变又未变
(变又未变)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【TiDB 版本】
4.0.10
【问题描述】
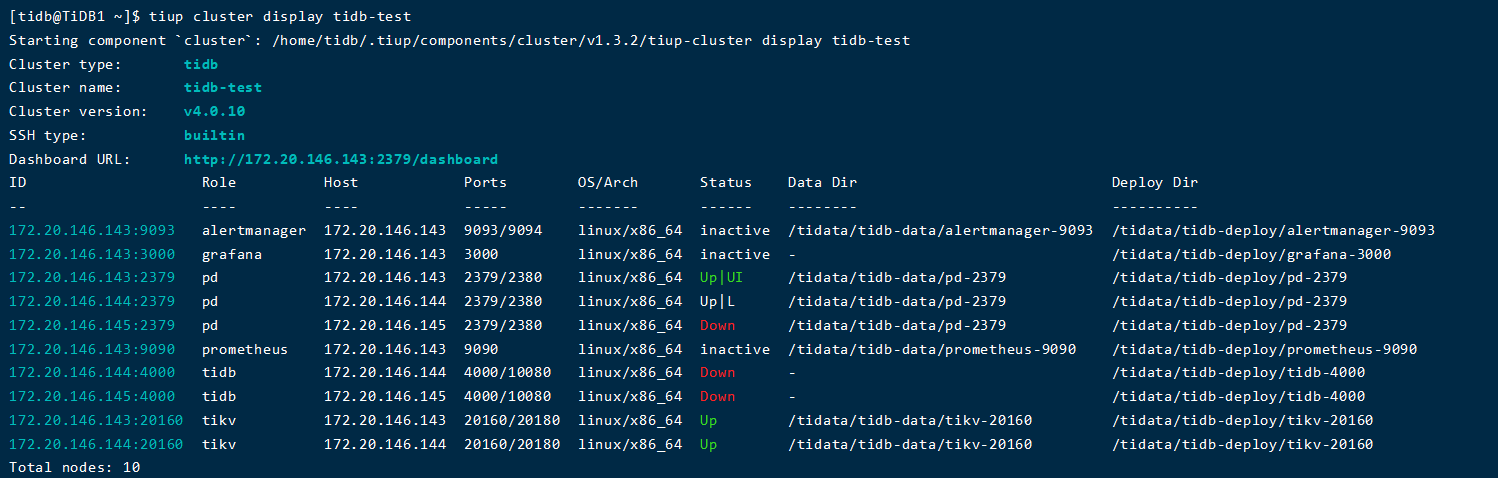
tiup cluster start启动集群时,145节点上,pd没有报错,但是状态为down,并且日志文件中也没有今天启动的相关报错:
然后,使用sh启动脚本启动,一直卡着:
部分日志文件:
查看tidb的报错:
[2021/02/19 09:28:28.017 +08:00] [FATAL] [session.go:1980] [“check bootstrapped failed”] [error=“[tikv:9005]Region is unavailable”] [stack=“github.com/pingcap/tidb/session.getStoreBootstrapVersion
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/session/session.go:1980
github.com/pingcap/tidb/session.BootstrapSession
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/session/session.go:1765
main.createStoreAndDomain
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/tidb-server/main.go:258
main.main
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/tidb-server/main.go:179
runtime.main
\t/usr/local/go/src/runtime/proc.go:203”]
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
变又未变
(变又未变)
2
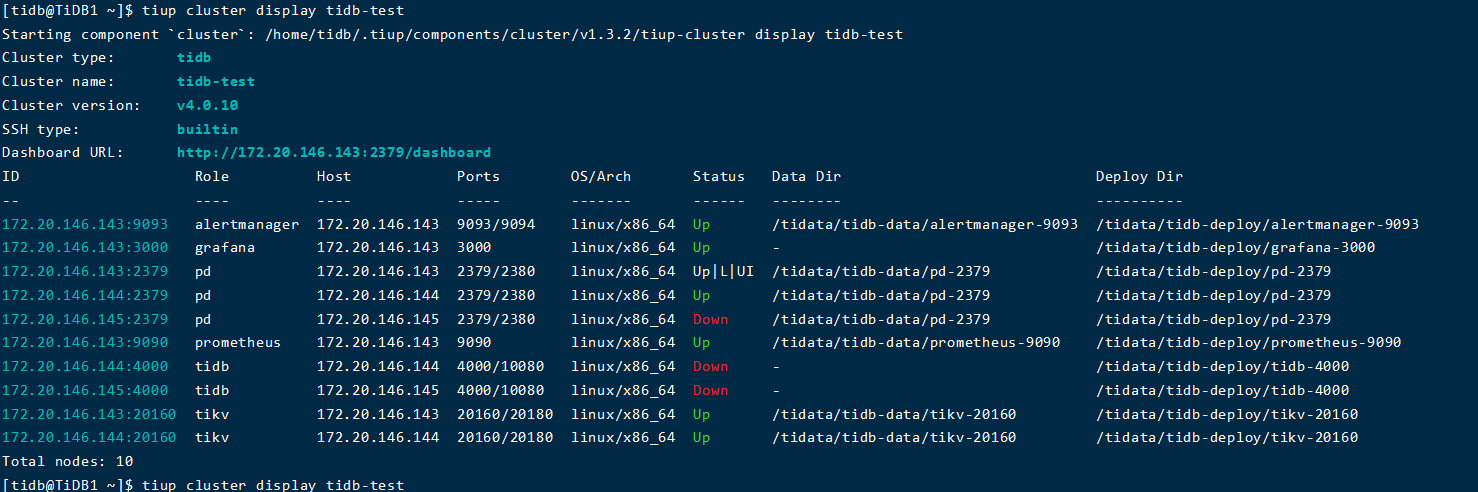
有个尴尬的问题,也没有干什么,不知道怎么回事,pd好像好了:joy:,现在只剩下tidb客户端启动不了

[2021/02/19 11:29:16.227 +08:00] [FATAL] [session.go:1980] [“check bootstrapped failed”] [error=“[tikv:9005]Region is unavailable”] [stack=“github.com/pingcap/tidb/session.getStoreBootstrapVersion
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/session/session.go:1980
github.com/pingcap/tidb/session.BootstrapSession
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/session/session.go:1765
main.createStoreAndDomain
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/tidb-server/main.go:258
main.main
\t/home/jenkins/agent/workspace/tidb_v4.0.10/go/src/github.com/pingcap/tidb/tidb-server/main.go:179
runtime.main
\t/usr/local/go/src/runtime/proc.go:203”]
你这是新部署的集群启动失败,还是老的集群做了什么操作后启动失败了。
还有你可以看一下 tikv 的日志有没有什么 error 日志信息
变又未变
(变又未变)
5
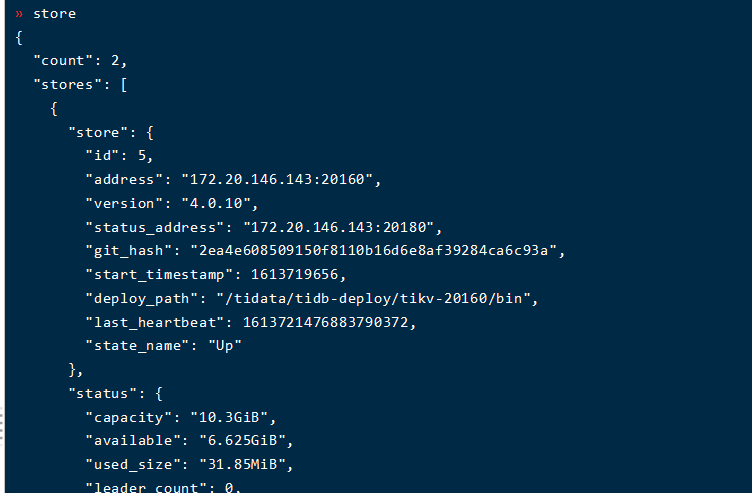
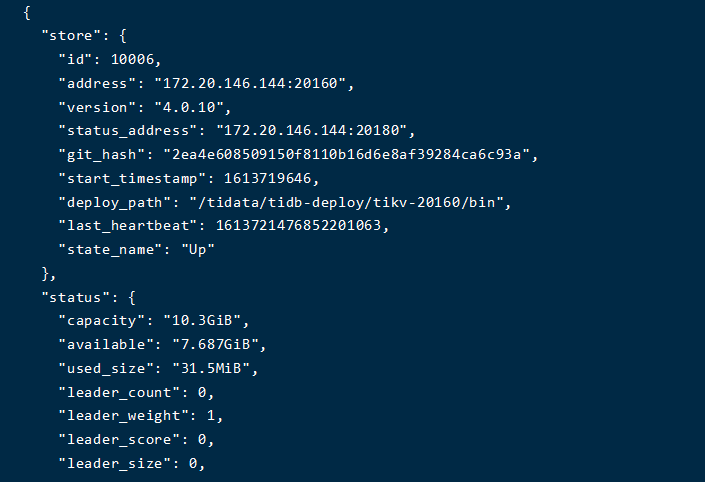
老的集群,昨天删除了144节点tidb-data下的pd和tikv相关目录,然后重新扩容了,以前145节点的tikv挂了后,强制缩容了,目前就是这个样的操作。之前145节点的tikv挂了强制缩容后,将集群stop后再start还是可以的,今天就出现了问题。。。。。tikv日志里面有error,最新报错:
因为从 3 个节点强制缩容成 1 个节点,所以 region 丢失了多数副本,导致 region 不可用,报 region is unavaible 。
多数副本丢失的情况下,不能保证剩余的副本拥有最新的数据。如果在极端情况下,允许有数据丢失的恢复可以参考下这两个链接:
https://book.tidb.io/session3/chapter5/recover-quorum.html#53-多数副本丢失数据恢复指南
https://asktug.com/t/topic/36199
或者是重新部署集群。
变又未变
(变又未变)
8
对了,我问一下:
1、我上午什么也没有干,pd的好了,这个是为什么?
2、tikv有问题,pd应该是可以启动的吧,pd不是在tikv之前启动的嘛?
我现在就是将原来状态为Offline的store下线掉, curl -X POST http://172.20.146.143:2379/pd/api/v1/store/4/state?state=Tombstone然后使用tiup cluster prune后,在重新启动集群,pd又启动不了,这个是?
变又未变
(变又未变)
9
在 TiKV 节点停机后在所有剩余健康的 tikv 节点执行这条命令 ./tikv-ctl --db {/path/to/tikv/db} unsafe-recover remove-fail-stores -s 5 --all-regions 操作成功之后再看下,应该是 region 残留的副本信息没有被清理干净导致的。
变又未变
(变又未变)
11
停机,是要把那个节点关机嘛?那个节点上我暂时还有pd和tidb服务,我直接在好的tikv节点上执行一下看一下
变又未变
(变又未变)
13
好的,那个可能在打扰一下,好的tikv节点也是要把tikv进程停掉,是吧!
没有 ca.pem、client.pem、client-key.pem,可以是使用这个方式嘛?
直接这么用?
tiup ctl tikv --host 127.0.0.1:20160 unsafe-recover remove-fail-stores -s 4,5 --all-regions
system
(system)
关闭
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。