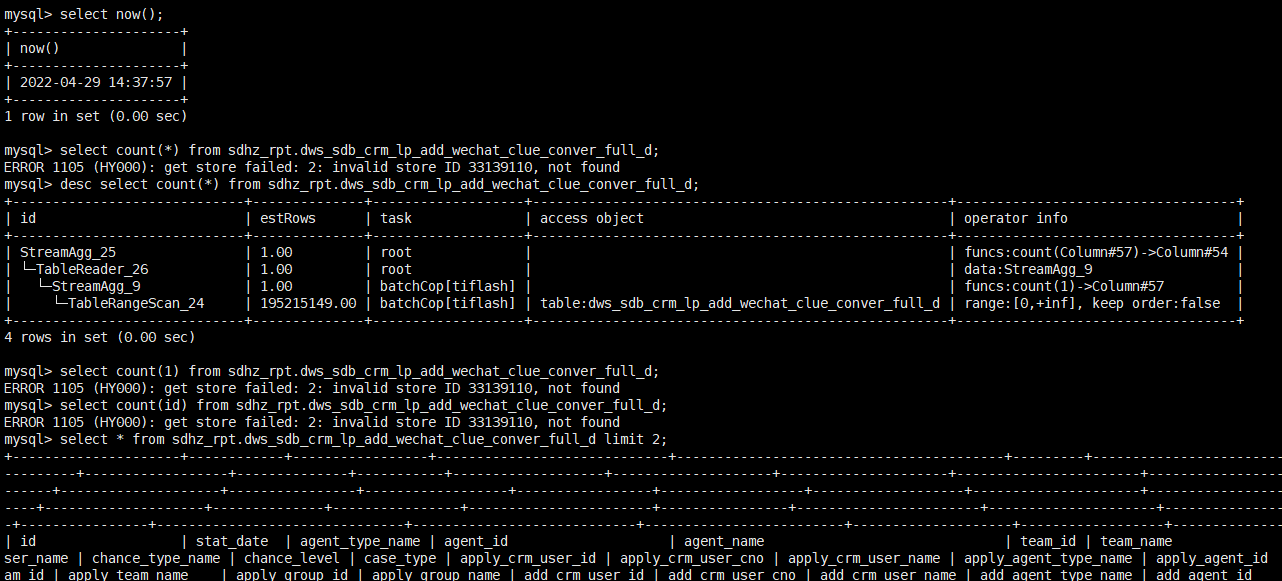
tidb 5.0.3
补充一下这表的操作是这样的:
后边又报出来了
1 个赞
正常,就是发现的这个查询有问题。其他可能也有,没人反馈 应该不多。
2 个赞
大概10天前有缩容tiflash 节点的操作,是正常的下线流程,但是grafana上监控数据显示异常,pd-ctl 查看里面stores 已经没有tombstone状态的。 下线完后,我执行了tiup cluster prune。 后来大佬又让我
10天前的操作,如果有问题应该早就爆出来了。那些表都是每天固定使用的一些表。
2 个赞
张雨齐0720
2022 年4 月 29 日 03:20
8
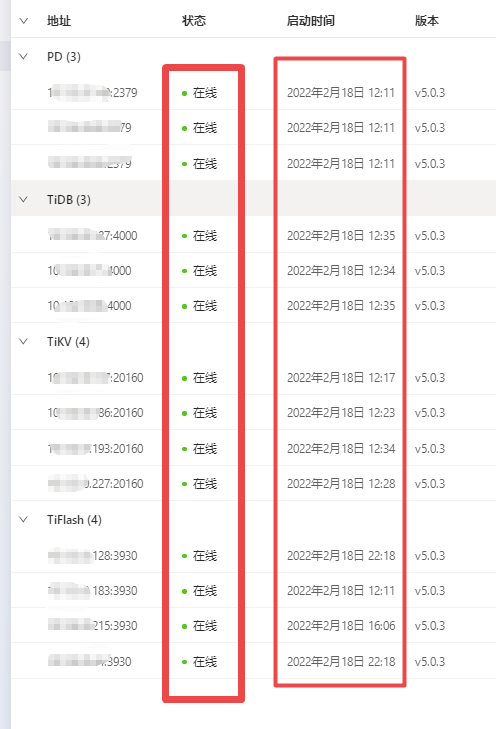
监控中看到所有TiKV/TiFlash都是正常在线吗?
1 个赞
h5n1
2022 年4 月 29 日 03:54
10
从inforation_schema.tikv_store_status看下store_id,address 还包不包含报错的那个
1 个赞
没有了,之前是6个tiflash ,3月份下了一个,上上周下了一台,还剩4个。
1 个赞
张雨齐0720
2022 年4 月 29 日 07:21
13
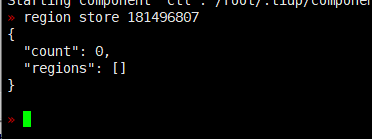
报错了store ID 181496807,查查这个id是哪个存储节点的,看看状态吧
1 个赞
h5n1
2022 年4 月 29 日 07:24
14
pd-ctl region store 181496807 这个看下
1 个赞
h5n1
2022 年4 月 29 日 08:07
16
information_schema.cluster_info 和pd-ctl store 看看是否有报错的那个store id
1 个赞
h5n1:
181496807
没有这个store,
» store
},
{
"store": {
"id": 11585778,
"address": "xx.xx.xx193:20160",
},
{
"store": {
"id": 290158285,
},
{
"store": {
"id": 290158286,
},
{
"store": {
"id": 4,
}
},
{
"store": {
"id": 5,
"address": "xx.xx.xx186:20160",
}
},
{
"store": {
"id": 2811498,
},
{
"store": {
"id": 60800510,
"address": "xx.xx.xx183:3930",
]
1 个赞
h5n1
2022 年4 月 29 日 09:36
18
你多查几次看看报错的store id是不是保持那2个,还是说会随机变化的
1 个赞
wisdom
2022 年4 月 29 日 12:32
20
检查看一下 日志 或者几点日志 看看抖动出现的原因能不能找出来
1 个赞