课程名称:TiDB 平台架构和全景图
学习时长:20
课程收获:对 TiDB 的核心组件和生态工具的功能有一定的理解
课程内容:
- 整个TIDB是计算存储分离的架构,如图:
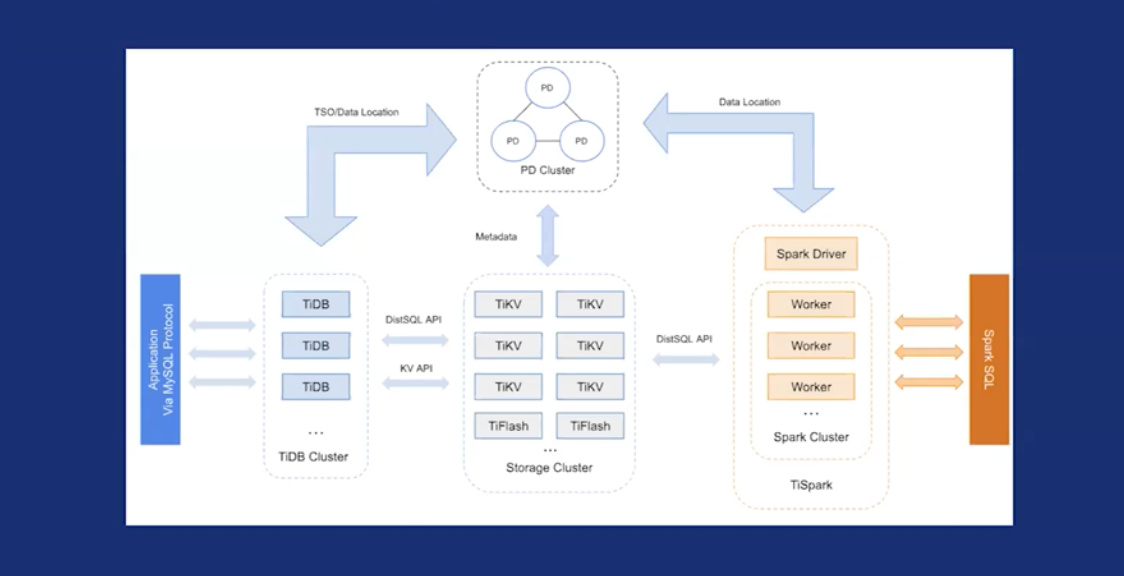
1)中间的TIKV和TiFlash是存储层,两边的TIDB和Spark是计算层,分别处理Mysql及Sparksql;
2)上面的PD与下面的组件均有交互,存储整个集群里面的数据。
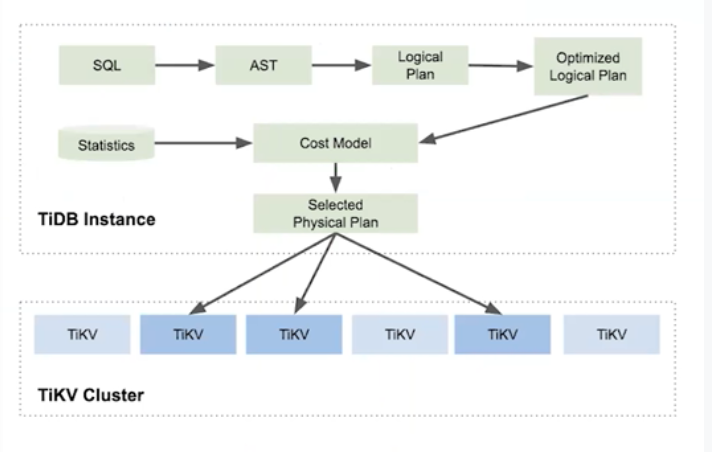
2. TIDB是无状态的SQL存储,客户端可以连上任意一个TIDB实例,TIDB兼容Mysql协议,功能完善,可在线DDL,如图:
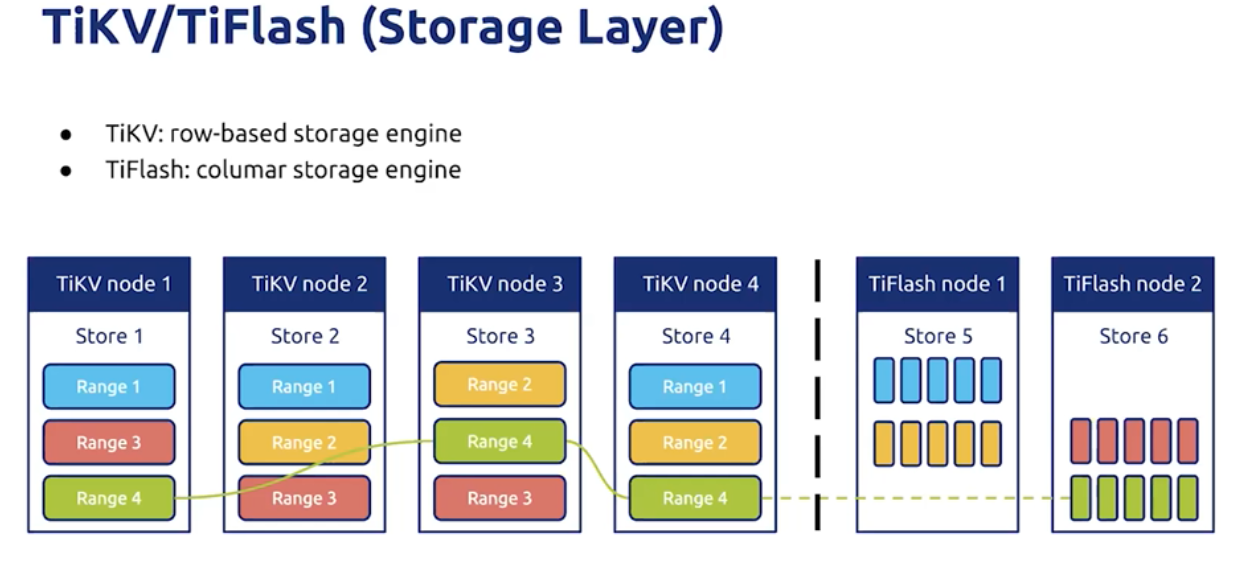
1)TIKV和TiFlash是存储层,TIKV 是行存储,适合事务处理,TiFlash是列式存储,适合分析处理。
2)数据根据范围切分,同个范围的数据有多个副本,副本之间通过Rust共事协议同步,保证强一致和高可用。
3)其中TiFlash上的副本固定为Rust Learner,使得对TIKV上的事务处理最小化
4)通过TIDB的优化性选择,可以做到让事务类的数据查询走TIKV,Search类的查询走TiFlash,从而最大程度的隔离OLAP和OLDP。
4. PD是TIDB集群的智能大脑
1)存储集群的元数据,比如Region处于哪些TIKV上
2)调度和负载均衡Region,比如把Region调度到另外几个TIKV上,或者把Raft leader迁移给另一个Flower;
3)负责分配全局单调递增的时间戳
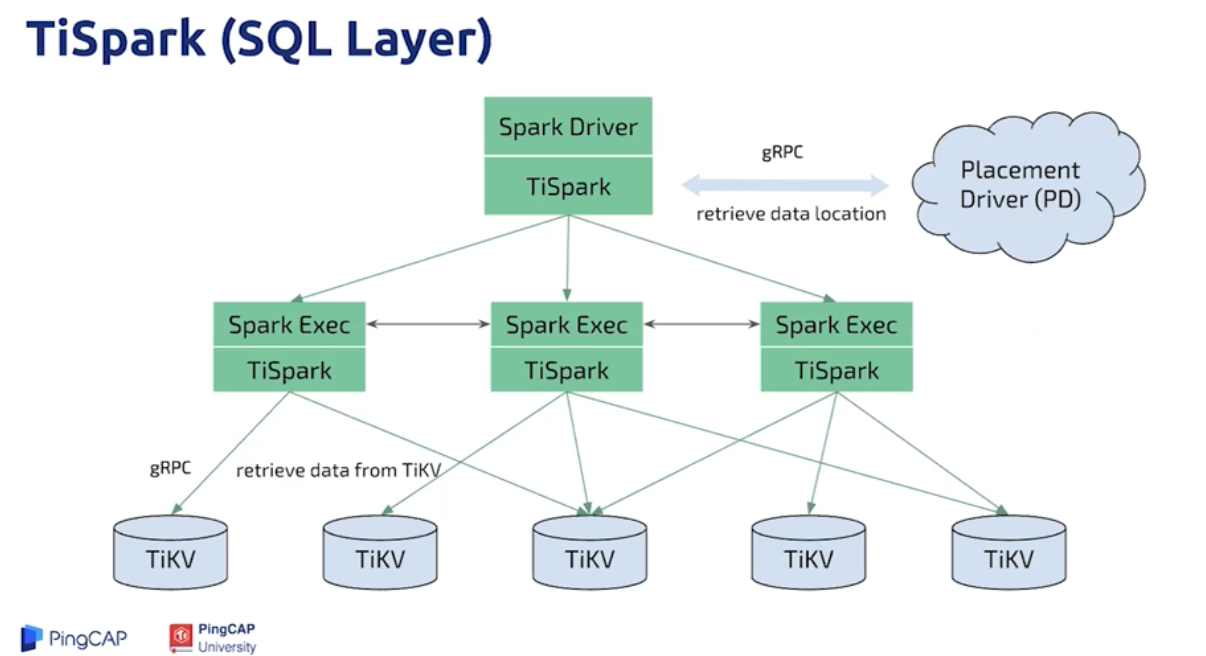
5. TiSpark是将Spark SQL 直接运行在 TIKV上 的OLAP解决方案。从数据集群的角度看,TiSprk+TIDB可以让用户无需进行脆弱和难以维护的etl,直接在同一平台进行事务和分析两种操作,简化了系统架构和运维。
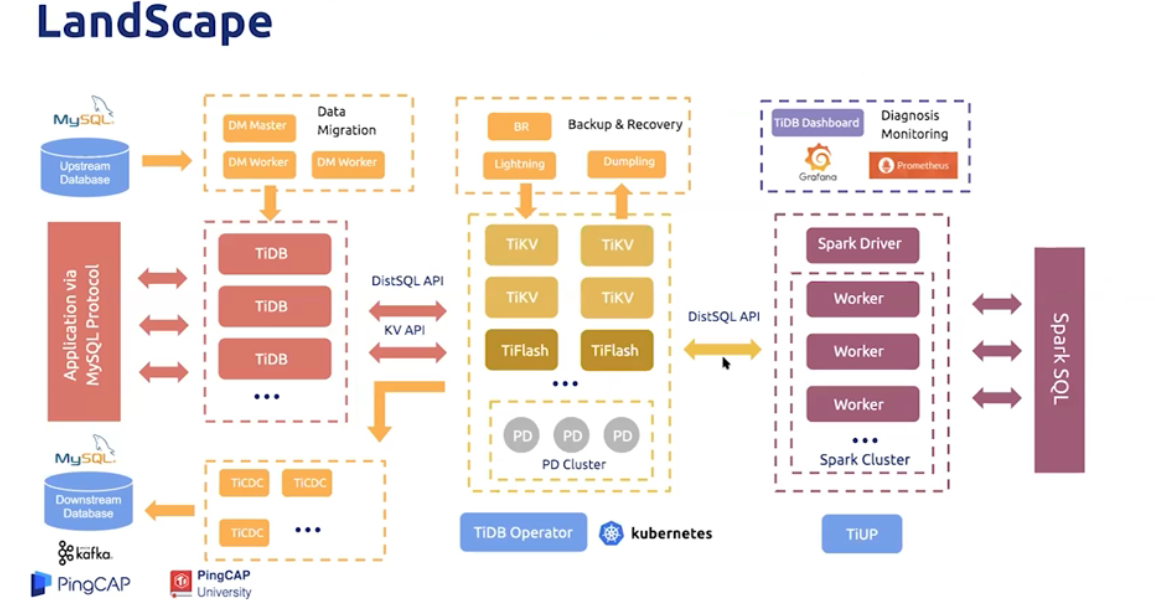
- TIDB的生态工具
1) TIUP是TIDB4.0新引入的组件工具,在TIDB的生态系统下提供单机部署、集群部署、组件下载、版本控制
、分发等功能;
2)Lighting:是用于TIDB的全量导入工具,支持读取从Mydumper或CSV数据源导出的SQL dump;
3)Dumpling是TIDB的全量导出工具,可选导出的格式有SQL和CSV。 - BR是一个对TIDB进行分布式备份和恢复的工具

备份的力度可以是全量或者是单库单表,它直接从TIDB存储层入手,把备份和恢复任务下发到各个TIKV执行,将备份和恢复带来的CPU和IO均匀分布在各个TIKV上;
8. TiCDC是一款通过拉取TIKV变更日志实现的TIDB资料数据同步工具,具有秒级上下的数据同步。
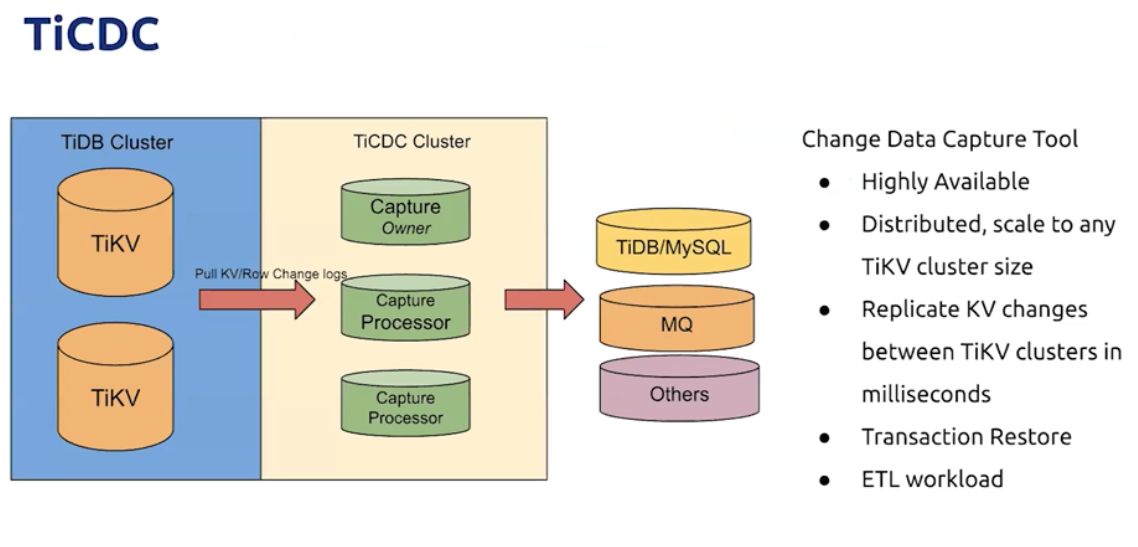
1) 是一款开放数据协议,能够与多种eql生态系统对接,满足用户在大数据查询中对各类数据的应用和分析需求。
2)广泛适用于日日收集,数据聚合,流式数据处理,在线分析等
9. TIDB整个生态的全景图