Renne
(Hacker Ckfy Z Pda)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:4.0.0
- 【问题描述】:3台KV,其中一台因为系统崩溃重启后,leader几乎全部被转移到其他2个节点上,重启时间(约10分钟)没有超过默认的迁移时间:
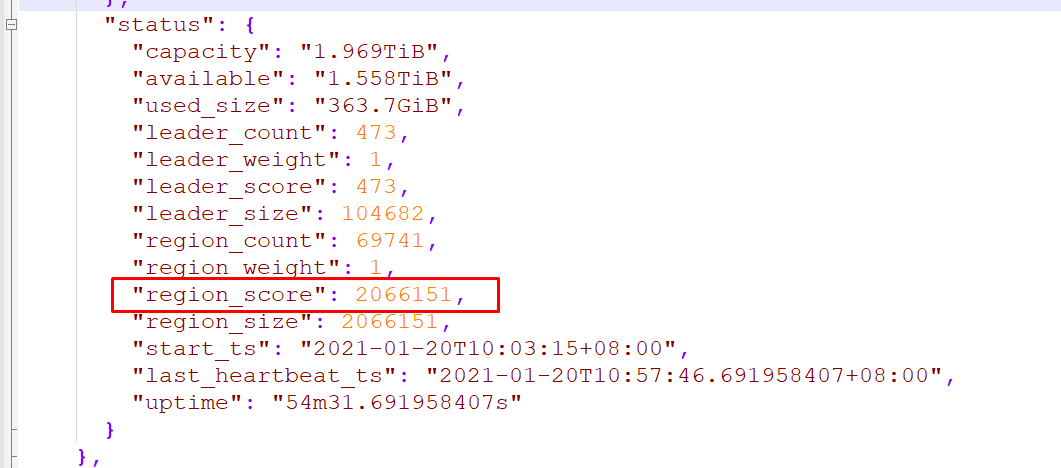
目前store的信息中,id=1的kv节点的评分很低:
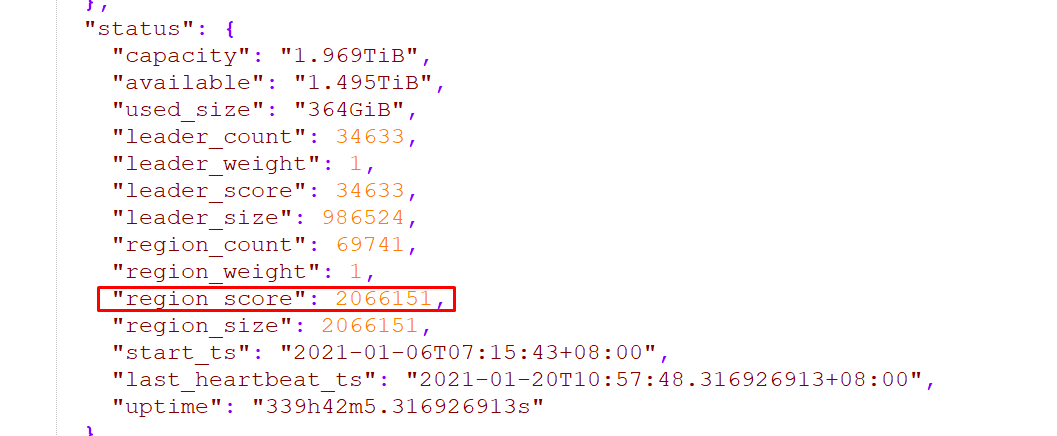
另外两个store的leader个数几乎一致,评分一致,3个kv的region count一致
operator的状态可以看到时不时有region leader的迁移,从正常kv到重启的kv,但时间很久了还是很少
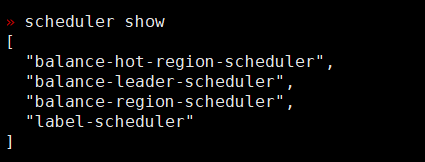
scheduler的状态中没有驱逐leader的状态:
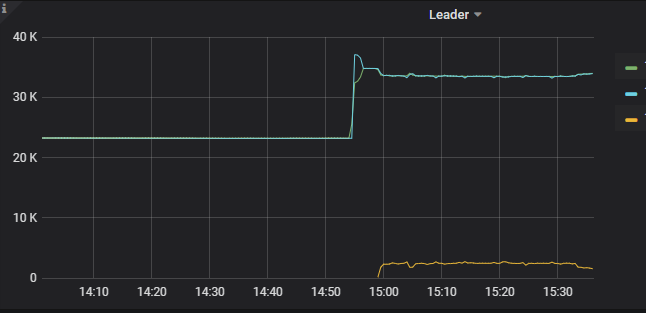
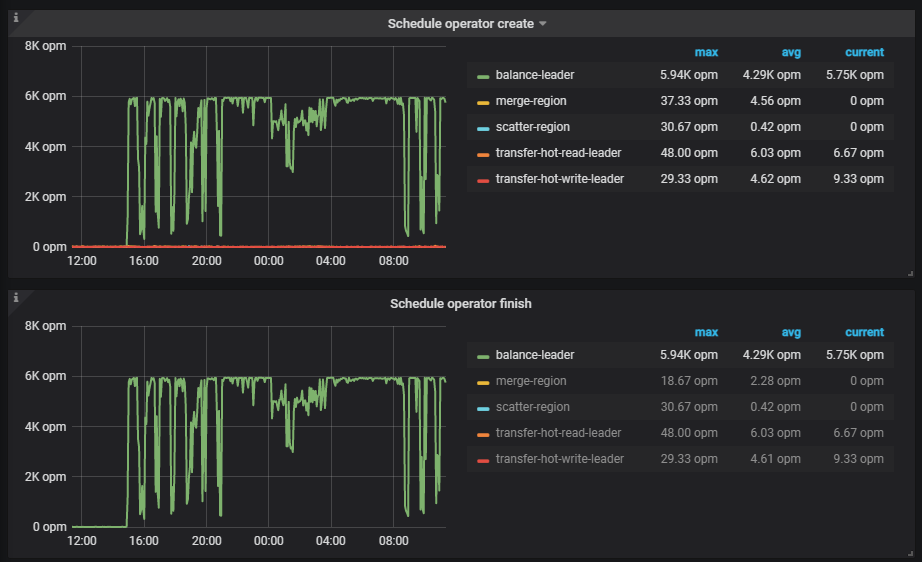
PD监控中看上去有大量迁移leader的操作,貌似step finish的时间也在正常范围内:
目前观察下来的现象是选举一直在进行,但是该kv除了变成一些region的leader,同时也变成另一些的follower,导致这台kv整体的leader几乎不上升
想请问下这种情况应该怎么再次平衡leader,因为之前kv意外宕机恢复后都能重新平衡,这次不行了,是否需要重启全部kv节点?谢谢!
不懂就问
(zhouyueyue)
4
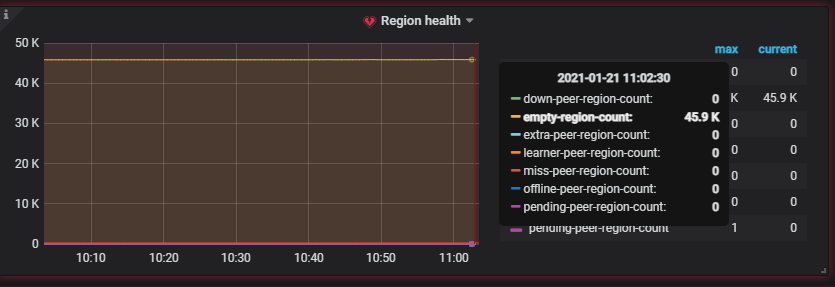
根据监控看 balance leader 的操作一直有,另外也有 7->1,4->1 的 balance leader 操作,同时集群里面空 region 很多,有 46K 左右,以及热点的调度也很明显,建议先调大空 region (46K)的 merge 参数。至于 store 1 上面的 leader 数量跟其他 store 差距很大,可以等空 region merge 之后在观察下。
不懂就问
(zhouyueyue)
6
Renne
(Hacker Ckfy Z Pda)
7
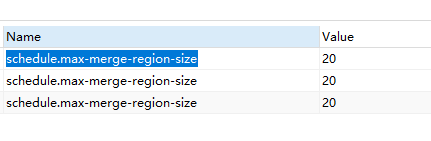
麻烦再问下老师,昨天将
schedule.max-merge-region-size从20改为40,
schedule.max-merge-region-keys从200000改为400000,
schedule.patrol-region-interval从100ms改为’50ms’后,空region几乎没有下降:
我们平时的逻辑是truncate 300多张表再导入同步的数据,每小时一轮进行loop
根据其他帖子老师的回答,空region最终都会被merge掉,但是过多的空region会影响群集的查询性能
那么我们这个case里面8W个region一半多都是标记为空的,是否需要继续加大上面三个参数进行合并?
不懂就问
(zhouyueyue)
8
如果是因为不断 truncate 表产生的空 region ,那么调整上面的参数是无效的,必须要设置 table 级别的合并参数,在上面的链接里有提到
另外对于 leader 分布不均衡的问题,上面的链接里也有解答,辛苦参考排查下,如果还有问题,欢迎提问。
2 个赞
Renne
(Hacker Ckfy Z Pda)
9
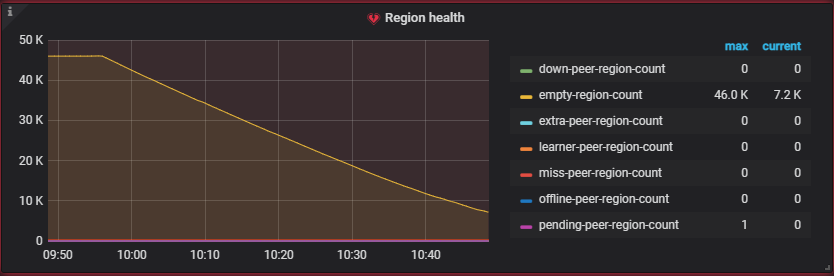
感谢老师,维持key-type=table,将schedule.enable-cross-table-merge改为true后,空region merge明显:innocent:
不懂就问
(zhouyueyue)
10
merge 完关注下 leader 分布情况,同时可以参考文档调整下。
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。



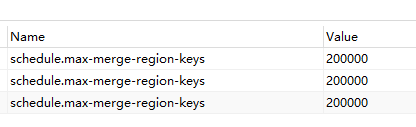
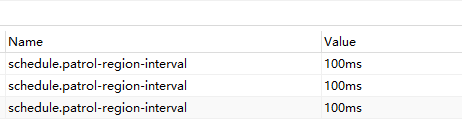 这几个吗
这几个吗