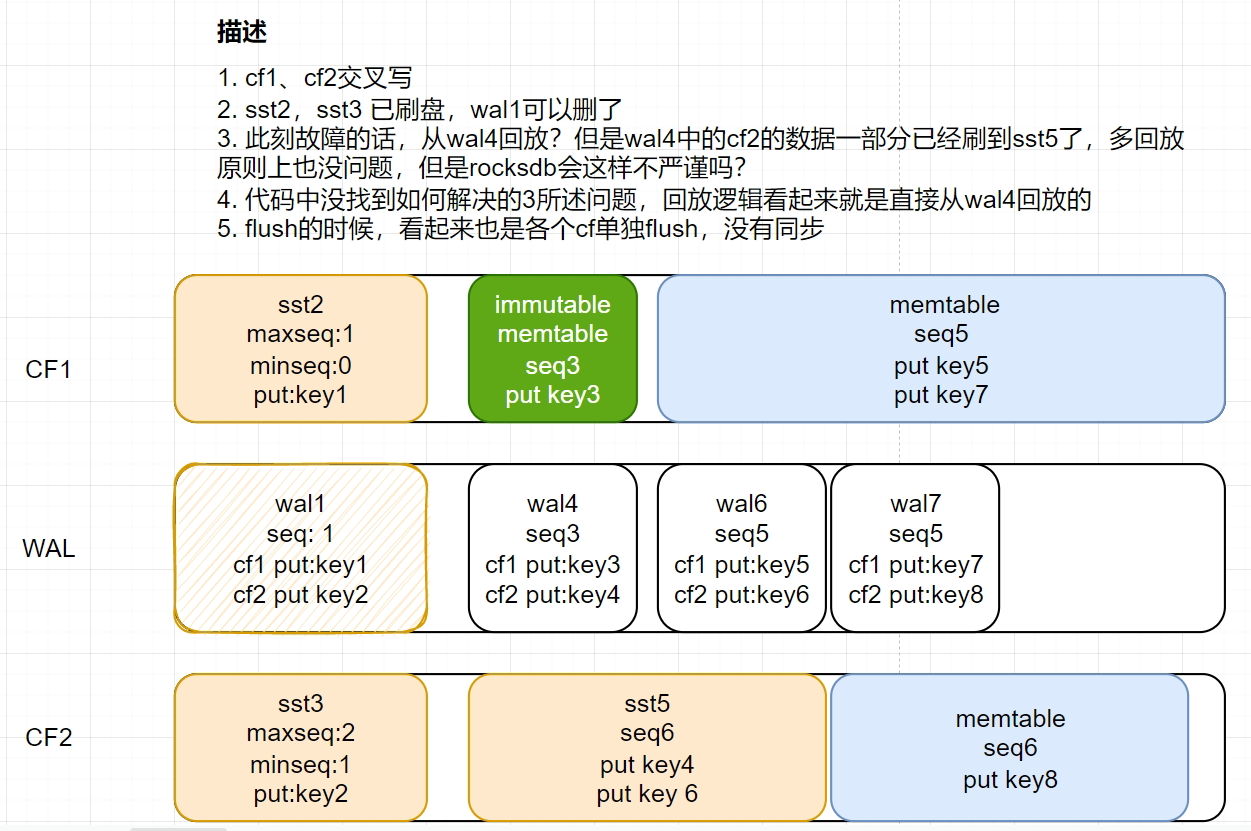
我最近在看rocksdb代码,图示画的时rocksdb sequence和wal 相关的。其中wal的每次切割对应的时cf的SwitchMemTable, 假设一个wal里面只有一个writebatch
问题是:如果现在这个状态,rocksdb进程异常退出了,当rocksdb启动时,从WAL4恢复吗?看recover逻辑好像是这样,但是这样的画,cf2的一部分数据已经落到sst5了。不就会多重放一部分吗?
我画的图也可能不对,麻烦大神们指出,帮忙把这个逻辑捋顺。谢谢
我最近在看rocksdb代码,图示画的时rocksdb sequence和wal 相关的。其中wal的每次切割对应的时cf的SwitchMemTable, 假设一个wal里面只有一个writebatch
问题是:如果现在这个状态,rocksdb进程异常退出了,当rocksdb启动时,从WAL4恢复吗?看recover逻辑好像是这样,但是这样的画,cf2的一部分数据已经落到sst5了。不就会多重放一部分吗?
我画的图也可能不对,麻烦大神们指出,帮忙把这个逻辑捋顺。谢谢
应该是缺少一个 mainfest 的 RocksDB 的事务日志逻辑,这里面记录了当前 sst 的状态和位点信息,恢复时候会通过这个日志进行确认需要 recover 的位置和数据。应该不需要重放已经落盘 sst 的部分,而是从那个位点开始重放,一直到完整的事务结束。Track WAL in MANIFEST · facebook/rocksdb Wiki · GitHub
感谢大神回复,我再看看manifest怎么记录的恢复的位点信息。
相关处理逻辑在 MemTableInserter::SeekToColumnFamily 中 (代码),回放时将正在回放的日志编号与 CF 数据中最新的 log number (在这里更新并持久化)进行对比。
感谢大神回复!真是找了很久没找到怎么解决的这里,想了好几个解决的方法,去看代码都不是我想的那样,忽略了InsertInto的参数传递不同。这样就顺畅了。
我总结下:
以此实现过滤掉CF2中已经恢复的数据。
再次感谢大神回复!!这个insertinto函数在正常插入和恢复时的recovering_log_number的值不同,忽略了这一点。没看那么细。
另外,有没有rocksdb的交流群帮忙拉我进去,再有类似找半天的问题方便直接请教。谢谢。
这段话没看懂。为什么是遍历cf找最小log number呢?不是应该是持久化的最大事务号吗?我觉得版主提到的mainfest中记录当前sst的状态与日志点位看来更合理。
从current找manifest,从manifest找到cf,然后从所有cf中找最小的lognumber。
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。