为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
3个pd,现在模拟误操作删除tidb-data下的pd和tikv目录问题:
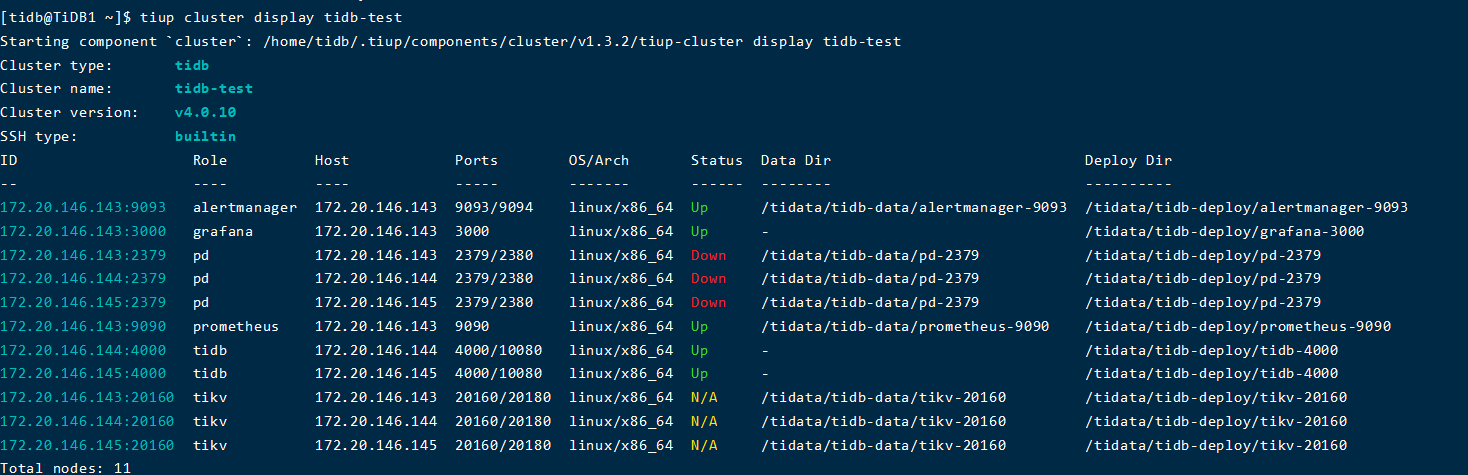
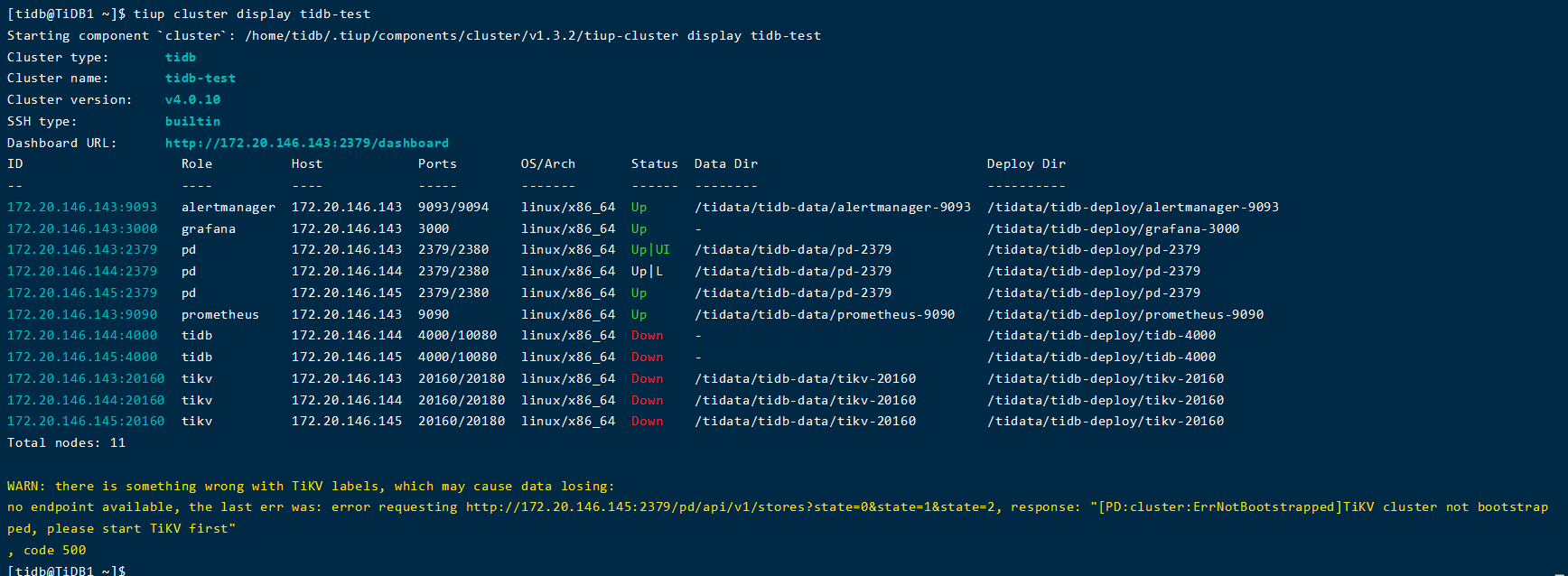
1、删除了pd的leader节点的目录,现在导致理论上应该up的一个pd组件也是down

2、理论上应该up的pd组件报错:

好像是leader的问题,这个怎么让那个pd启动为up
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
3个pd,现在模拟误操作删除tidb-data下的pd和tikv目录问题:
1、删除了pd的leader节点的目录,现在导致理论上应该up的一个pd组件也是down
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
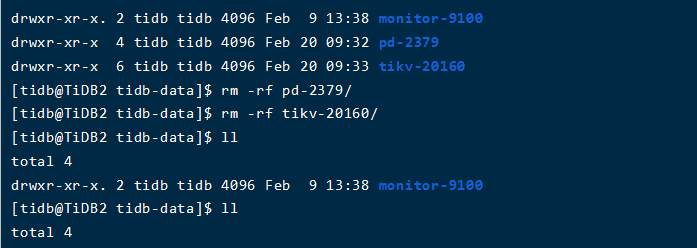
1、就是将tidb-data下的pd-2379和tikv-20160两个目录rm删除了:
该节点pd的日志超过了限制,明明已经只剩下27MB了,我继续删掉一些,留下19号的和今天的:

最新的pd的报错:
[2021/02/20 16:23:55.275 +08:00] [ERROR] [etcdutil.go:65] [“failed to get cluster from remote”] [error="[PD:etcd:ErrEtcdGetCluster]failed to get raft cluster member(s) from the given URLs"]
三台挂了两台只能通过 PD-recover 恢复了。具体可以参考:
https://docs.pingcap.com/zh/tidb/stable/pd-recover#pd-recover-使用文档
好的,谢谢,那个你们那里有类似的案例和具体的恢复操作的步骤嘛?![]()
我这个第一次弄这个,最好能有个借鉴:rofl:
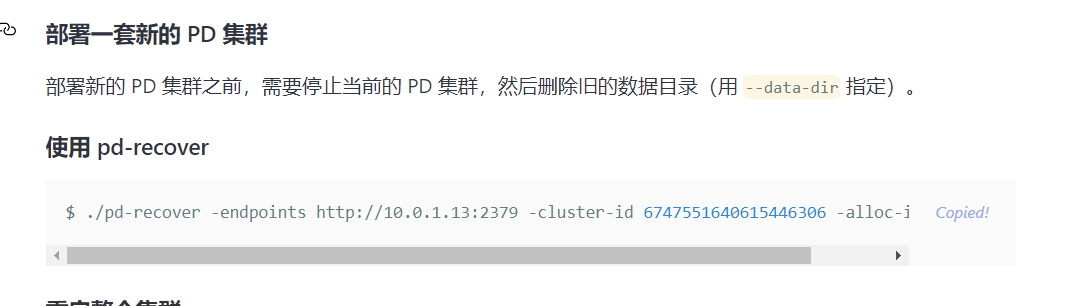
这个部署新的集群中:
1、停止当前的集群是指将所有up和down的pd都stop掉是吧?
2、删除旧目录是指到tidb-data下把pd相关的目录都删掉是吧?
图片上说用–data-dir指定是指在指令后面这么添加,自动删除旧的目录并且新建pd-2379目录嘛:./pd-recover -endpoints http://10.0.1.13:2379 -cluster-id 6747551640615446306 -alloc-id 10000 --data-dir {/path/to/pd-2379}
我可以进入到tidb-data目录下,手动rm嘛?
哦,好的,那这个清理其实就是rm掉,对吧
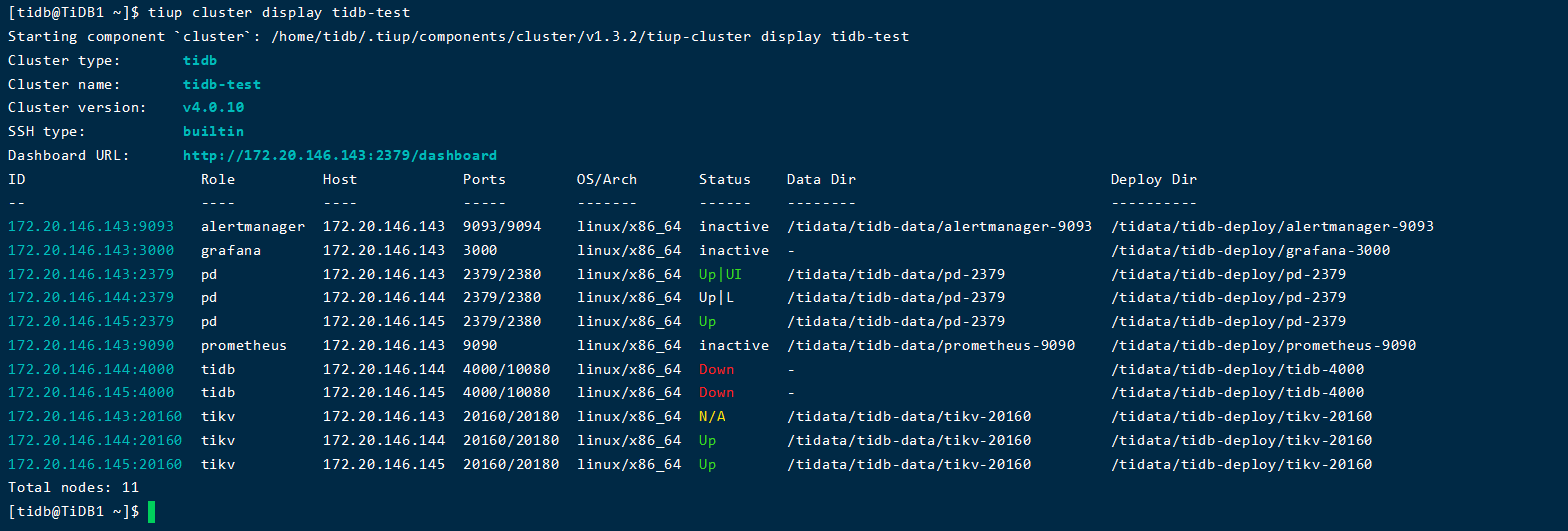
你好,上午的那个一时间没有处理,下午看的时候集群大部分都好了,![]()
大佬,您好,刚刚把原先好的那个节点上tidb-data下的tikv-20160目录移走后,集群好了,这个恢复后,tikv中以前建立的数据库和表好像不在了,那个我想问一下,以前tikv中的数据是在哪里查看?在刚刚移走的那个tikv-20160下面嘛?我看了一下,好像没有看到具体的数据库和表?
大神,有空再看一下哈:
我今天又重新模拟了一下,但是我用pd-recover恢复时:
{“level”:“warn”,“ts”:“2021-02-23T15:50:18.327+0800”,“caller”:“clientv3/retry_interceptor.go:61”,“msg”:“retrying of unary invoker failed”,“target”:“endpoint://client-ded2b4b6-a56b-4803-b69c-727413ff7404/172.20.146.143:2379”,“attempt”:0,“error”:“rpc error: code = DeadlineExceeded desc = latest balancer error: all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.20.146.143:2379: connect: connection refused””}
context deadline exceeded
我看了一下,官网,说是:
好的,谢谢,我看一下
![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。