生产环境
tidb版本:v5.0.6
问题:
出现大量的empty-region-count,调整参数后又慢慢回升,数据库中的空region数量有减少,但是太慢了,请问如何调整?
参考官方以及论坛文档:调整了以下参数
pd:
enable-cross-table-merge": “true”
“merge-schedule-limit”: 128
“patrol-region-interval”: “10ms”
tikv:
coprocessor.split-region-on-table: false
pd完整配置:
数据库查询空region的数量
2 个赞
先确认是什么操作引起的,大量的delete,truncate? 如果是正常的,调整max-merge-region-size, max-merge-region-keys 调整为较小值来加快 Merge 速度
2 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
3
有對一張40亿的数据表做了 truncate table xxx
但是不确定是这个操作导致的,因为扩容服务器,增加了两台kv发现一个礼拜还没完成reblance 才注意到
现在 参数
{
“replication”: {
“enable-placement-rules”: “true”,
“isolation-level”: “”,
“location-labels”: “”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“enable-cross-table-merge”: “true”,
“enable-debug-metrics”: “false”,
“enable-joint-consensus”: “true”,
“enable-location-replacement”: “false”,
“enable-make-up-replica”: “true”,
“enable-one-way-merge”: “false”,
“enable-remove-down-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“high-space-ratio”: 0.7,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 128,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 8000,
“max-merge-region-size”: 2,
“max-pending-peer-count”: 2147483647,
“max-snapshot-count”: 64,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 128,
“patrol-region-interval”: “10ms”,
“region-schedule-limit”: 2048,
“region-score-formula-version”: “”,
“replica-schedule-limit”: 128,
“scheduler-max-waiting-operator”: 5,
“split-merge-interval”: “1h0m0s”,
“store-limit-mode”: “manual”,
“tolerant-size-ratio”: 0
}
}
感觉没有效果,没有什么变化
2 个赞
可以看下pd监控 operator 看下merge region的执行
2 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
6
请问有空帮忙看下吗?比较着急,扩容两台服务器,然后本来准备缩容一台配置低一点的
现在不敢动了…
2 个赞
你现在的集群主要是在做region balance ,等region balance 结束后,region merge就会快了,这是优先级的问题,你现在需要什么?
2 个赞
张雨齐0720
(Zhangjig)
8
可能是合并空region的参数开太小了。线上使用资源不高的情况下,扩大合并的并发数吧
2 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
9
region balance 已经持续一周了 ,而且rebalance过程中,kv一段时间就OOM
然后导致这个不断地重复整个reblance过程,我们担心这个reblance 似乎没有完成的机会
1 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
10
我的参数调整已经挺高的了吧? 您这边有建议调整哪个并发数吗
1 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
11
我大概描述一下,
原本是 6个KV,磁盘是 1.6TB,磁盘使用率大概是 70%, 64G/24Core
现在准备更换新机器,就是 用 6.4TB磁盘 + 128G/24Core 的服务器
首先我们先扩容2个节点上去,然后准备等他reblance完成后,缩容旧的这6个kv
然后现在是reblance 持续了一周,然后最近三天好像没什么进展
观测到不断有KV节点OOM, 然后这个 Leader 就不断循环
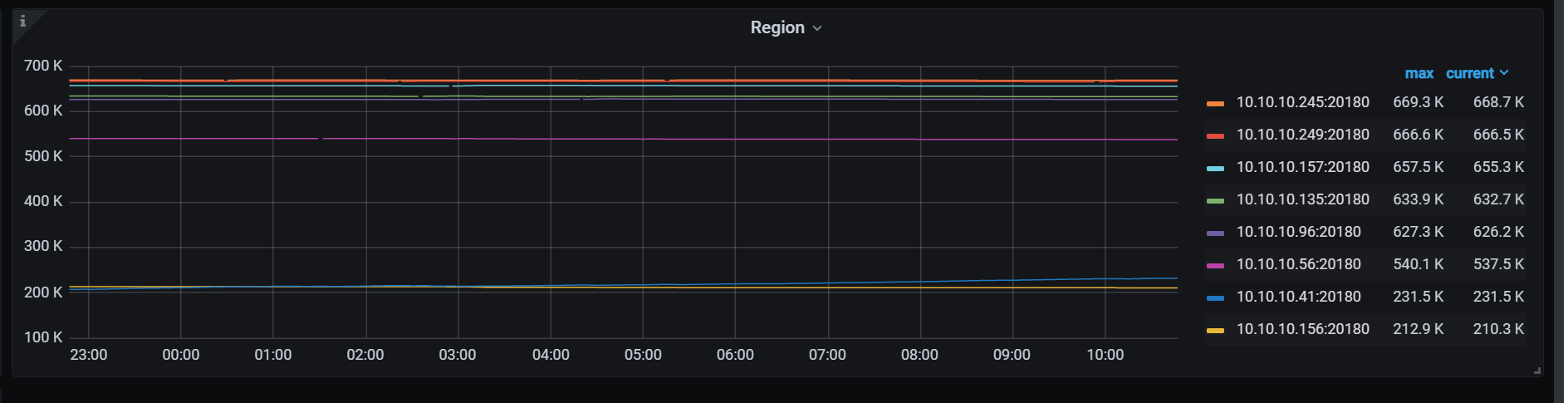
这是12小时内的Leader的变化
12小时内 region的变化
1 个赞
看下 high-space-ratio low-space-ratio 参数的值
1 个赞
"low-space-ratio": 0.8,
"high-space-ratio": 0.7,
1 个赞
建议你调整参数,由于已经使用的70%,region balace 不会调度到对应节点,这可能导致你现在的问题。可以对应调整到"low-space-ratio": 0.85,
“high-space-ratio”: 0.8,
1 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
16
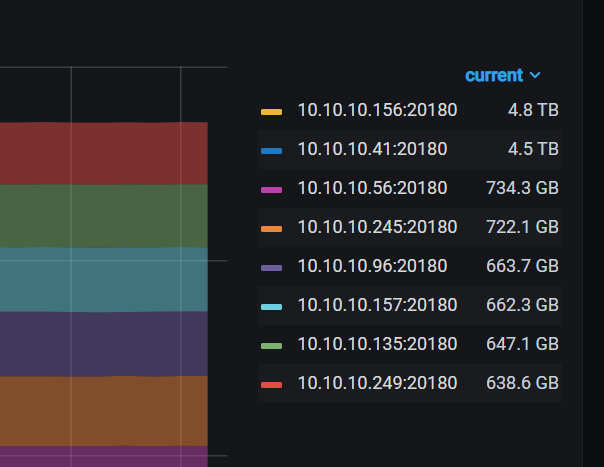
没增加节点之前,我们是 70%左右
41和 156是新增节点,现在就感觉reblance好几天没有进展了
现在节点可用磁盘 是这样:
1 个赞
h5n1
(H5n1)
17
1、 oom的tikv看看内存用的了度搜,看下tikv 的block cache capctity大小的配置:storage.block-cache.capacity ,可以把这个调小了,reload滚动重启tikv
2、 pd-ctl store limit all xxx 吧这个值设置高些,可以提升balance速度,会占资源
3、原来6个tikv 然后扩容2个在缩容原来的6个,3副本剩下一个副本没地放啊,至少3个kv。 另外原来的机器旧tikv数量多,新机器加上不一定能提升性能
2 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
18
3.我现在还没缩容,我现在是 原来6 ,扩容2个 ,就是不敢缩
1 个赞
johnwa-CD
(Hacker Yp Yw Bvas)
20
目前除了内存,别的还好,内存就缓慢增长,然后最终会oom,然后重启
CPU, IO都不高
1 个赞