课程名称:课程版本(301)+ 3.2.2 TiDB Cluster Operation(K8s 部署的 TiDB 集群运维)
学习时长:
60 min
课程收获:
学习在 Kubernetes 集群上管理 TiDB 集群,包括配置,升级,扩缩容,Failover 等,以及查看日志,查看集群状态,重启组件 Pod,备份,恢复和监控等等。
课程内容:
Configure


- 可以直接修改Yaml来配置
- kubectl apply -f tidb-cluster.yaml 来保存配置
- 存在浮点数处理的问题,所以提供TOML的配置文件
- 将配置以TOML的形式放在文件目录下即可自动识别
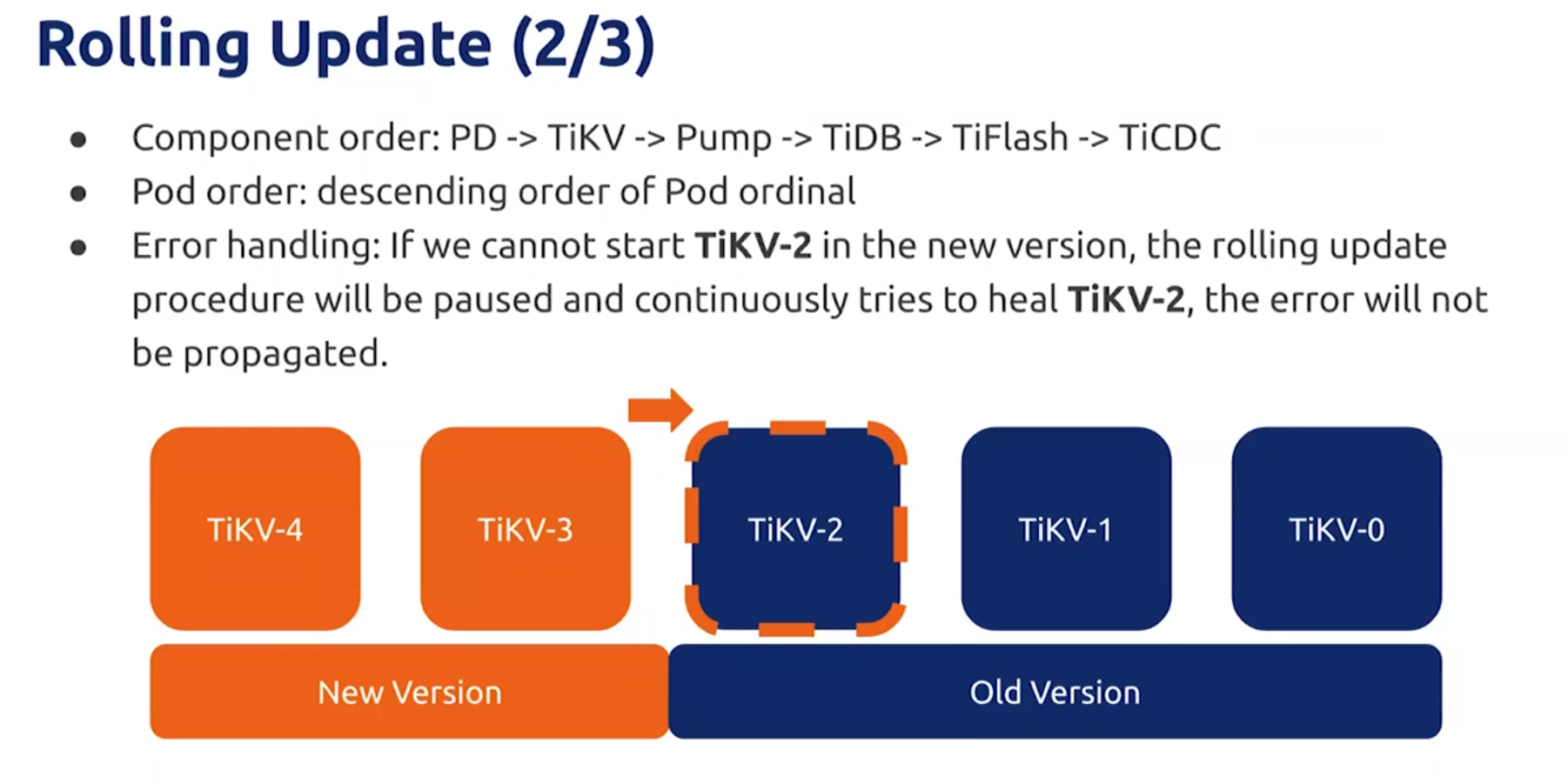
Rollong Update
-
版本升级
-
修改集群配置
-
滚动升级的过程无法使用K8s原生的,原生的会直接删除在新增
-
自定义 tidb-controller-manager 一个一个迁移再升级
-
升级过程为倒叙
-
某一个POD升级失败则会停止
-
TiDB update过程会影响请求,client需要能够重试保证升级过程中减小影响

Horizontal Scaling
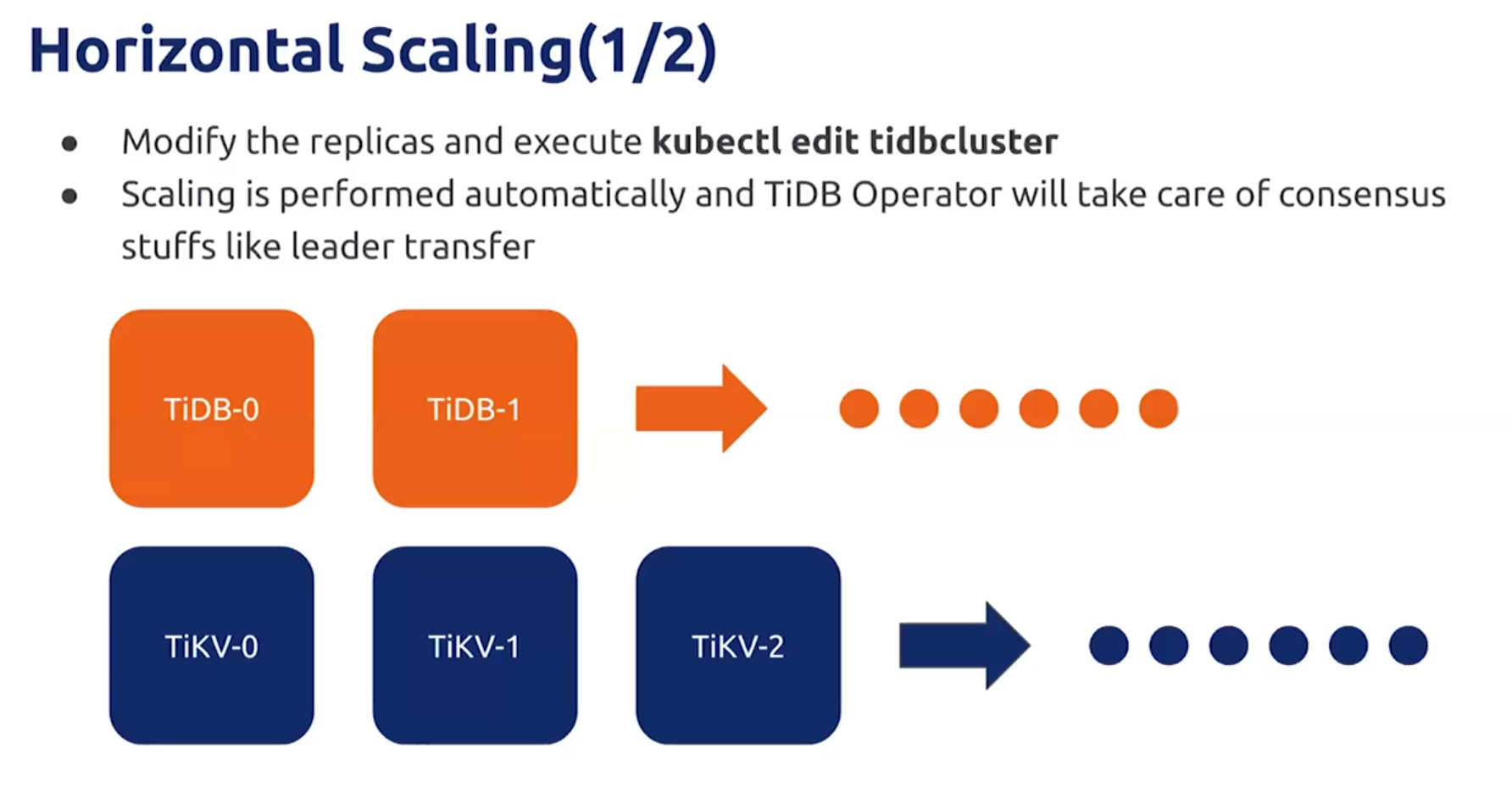

- kubectl edit tidbcluster 修改TiDB配置
- 使用TiDB Operator来完成
- 要清除旧的数据
- 缩容不是简单的删除就可以,需要先通知,然后再删除
- 缩容要做数据迁移需要费时
- max-replicas 配置为多少时,无法缩到比这更小
Vertical Scaling
- 增大 resources
- 原生就支持可扩展性,所以建议水平扩缩
- 垂直升级要确保有足够的resources 支持
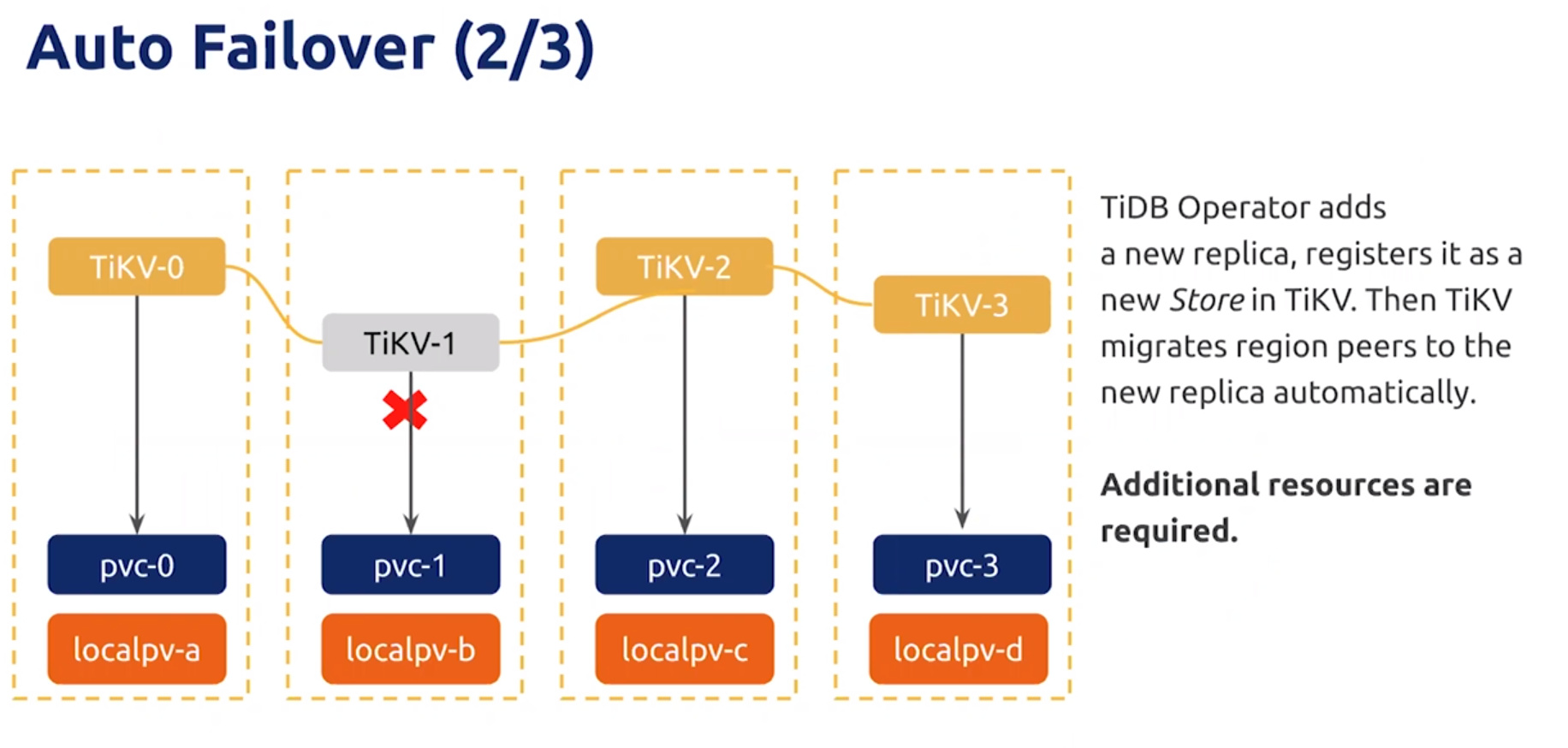
Auto Failover
-
检查到pod挂了不会直接新起,因为要保证pod name的唯一性
-
所以自己实现了一个Failover,根据状态新启Pod,然后待修复后,删除掉新启的Pod
-
需要有额外的resources ,不然新启的pod因为没有资源而一直处于pending
-
对于PD 和 TiDB 不用进行数据迁移
-
对于TiDB 和 TiFlash 需要数据迁移,会有时间和性能的消耗,需要手动控制更好
Restart TiDB cluster

- 为需要重启的组件进行注释
- 需要执行 kubectl edit tc ${cluster_name} -n ${namespace} 在CR中添加注释
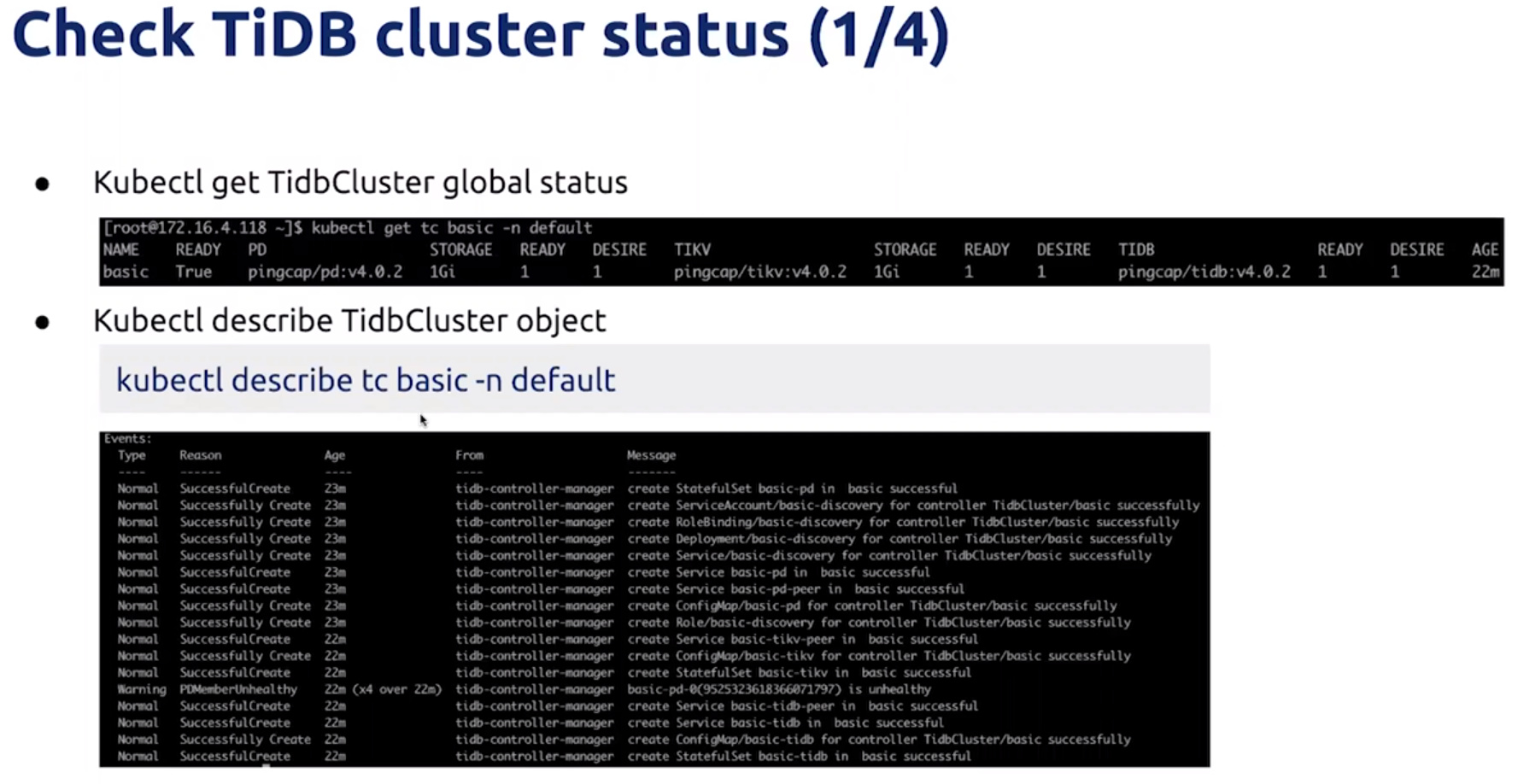
Cluster status

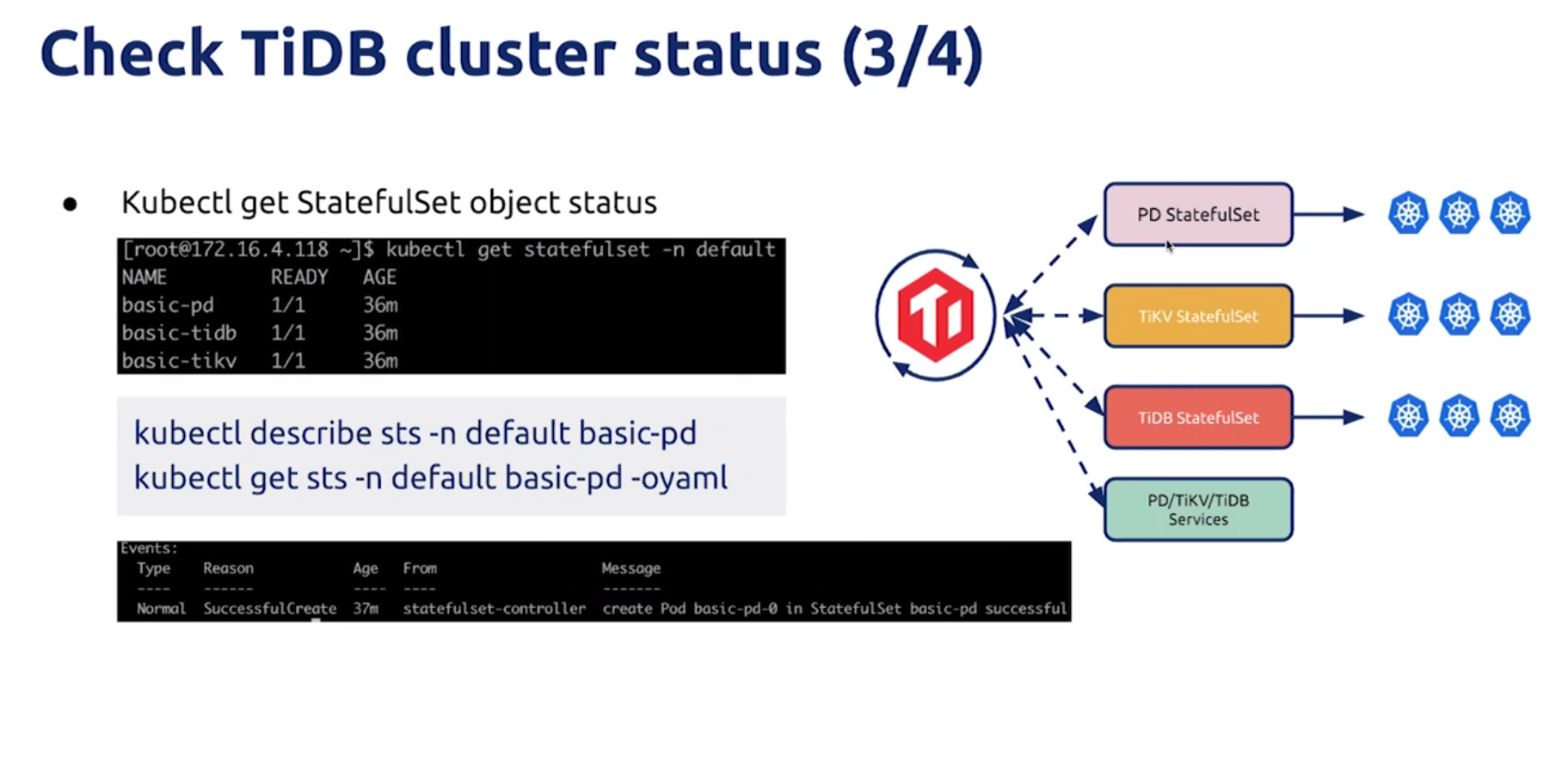
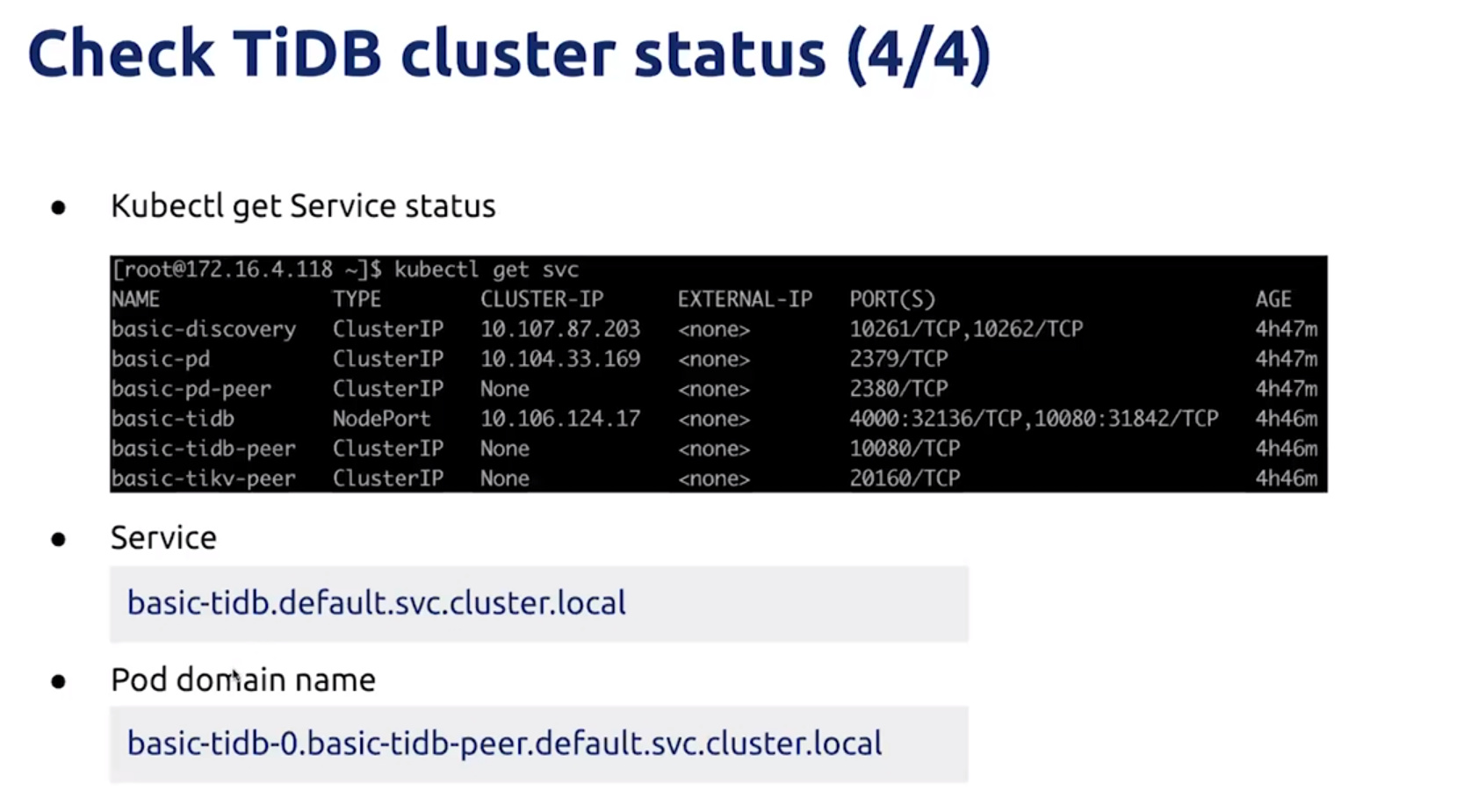
cluster log
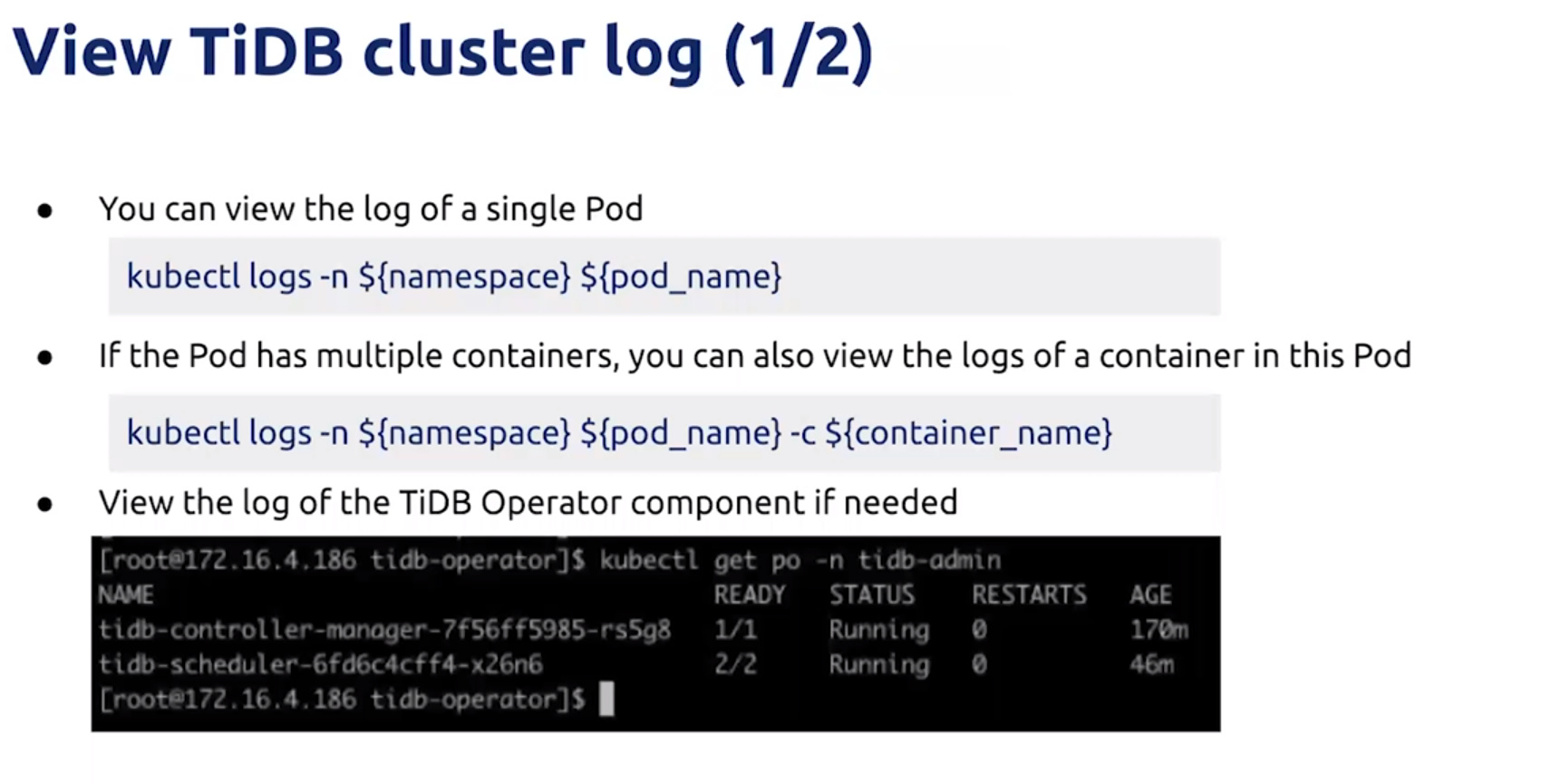

Backup and Restore
- TiDB Operator 支持全量和增量两种
- Operator 主要通过CR来完成
- BR 可以同事支持备份和恢复
- v1.1以后开始转向了CRD
Back up data to S3 through BR


Back p data to S3 through Dumpling

- 备份数据先上PVC 再从PVC读到S3
Restore data from S3 through BR

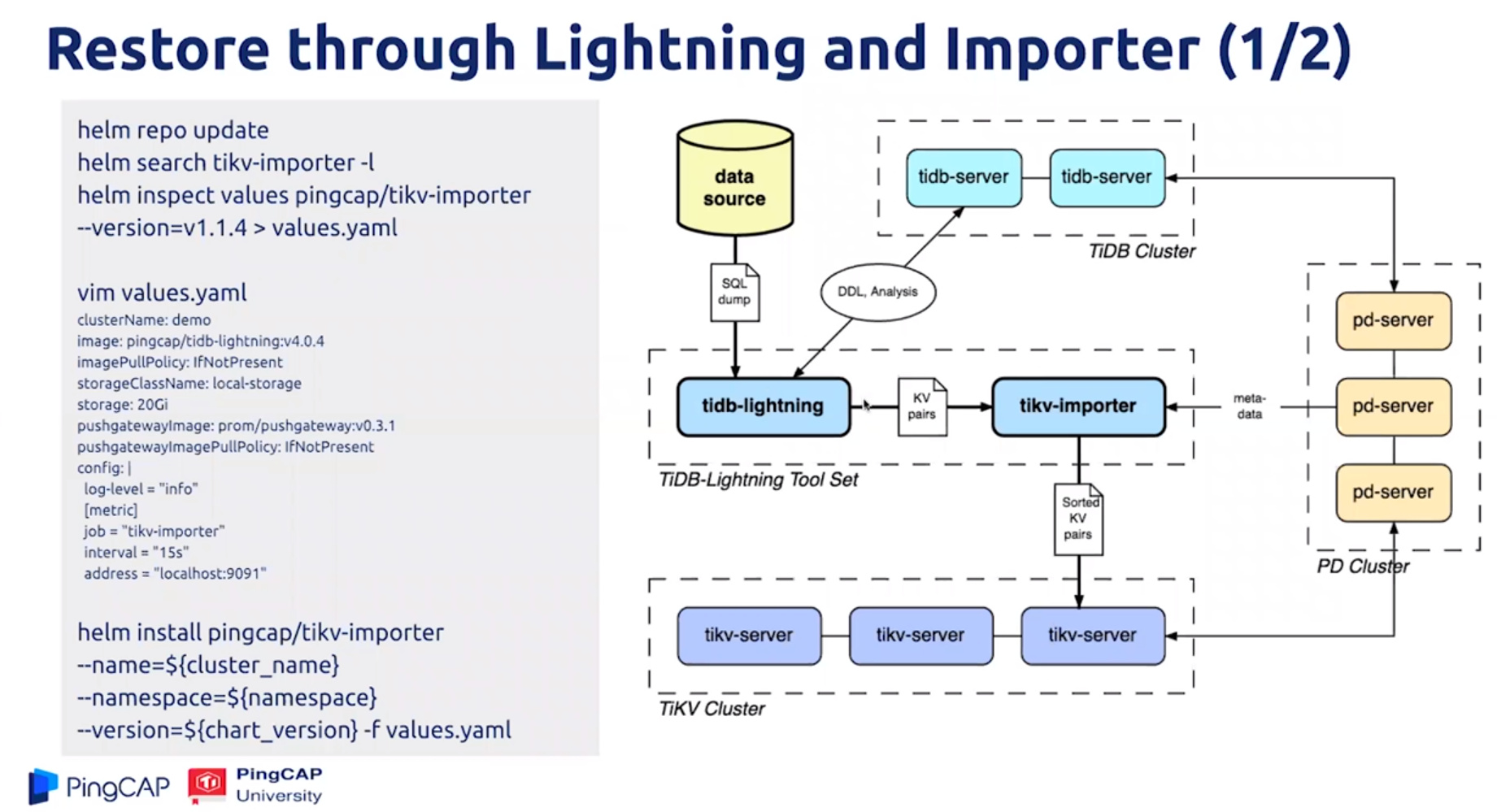
Restore data from S3 through Lightning

- 先拉到PVC,再读到 Lightning
Restore through Lightning and Importer

Monitor

学习过程中遇到的问题或延伸思考:
无