yarthur
2020 年12 月 21 日 13:03
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
【TiDB 版本】:v4.0.8
【问题描述】:
查看tikv日志只发现gc_worker: auto gc will go to rewind日志 (监控时间比日志时间早8H)tikv.log (12.9 KB)
tidb日志显示有写冲突,但时间点不能完全对上tidb.log.bak (7.8 MB)
[2020/12/21 12:40:27.499 +00:00] [INFO] [<unknown>] ["New connected subchannel at 0x7fe1528eb420 for subchannel 0x7fded1d00240"]
[2020/12/21 12:40:27.501 +00:00] [INFO] [util.rs:419] ["connecting to PD endpoint"] [endpoints=http://10.66.105.154:2379]
[2020/12/21 12:40:27.502 +00:00] [INFO] [util.rs:484] ["connected to PD leader"] [endpoints=http://10.66.105.154:2379]
[2020/12/21 12:40:27.502 +00:00] [INFO] [util.rs:190] ["heartbeat sender and receiver are stale, refreshing ..."]
从日志中看到有这样的信息,能否重新一下这个 tikv 节点看下能够恢复正常
yarthur
2020 年12 月 22 日 03:24
5
那个节点我重启了,在观察一段时间吧;能给我说下是啥原因吗?因为连接过期导致的?
看日志感觉像是 TiKV 卡住了,所以尝试重启下,看能不能恢复
yarthur
2020 年12 月 22 日 04:04
7
重启那个节点后还是复现了,我是在11:22左右重启的
tikv日志
tikv.log (6.3 MB)
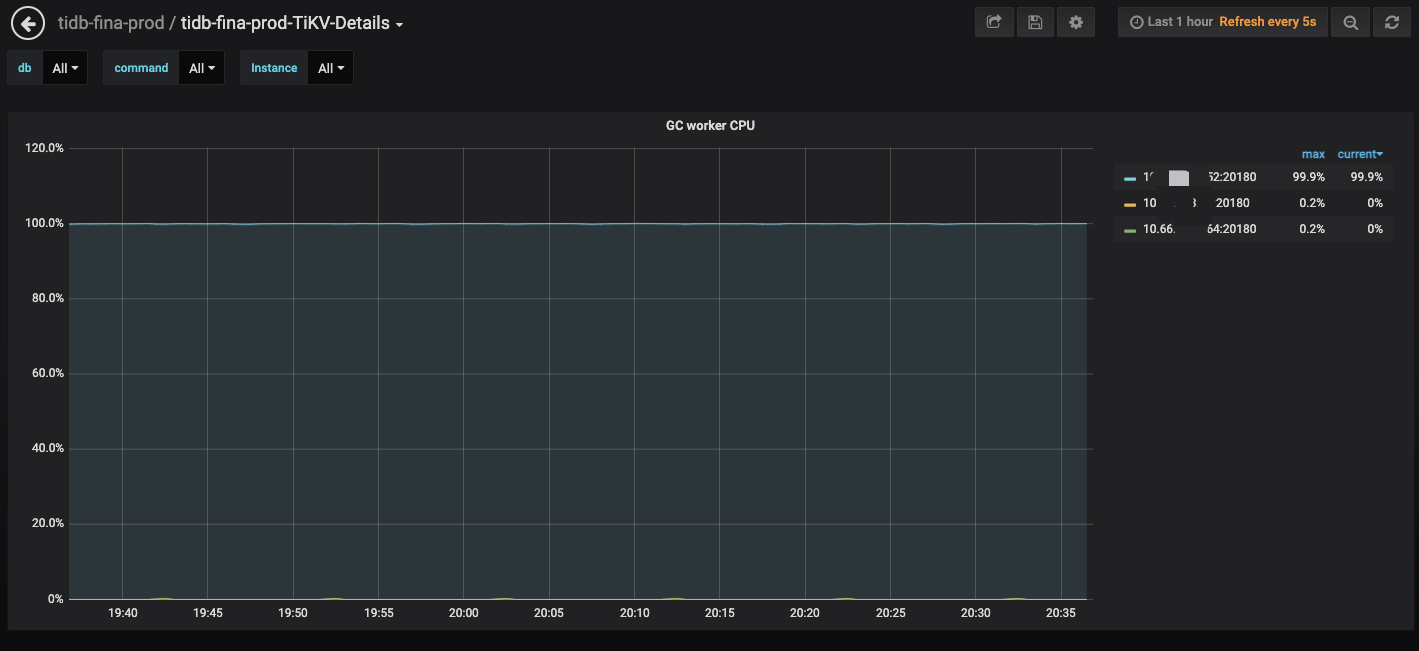
GC 一轮太慢了,如果 GC 在 interval 时间内完成就不会这样。可以上传一下 Overview 面板的完整监控看下么
看了下系统负载以及 region 和 leader 的数量并不是很多。
yarthur
2020 年12 月 22 日 07:29
12
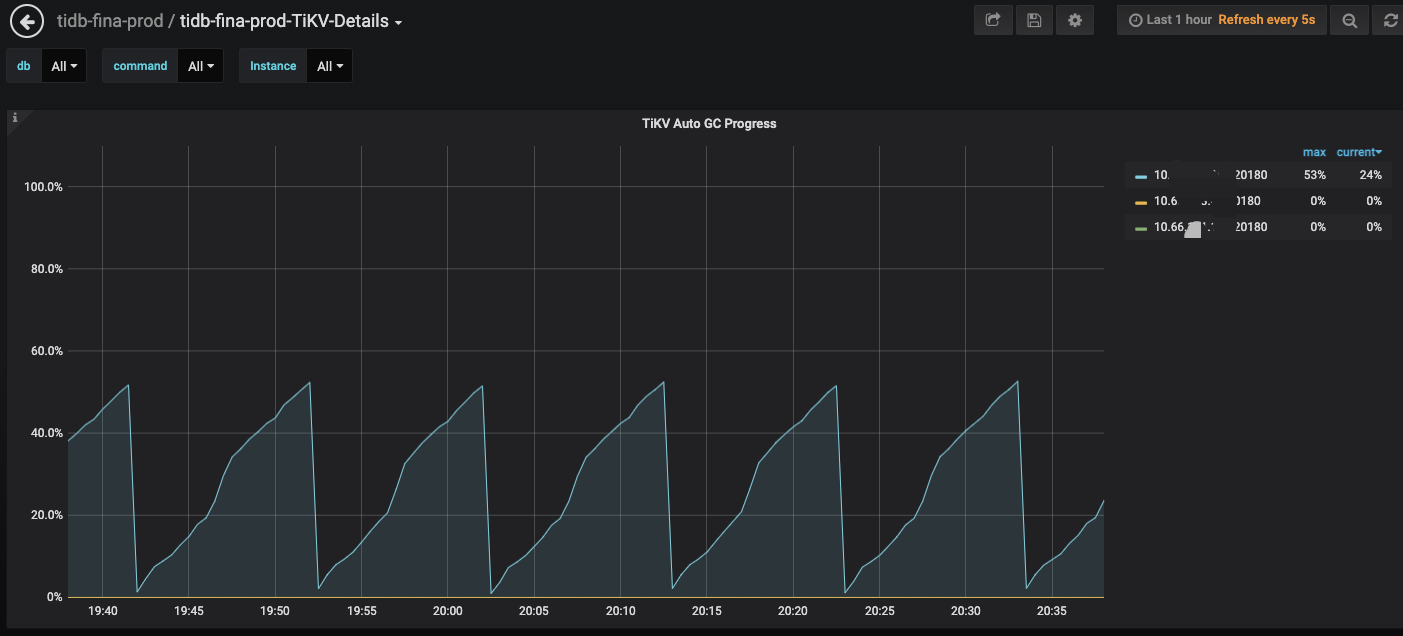
我interval调整为1h后gc完成了,我后面再观察下;
从日志看,每次 GC 的 safe point 点是不同的
yarthur
2020 年12 月 23 日 07:05
14
下一轮 GC 则可能停止在上一轮更新 safepoint 时的进度(即下一次 GC 进度达到 30% 时停止
没读懂后半句的意思
https://github.com/tikv/tikv/blob/3b2c5337c837b8bf9d37f954a4c17a407e253251/src/server/gc_worker/gc_manager.rs#L376
代码注释这块有相关的解释。
所以如果 GC 一直无法在一个 interval 中完成就一直会有这个 rewind 的问题。但是这个是没有影响的。
yarthur
2020 年12 月 23 日 09:07
16
明白了,多谢啦,需要保证gc interval间隔内gc能完成是吧
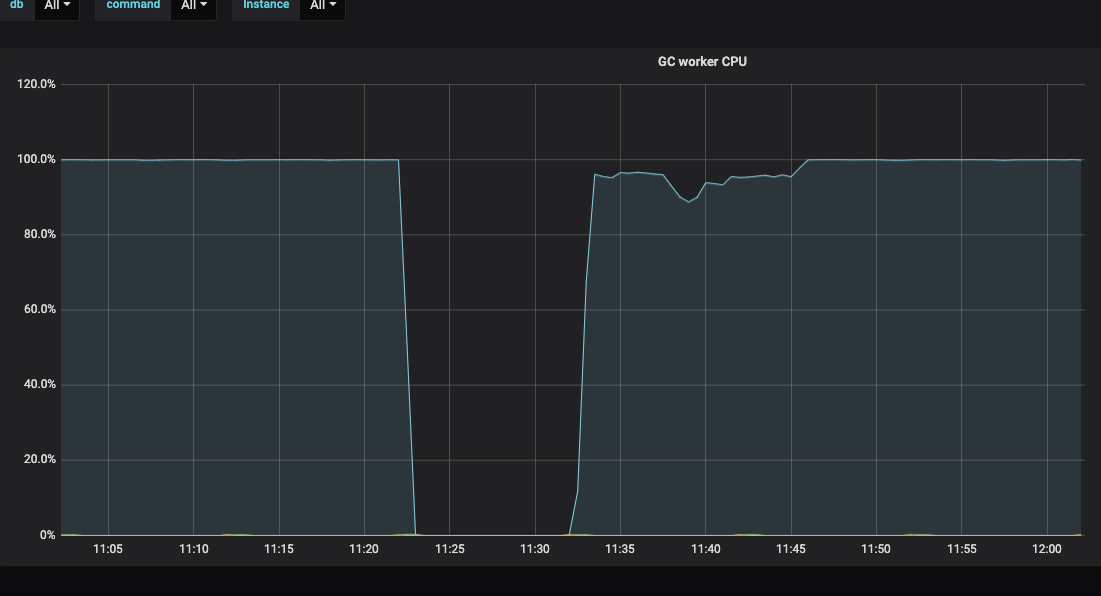
但这个gc_a_round一直运行doesn’t matter不太懂,至少会一直占用一个核吧
就是这个不会影响 GC 的完整性,从监控上看到的 GC 一直没有 100% 完成,但是实际的话,还是对所有 region 进行了 GC 操作的,不是没有完成 GC 。
system
2022 年10 月 31 日 19:03
18
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。