为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
- 【问题描述】:
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
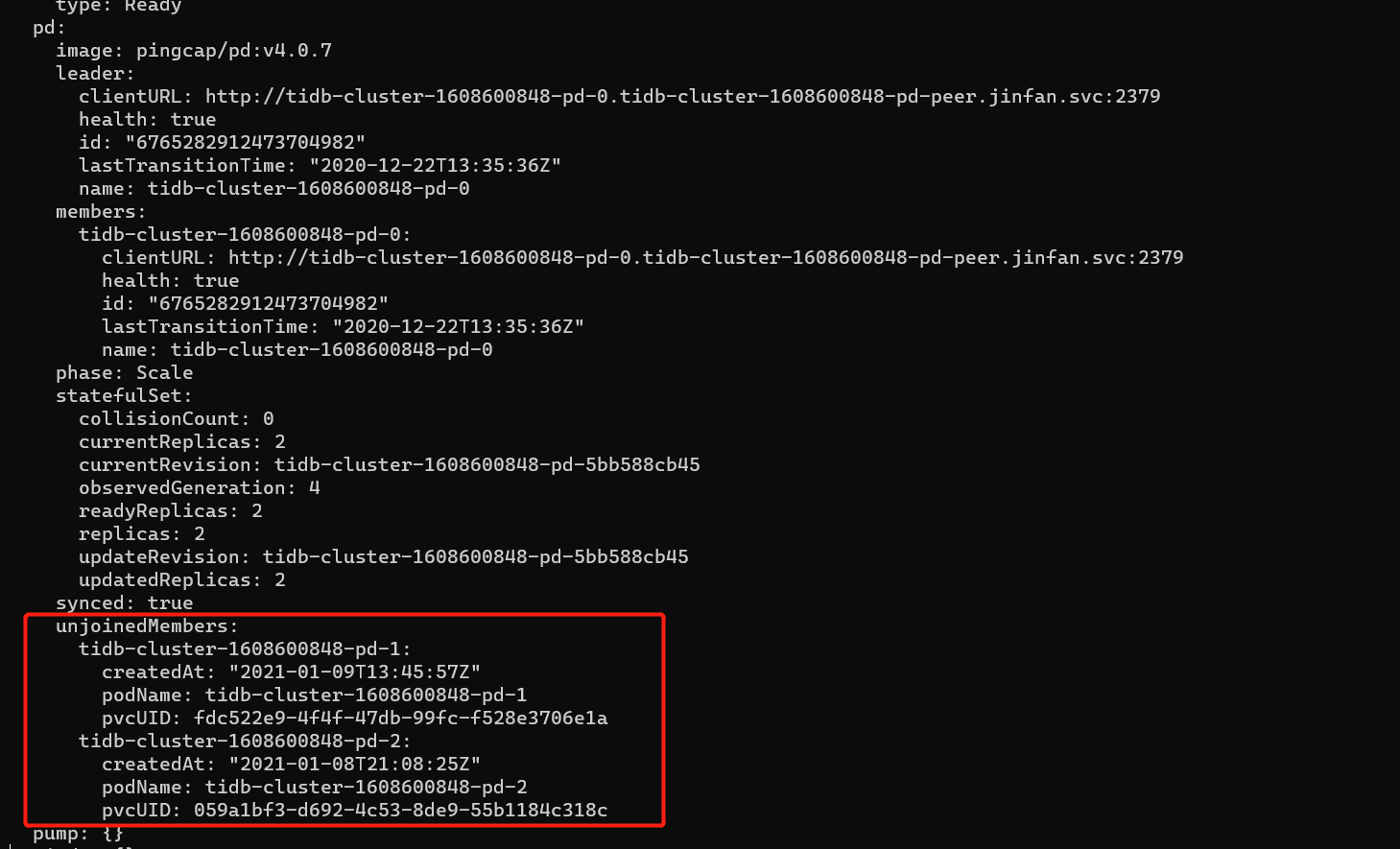
缩容后,删除的pd在tidbcluster中变成了unjoinedMembers,现在我想再进行扩容,发现扩容不了,即使把pv和pvc删掉,重新格式化后扩容也不行了。
1.pd-ctl 看当前 member 信息
{
"header": {
"cluster_id": 6916490224968328765
},
"members": [
{
"name": "tidb-cluster-1608600848-pd-0",
"member_id": 11528851186513975627,
"peer_urls": [
"http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2380"
],
"client_urls": [
"http://tidb-cluster-1608600848-pd-0.tidb-cluster-1608600848-pd-peer.jinfan.svc:2379"
],
"deploy_path": "/",
"binary_version": "v4.0.7",
"git_hash": "8b0348f545611d5955e32fdcf3c57a3f73657d77"
}
],
"leader": {
"name": "tidb-cluster-1608600848-pd-0",
"member_id": 11528851186513975627,
"peer_urls": [
"http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2380"
],
"client_urls": [
"http://tidb-cluster-1608600848-pd-0.tidb-cluster-1608600848-pd-peer.jinfan.svc:2379"
]
},
"etcd_leader": {
"name": "tidb-cluster-1608600848-pd-0",
"member_id": 11528851186513975627,
"peer_urls": [
"http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2380"
],
"client_urls": [
"http://tidb-cluster-1608600848-pd-0.tidb-cluster-1608600848-pd-peer.jinfan.svc:2379"
],
"deploy_path": "/",
"binary_version": "v4.0.7",
"git_hash": "8b0348f545611d5955e32fdcf3c57a3f73657d77"
}
}
2.kubectl get pod -n -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tidb-cluster-1608600848-discovery-5df69cc7cd-vf7mk 1/1 Running 0 3h8m 10.244.2.41 k8s-node02 <none> <none>
tidb-cluster-1608600848-monitor-699bbf5875-rdl49 3/3 Running 0 3h8m 10.244.1.55 k8s-node01 <none> <none>
tidb-cluster-1608600848-pd-0 1/1 Running 0 19m 10.244.1.66 k8s-node01 <none> <none>
tidb-cluster-1608600848-pd-1 1/1 Running 5 5m58s 10.244.2.51 k8s-node02 <none> <none>
tidb-cluster-1608600848-tidb-0 2/2 Running 0 174m 10.244.1.62 k8s-node01 <none> <none>
tidb-cluster-1608600848-tidb-1 2/2 Running 0 173m 10.244.0.51 k8s-master01 <none> <none>
tidb-cluster-1608600848-tikv-0 1/1 Running 0 3h4m 10.244.2.47 k8s-node02 <none> <none>
tidb-cluster-1608600848-tikv-1 1/1 Running 0 3h1m 10.244.1.61 k8s-node01 <none> <none>
tidb-cluster-1608600848-tikv-2 1/1 Running 0 3h1m 10.244.0.50 k8s-master01 <none> <none>
3.kubectl logs -njinfan tidb-cluster-1608600848-pd-1
Name: tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc
Address 1: 10.244.2.51 tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc.cluster.local
nslookup domain tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc.svc success
starting pd-server ...
/pd-server --data-dir=/var/lib/pd --name=tidb-cluster-1608600848-pd-1 --peer-urls=http://0.0.0.0:2380 --advertise-peer-urls=http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2380 --client-urls=http://0.0.0.0:2379 --advertise-client-urls=http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2379 --config=/etc/pd/pd.toml --join=http://tidb-cluster-1608600848-pd-1.tidb-cluster-1608600848-pd-peer.jinfan.svc:2379
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:42] ["Welcome to Placement Driver (PD)"]
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:43] [PD] [release-version=v4.0.7]
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:44] [PD] [edition=Community]
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:45] [PD] [git-hash=8b0348f545611d5955e32fdcf3c57a3f73657d77]
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:46] [PD] [git-branch=heads/refs/tags/v4.0.7]
[2021/01/11 18:03:22.938 +00:00] [INFO] [util.go:47] [PD] [utc-build-time="2020-09-29 06:52:41"]
[2021/01/11 18:03:22.938 +00:00] [INFO] [metricutil.go:81] ["disable Prometheus push client"]
[2021/01/11 18:03:22.938 +00:00] [FATAL] [main.go:94] ["join meet error"] [error="join self is forbidden"] [stack="github.com/pingcap/log.Fatal\
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.7/go/pkg/mod/github.com/pingcap/log@v0.0.0-20200511115504-543df19646ad/global.go:59\
main.main\
\t/home/jenkins/agent/workspace/build_pd_multi_branch_v4.0.7/go/src/github.com/pingcap/pd/cmd/pd-server/main.go:94\
runtime.main\
\t/usr/local/go/src/runtime/proc.go:203"]
1.pd的replicas是3
2.有报错日志,比较多,我截取最后一部分吧
kubectl logs -ntidb-admin tidb-controller-manager-6fc84b4c-rz8lp
E0111 18:53:04.523910 1 tidb_cluster_controller.go:123] TidbCluster: jinfan/tidb-cluster-1608600848, sync failed TidbCluster: jinfan/tidb-cluster-1608600848's pd 1/2 is ready, can't scale out now, requeuing
I0111 18:54:53.898897 1 pd_scaler.go:55] scaling out pd statefulset jinfan/tidb-cluster-1608600848-pd, ordinal: 2 (replicas: 3, delete slots: [])
I0111 18:54:53.898983 1 scaler.go:74] Cluster jinfan/tidb-cluster-1608600848 list pvc not found, selector: app.kubernetes.io/instance=tidb-cluster-1608600848,app.kubernetes.io/managed-by=tidb-operator,app.kubernetes.io/name=tidb-cluster,tidb.pingcap.com/pod-name=tidb-cluster-1608600848-pd-2
I0111 18:54:53.917769 1 tidbcluster_control.go:66] TidbCluster: [jinfan/tidb-cluster-1608600848] updated successfully
E0111 18:54:53.917807 1 tidb_cluster_controller.go:123] TidbCluster: jinfan/tidb-cluster-1608600848, sync failed TidbCluster: jinfan/tidb-cluster-1608600848's pd 1/2 is ready, can't scale out now, requeuing
I0111 18:54:53.982001 1 pd_scaler.go:55] scaling out pd statefulset jinfan/tidb-cluster-1608600848-pd, ordinal: 2 (replicas: 3, delete slots: [])
I0111 18:54:53.982093 1 scaler.go:74] Cluster jinfan/tidb-cluster-1608600848 list pvc not found, selector: app.kubernetes.io/instance=tidb-cluster-1608600848,app.kubernetes.io/managed-by=tidb-operator,app.kubernetes.io/name=tidb-cluster,tidb.pingcap.com/pod-name=tidb-cluster-1608600848-pd-2
I0111 18:54:54.004512 1 tidbcluster_control.go:66] TidbCluster: [jinfan/tidb-cluster-1608600848] updated successfully
E0111 18:54:54.004553 1 tidb_cluster_controller.go:123] TidbCluster: jinfan/tidb-cluster-1608600848, sync failed TidbCluster: jinfan/tidb-cluster-1608600848's pd 1/2 is ready, can't scale out now, requeuing
kubectl logs -ntidb-admin tidb-scheduler-594c78f746-wsx59 tidb-scheduler
I0111 17:41:18.754090 1 ha.go:357] update PVC: [jinfan/pd-tidb-cluster-1608600848-pd-0] successfully, TidbCluster: tidb-cluster-1608600848
I0111 17:41:18.754121 1 ha.go:324] ha: delete pvc jinfan/pd-tidb-cluster-1608600848-pd-0 annotation tidb.pingcap.com/pod-scheduling successfully
I0111 17:41:18.757541 1 ha.go:357] update PVC: [jinfan/pd-tidb-cluster-1608600848-pd-1] successfully, TidbCluster: tidb-cluster-1608600848
I0111 17:41:18.757567 1 ha.go:401] ha: set pvc jinfan/pd-tidb-cluster-1608600848-pd-1 annotation tidb.pingcap.com/pod-scheduling to 2021-01-11T17:41:18Z successfully
I0111 17:41:18.761652 1 scheduler.go:131] leaving predicate: HAScheduling, nodes: [k8s-master01]
I0111 17:43:26.694870 1 scheduler.go:126] scheduling pod: jinfan/tidb-cluster-1608600848-pd-0
I0111 17:43:26.694912 1 scheduler.go:129] entering predicate: HAScheduling, nodes: [k8s-node01]
I0111 17:43:26.712275 1 ha.go:357] update PVC: [jinfan/pd-tidb-cluster-1608600848-pd-0] successfully, TidbCluster: tidb-cluster-1608600848
I0111 17:43:26.712301 1 ha.go:401] ha: set pvc jinfan/pd-tidb-cluster-1608600848-pd-0 annotation tidb.pingcap.com/pod-scheduling to 2021-01-11T17:43:26Z successfully
I0111 17:43:26.714641 1 scheduler.go:131] leaving predicate: HAScheduling, nodes: [k8s-node01]
I0111 17:59:47.470556 1 scheduler.go:126] scheduling pod: jinfan/tidb-cluster-1608600848-pd-1
I0111 17:59:47.470593 1 scheduler.go:129] entering predicate: HAScheduling, nodes: [k8s-master01 k8s-node02]
I0111 17:59:47.487878 1 ha.go:357] update PVC: [jinfan/pd-tidb-cluster-1608600848-pd-1] successfully, TidbCluster: tidb-cluster-1608600848
I0111 17:59:47.487905 1 ha.go:401] ha: set pvc jinfan/pd-tidb-cluster-1608600848-pd-1 annotation tidb.pingcap.com/pod-scheduling to 2021-01-11T17:59:47Z successfully
I0111 17:59:47.500117 1 ha.go:123] ha: tidbcluster jinfan/tidb-cluster-1608600848 component pd replicas 3
I0111 17:59:47.500141 1 ha.go:131] current topology key: kubernetes.io/hostname
I0111 17:59:47.502830 1 ha.go:169] pod tidb-cluster-1608600848-pd-0 is not bind
I0111 17:59:47.502851 1 ha.go:169] pod tidb-cluster-1608600848-pd-1 is not bind
I0111 17:59:47.502872 1 scheduler.go:131] leaving predicate: HAScheduling, nodes: [k8s-master01 k8s-node02]
kubectl logs -ntidb-admin tidb-scheduler-594c78f746-wsx59 kube-scheduler
I0111 17:01:47.253897 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:01:47.264478 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:01:50.076275 1 scheduler.go:597] "Successfully bound pod to node" pod="jinfan/tidb-cluster-1608600848-pd-1" node="k8s-master01" evaluatedNodes=3 feasibleNodes=1
I0111 17:38:36.720647 1 scheduler.go:597] "Successfully bound pod to node" pod="jinfan/tidb-cluster-1608600848-pd-0" node="k8s-node01" evaluatedNodes=3 feasibleNodes=1
I0111 17:41:18.766745 1 scheduler.go:597] "Successfully bound pod to node" pod="jinfan/tidb-cluster-1608600848-pd-1" node="k8s-master01" evaluatedNodes=3 feasibleNodes=1
I0111 17:43:26.719619 1 scheduler.go:597] "Successfully bound pod to node" pod="jinfan/tidb-cluster-1608600848-pd-0" node="k8s-node01" evaluatedNodes=3 feasibleNodes=1
I0111 17:57:22.566480 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:57:22.644277 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:58:31.174920 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:59:14.236038 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims."
I0111 17:59:37.339404 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 node(s) didn't find available persistent volumes to bind."
I0111 17:59:37.350504 1 factory.go:445] "Unable to schedule pod; no fit; waiting" pod="jinfan/tidb-cluster-1608600848-pd-1" err="0/3 nodes are available: 3 node(s) didn't find available persistent volumes to bind."
I0111 17:59:47.506483 1 scheduler_binder.go:493] claim "jinfan/pd-tidb-cluster-1608600848-pd-1" bound to volume "local-pv-9e9eb2ef"
I0111 17:59:48.516665 1 scheduler.go:597] "Successfully bound pod to node" pod="jinfan/tidb-cluster-1608600848-pd-1" node="k8s-node02" evaluatedNodes=3 feasibleNodes=2
3.pd-1de running只能维持一段时间后CrashLoopBackOff。
4.一开始是只改了pd.spec.relicas,后来因为有问题,我还尝试了改pd.spec.maxFailoverCount,还有改过pd在statefulsets中的replicas,statefulsets中的replicas是不是不能随意改动。
抱歉,目前看很多都不一致,sts之类的是不能修改的,感觉没有什么好的方法。 如果可以的话,试试能否导出数据,重建集群,再导入,多谢。
![]()