【 TiDB 使用环境`】生产\测试环境
【 TiDB 版本】 5.0.4/ 5.2.2
【遇到的问题】
Prometheus 所在的节点经常会每个一段时间(6h)出线高负载的磁盘IO,其中写磁盘延迟非常高,后经过排查可能是 Prometheus TSDB 的问题, 因为 Prometheus 每隔一段时间会将内存数据进行落盘,同时进行数据压缩,考虑是这一系列操作,导致短暂的磁盘写入压力过大。
参考: https://prometheus.io/docs/prometheus/latest/storage/
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
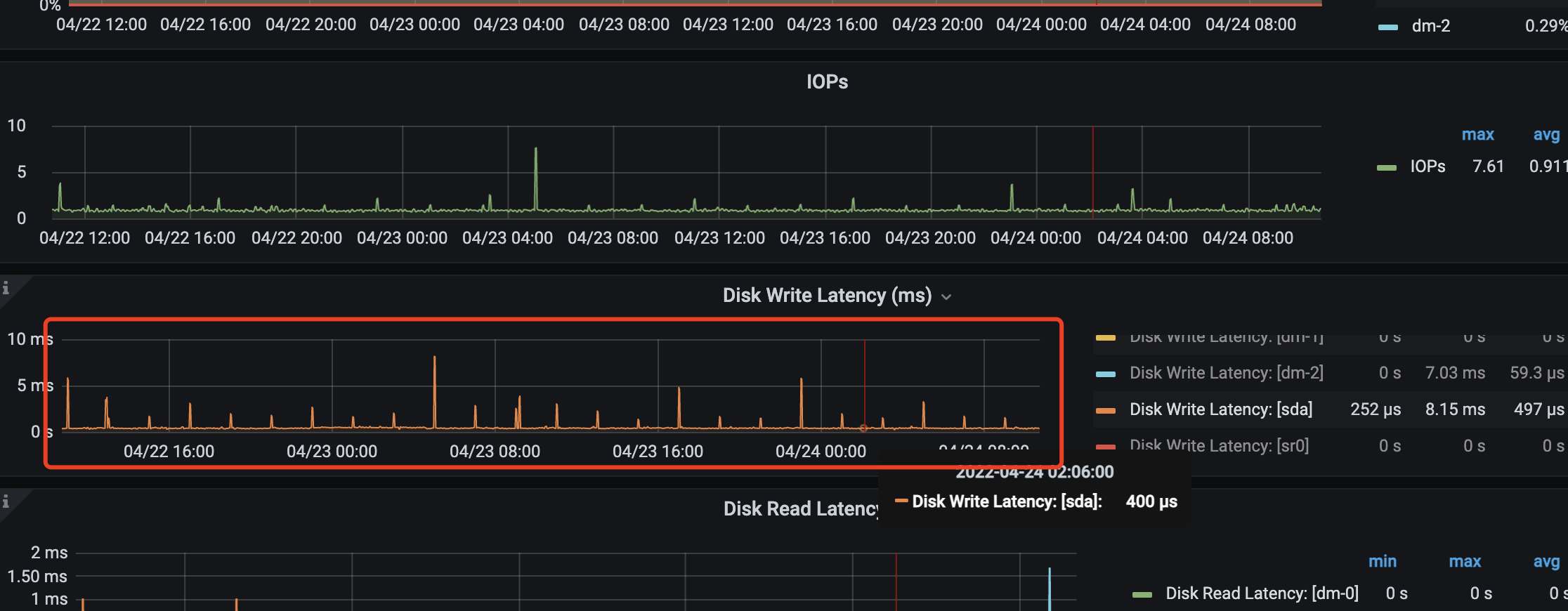
上图为测试环境,机器和数据都很少,但写入延迟已经达到 5ms 左右的延时了,生产环境数据量更大,延时高达 20 - 30 ms。
现在集群会的 Prometheus 节点会不断告警 磁盘写入延迟持续超过 16ms.
通过不断的查询相关资料, Prometheus 有两个启动参数好像可以解决该问题:
–storage.tsdb.min-block-duration
–storage.tsdb.max-block-duration
有没有大佬来看一下,这两个参数是否能解决该问题?
目前我还找不到TiDB部署的Promehteus中如何查看这两个参数的值,也不知道该如何修改值,会不会对机器造成其他影响。
官方似乎不太推荐修改:https://prometheus.io/docs/prometheus/latest/storage/#longer-block-durations
如果这两个参数无法修改,有没有其他的更好的解决方法?