课程名称:课程版本(201)+ TiDB 的适用场景
学习时长:1小时
课程收获:TiDB 的适用场景和不适用场景
课程内容:
典型的OLTP场景
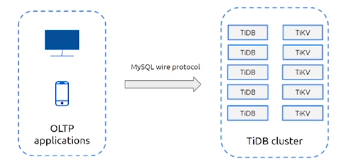
当您需要对海量数据(数十亿行)进行随机、实时读/写访问时
- ACID支持
- 二级索引支持
- MySQL 协议
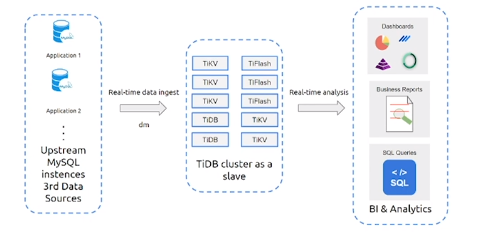
实时 HTAP 场景
- 实时HTAP(混合事务/分析处理)
- 当您有一个使用TiDB的类似OLTP的场景,并且希望在TiFlash的帮助下原地进行OLAP分析时
- 新鲜的数据
- 对OLTP性能无干扰
- 数据集成
*当您有多个数据源(如OLTP数据库、流式接收等)时,您希望对汇总的数据进行OLAP分析
通过TiSpark与Spark Eco系统连接
在这里,您可以使用Spark在TiDB平台内就地处理数据,而无需将数据移出。
以下场景很适用:
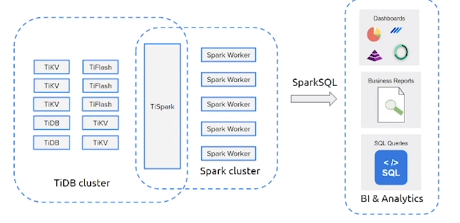
- 迭代处理
*像传统的ETL工作 - 连接数据集
*连接来自多个数据源的大型数据集- 需要进行大量的清洗和排序数据
以下场景TIDB并不是一个好选择
- 你的数据可以放在一台服务器上
- 你的业务需要重度的分析场景
- 对大型数据集进行扫描和聚合,使得中间结果无法放入单个服务器的内存中
- 你需要亚毫秒的延迟
- 超低延迟的要求那你可以考虑redis了