yssky
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.3.0
【遇到的问题】tikv 1个节点状态为down,无法启动
【复现路径】./tikv-ctl --data-dir /data1/tidb-data/tikv-20160 bad-regions查看有bad-regions,查看grep panic /home/tidb-deploy/tikv-20160/log/tikv.log | grep region|grep -oP ‘region [0-9]*’|sort|uniq -c 查看有bad-regions
【问题现象及影响】SQL查询提示Region is Unavailable
yssky
3
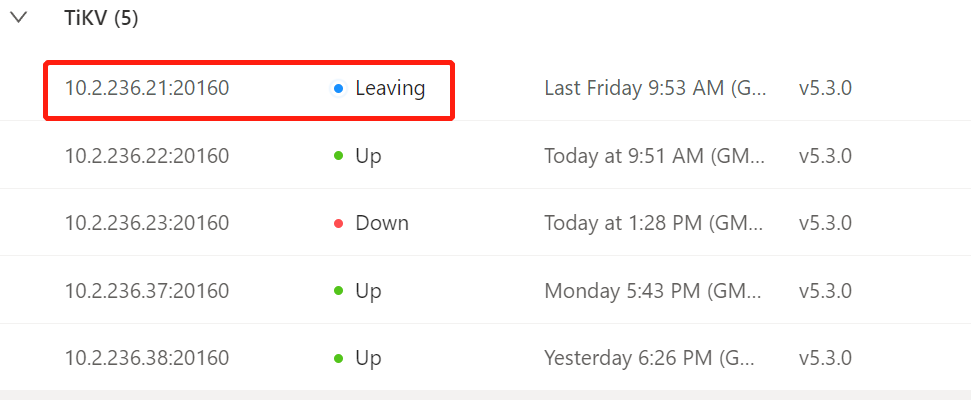
还有一台tikv故障使用–force缩容后,store id还在,无法清理干净。
监控一直显示leaving,无法清理干净。
用pd-ctl store delete看能否删掉
yssky
5
使用store delete显示删除成功,再次查询仍然存在,无法删除
h5n1
(H5n1)
6
tikv节点正常转换状态,开始scale-in -->offline(转移leader和region到其他节点)–>转移完成变为tombone store,之后使用tiup cluster prune清理。
估计是21这个节点强制缩容,之后23节点又故障后导致出现多副本失败,可以参考下面2个文档用Unsafe-recvoer 强制恢复下
yssky
7
如何确认“多副本失败”状态?再执行您提到的两篇文章进行操作。
leader情况:
yssky
9
帮忙看一下监控显示的leader情况是不是不正常?正常是只有1个对吗?
h5n1
(H5n1)
10
N副本下,一个region只有一个leader,N-1个follower, 有tiflash还有m个leaner
yssky
13
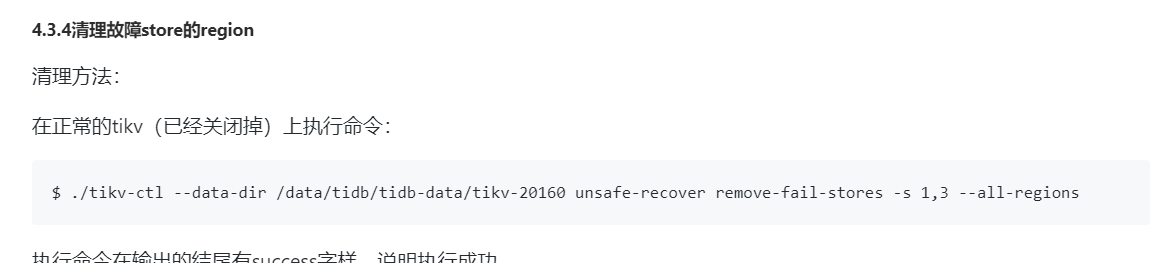
执行清理脚本,反复执行,都没有看到success。
假设挂掉的store的id是1和2,则使用如下方式确定是否有region的多数派副本位于这2个store上
pd-ctl region --pd <pd_ip:2379> --jq=’.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(1,2) then . else empty end) | length>=$total-length) }’
yssky
15
查询出是1,4,5。其中1是清理后的残余,5是现在状态是down的。
那就要把所有tikv全部停掉,然后在健康的tikv实例上执行unsafe-recover,删掉1和5这两个store上的所有peer
h5n1
(H5n1)
18
-s 后面是你有问题的2个store ,down和已经下线的
system
(system)
关闭
19
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。