查看的
[root@r20 topology]# curl http://192.168.12.23:39100/metrics | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
10# HELP go_gc_duration_seconds A summary of the GC invocation durations. 0
go_gc_duration_seconds{quantile=“0”} 9.21e-06
go_gc_duration_seconds{quantile=“0.25”} 3.089e-05
go_gc_duration_seconds{quantile=“0.5”} 8.2571e-05
go_gc_duration_seconds{quantile=“0.75”} 0.000158291
go_gc_duration_seconds{quantile=“1”} 0.001209458
go_gc_duration_seconds_sum 0.601837869
go_gc_duration_seconds_count 4068
感兴趣的话,可以在了解一下 prometheus 的原理。
哦,好的,谢谢,我看看
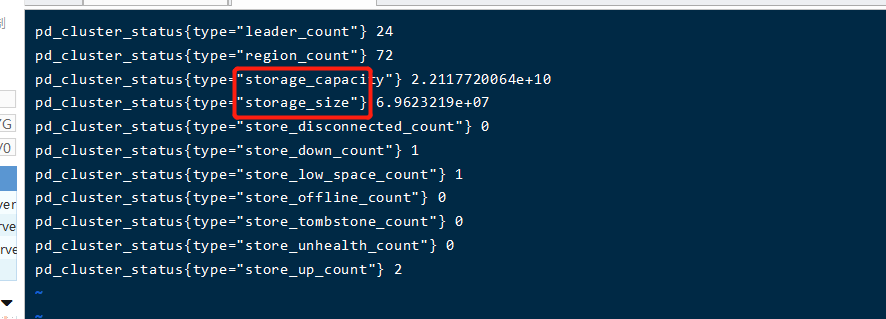
大佬,你好,我导出了一些数据,有些不明白的地方:storage_capacity和storage_size的区别是什么,我理解的都是存储空间。
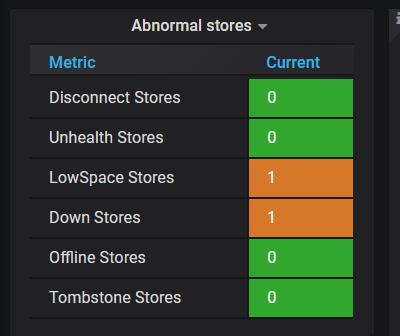

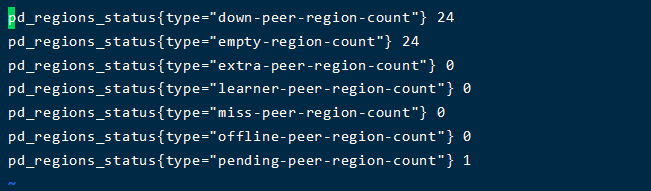
好的,谢谢,我看一下,辛苦您了
![]()
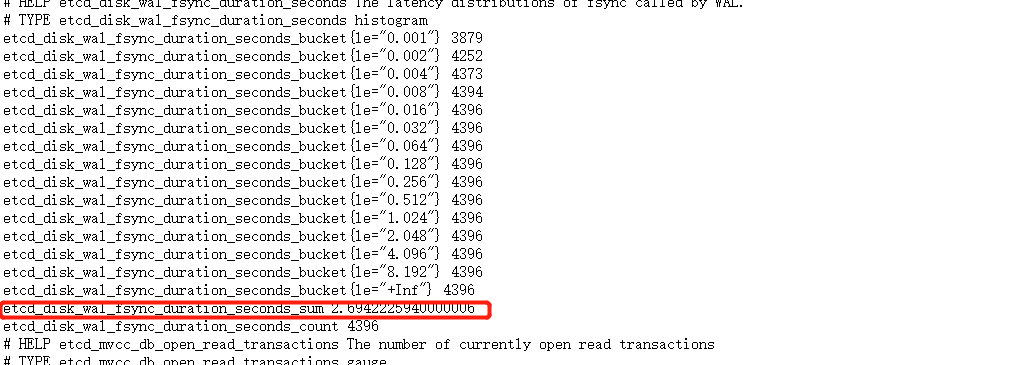
大佬好,我在看这个prometheus的pd的元数据信息,其中,这个里面的etcd_disk_wal_fsync_duration_seconds_sum的值和grafana中的值对不上,我两边同时刷新,值还是不一样,这里还有什么其他的计算嘛?
可以 edit grafana 页面看下表达式是怎么样的,grafana 显示的是表达式的结果,prometheus 中记录的是原始的监控项数据,两者并一定等同。
histogram_quantile(0.99, sum(rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])) by (instance, le))是这个,这个和官网上一样。。。具体怎么算的还是不太清楚![]()
好的,谢谢
![]()