-
当前 PD 的 data dir 用的磁盘是哪块盘,是 dm-01 吗?
-
当前服务器
192.168.0.209的 CPU 核数是多少? -
辛苦再导出下
192.168.0.209的 Grafana 的 Disk-Performance 监控,默认情况下 write latency metrics 不显示,请取消隐藏后,导出监控:

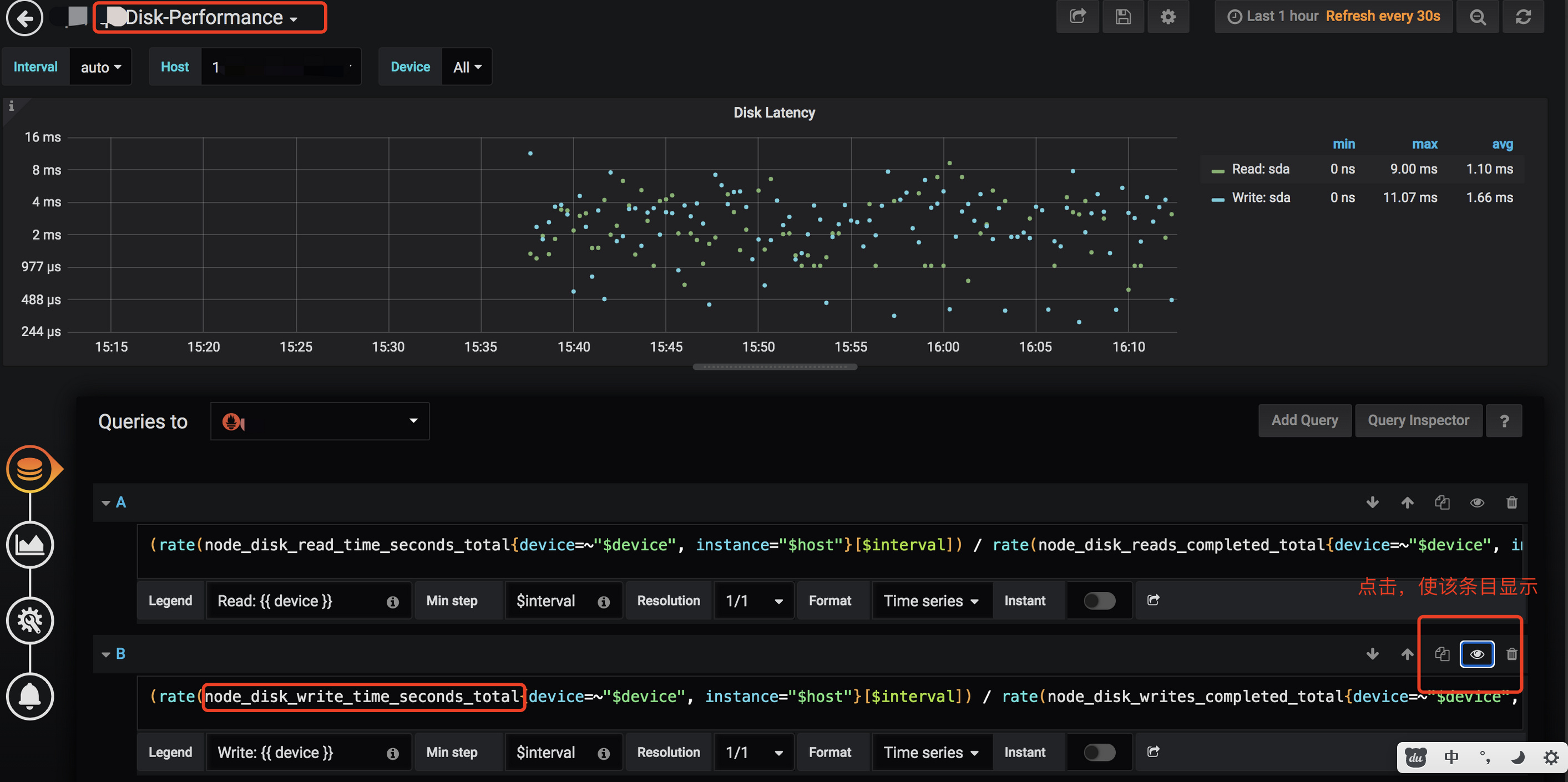
另外,22:50 左右是有业务跑批吗?看起来在这个时间点,服务器的 load 以及 iops write,read latency 指标都有变化:


并且,这个时间点和 PD log 第一次出现 apply request took too long 的时间有吻合:
[2021/04/05 22:50:06.733 +08:00] [Warn] [util.go:144] ["apply request took too long"] [took=255.488221ms] [expected-duration=100ms] [prefix="read-only range "] [request="key:\"/pd/6846941113233660477/gc/safe_point/service\" range_end:\"/pd/6846941113233660477/gc/safe_point/servicf\" "] [response="range_response_count:1 size:148"] []
[2021/04/05 22:50:17.607 +08:00] [Warn] [util.go:144] ["apply request took too long"] [took=248.037498ms] [expected-duration=100ms] [prefix="read-only range "] [request="key:\"/tidb/server/minstartts\" range_end:\"/tidb/server/minstarttt\" "] [response="range_response_count:1 size:117"] []
[2021/04/05 22:50:38.952 +08:00] [Warn] [util.go:144] ["apply request took too long"] [took=197.537683ms] [expected-duration=100ms] [prefix="read-only range "] [request="key:\"/tidb/ddl/all_schema_versions\" range_end:\"/tidb/ddl/all_schema_versiont\" "] [response="range_response_count:2 size:210"] []

