【 TiDB 使用环境】生产
【 TiDB 版本】5.3.0
【遇到的问题】用tidb-lightning的tidb-backend数据正常导入完成后,表数据不全(缺数据)
【复现路径】正常drop database 然后重新用lighting导入dumping生成的sql文件
【问题现象及影响】
【附件】
-
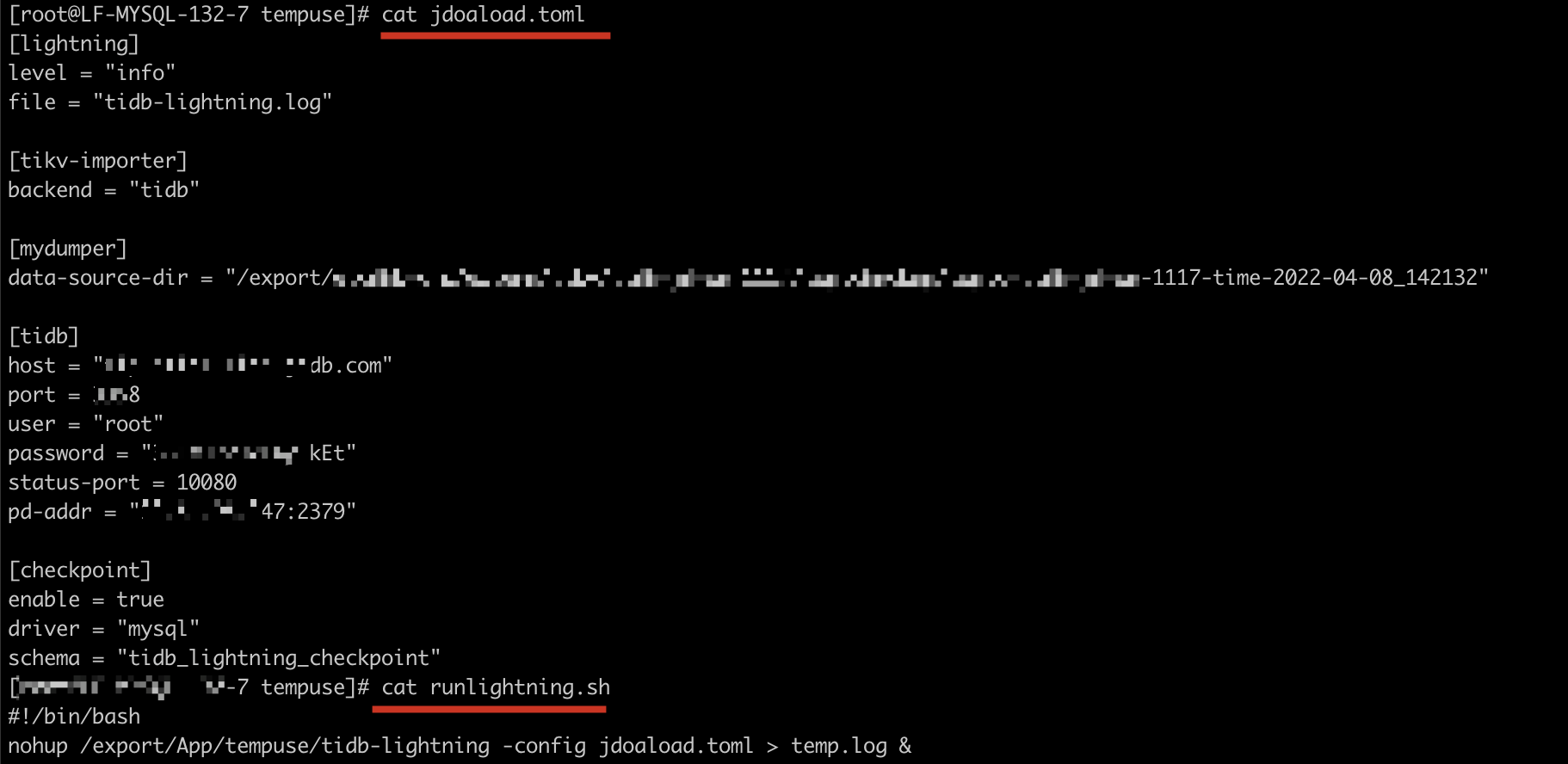
配置文件及启动脚本
-
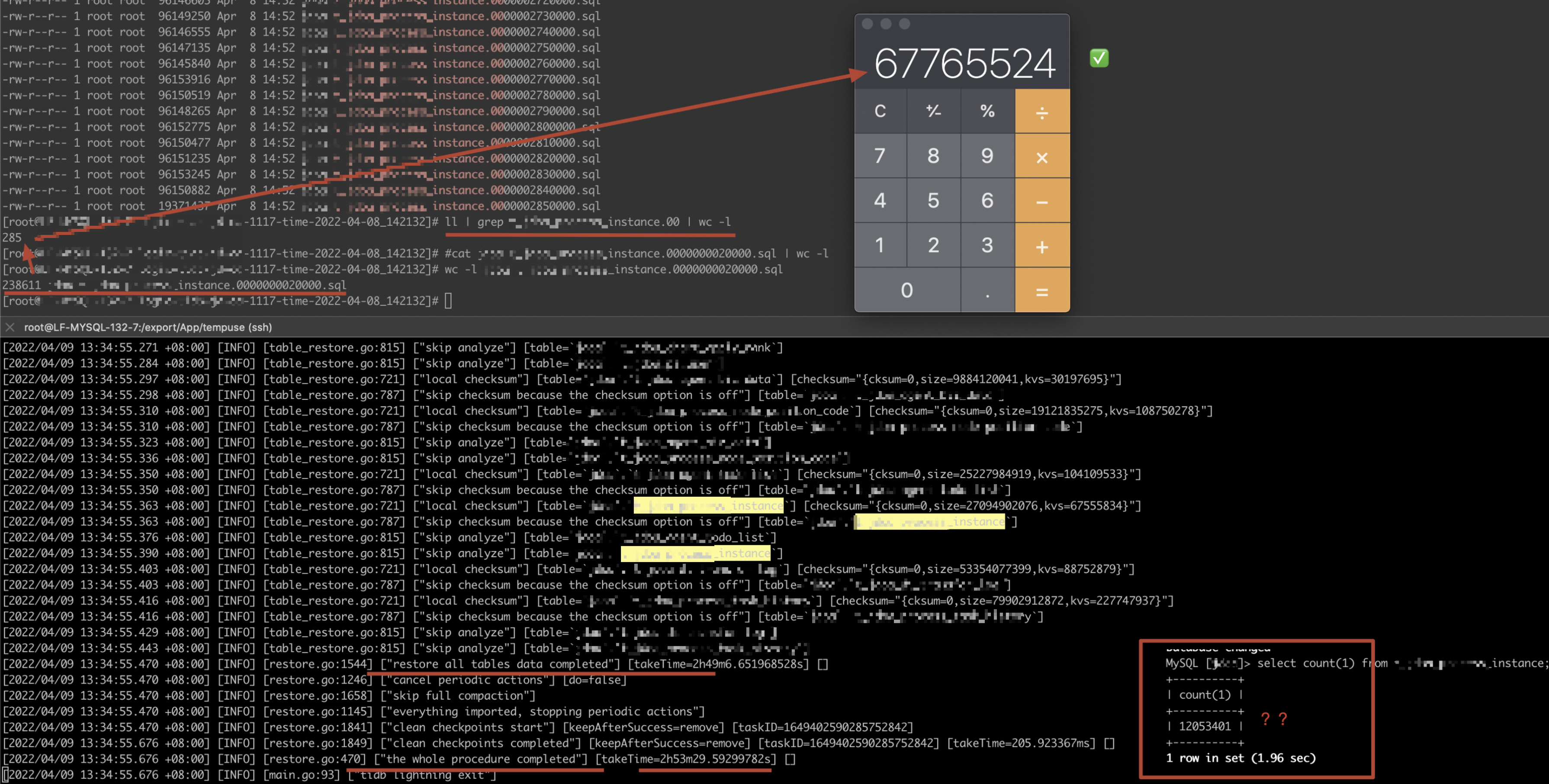
sql文件数据量 和 lightning最后的日志 和 目标表数据量(数据量缺少)
【 TiDB 使用环境】生产
【 TiDB 版本】5.3.0
【遇到的问题】用tidb-lightning的tidb-backend数据正常导入完成后,表数据不全(缺数据)
【复现路径】正常drop database 然后重新用lighting导入dumping生成的sql文件
【问题现象及影响】
【附件】
配置文件及启动脚本
sql文件数据量 和 lightning最后的日志 和 目标表数据量(数据量缺少)
1、dumpling导出的sql文件并不是一行代表一条数据,这种计算方式本身有问题
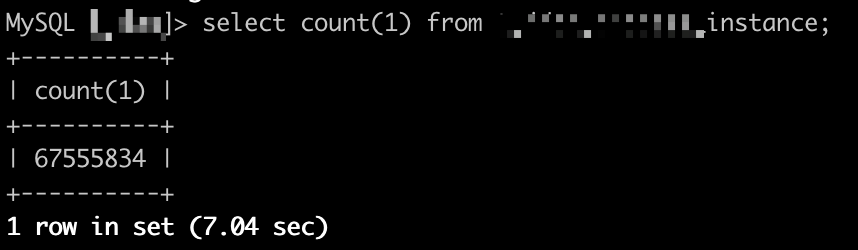
2、你那个6千多万是文件数*其中某个文件行数的结果么,这估出来的应该是所有导出的数据量吧,而且误差还比较大,你做count只是算了一张表的行数
3、建议用lightning的checksum来检验数据
![]() 这个计算方式太不严谨了,没什么参考价值,每个文件的数据量差异会很大,参考下lightning的checksum吧,如果只是测试下数据量也可以导出导入前后分别count做下比较。
这个计算方式太不严谨了,没什么参考价值,每个文件的数据量差异会很大,参考下lightning的checksum吧,如果只是测试下数据量也可以导出导入前后分别count做下比较。
https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-faq#如何校验导入的数据的正确性
高大上,周末也不休息。
关于数据量我用这个粗略算法这么算 其实是有个前提,就是我实际原库表中的数据 已经查过是6千万行数据,然后我再次来校验sql文件中的数据是否全,才有的上面的计算方式截图;实际库中数据也是6千多万,如下:
卷起来~![]()
各位~找到原因了,是由于我配置文件中pd-addr地址配错ip了,配成了源库的pd地址,改成目标库这一套就好了;感谢各位~
周末加班卷起来![]()
dumpling导出也没有报错吗
哈哈 卷~
dumpling这个步骤没问题,数据都是ok的;找到原因了,是我的配置文件写错了 pd-addr
感谢~
![]() 找到问题就好
找到问题就好
嗯嗯,感谢关注~![]()
以前遇到过一次数据不一致是因为lightining的版本和tidb不一致![]()
哈哈感谢你的经验提醒~目前我们就一个版本5.3,没有太多版本,不过最近tidb都发布6.0了,后续使用的话,这块儿还真得多注意,确认好集群的版本及对应版本的工具![]()
要保证lightining的版本和tidb一致
嗯嗯,目前是一致的,是由于我pd-addr配错集群导致,感谢提醒![]()
奇怪,配错pd-dir,为什么还会在正确目标库查到数据?
看日志好像没有开 checksum 诶,这是生产环境的吗?如果数据量下次匹配上了,是不是就发现不了错误了![]()
这个我也不太明白,唯一知道的配错的pd地址的集群是数据源,里面有需要同步的全量的相关库表,目标数据库中有相同的库
嗯,如果发现数据量匹配上了,还真就很可能忽略这个错误了