TIDB版本信息:
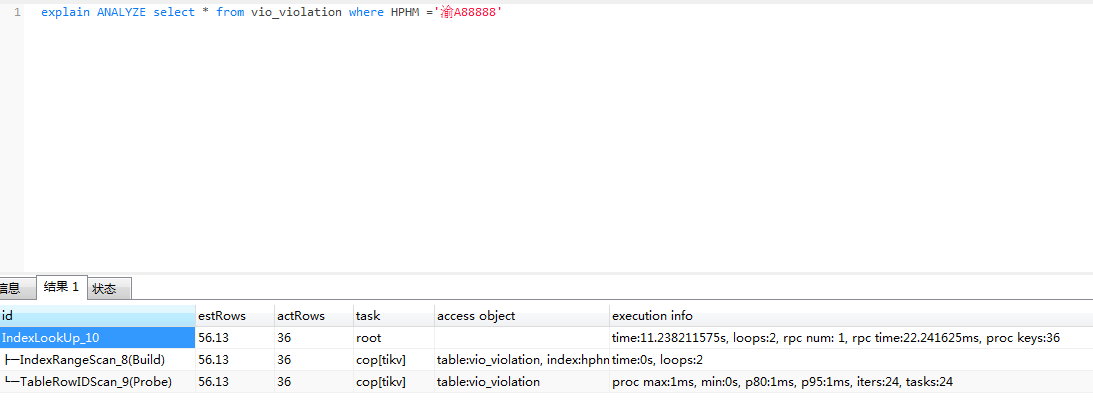
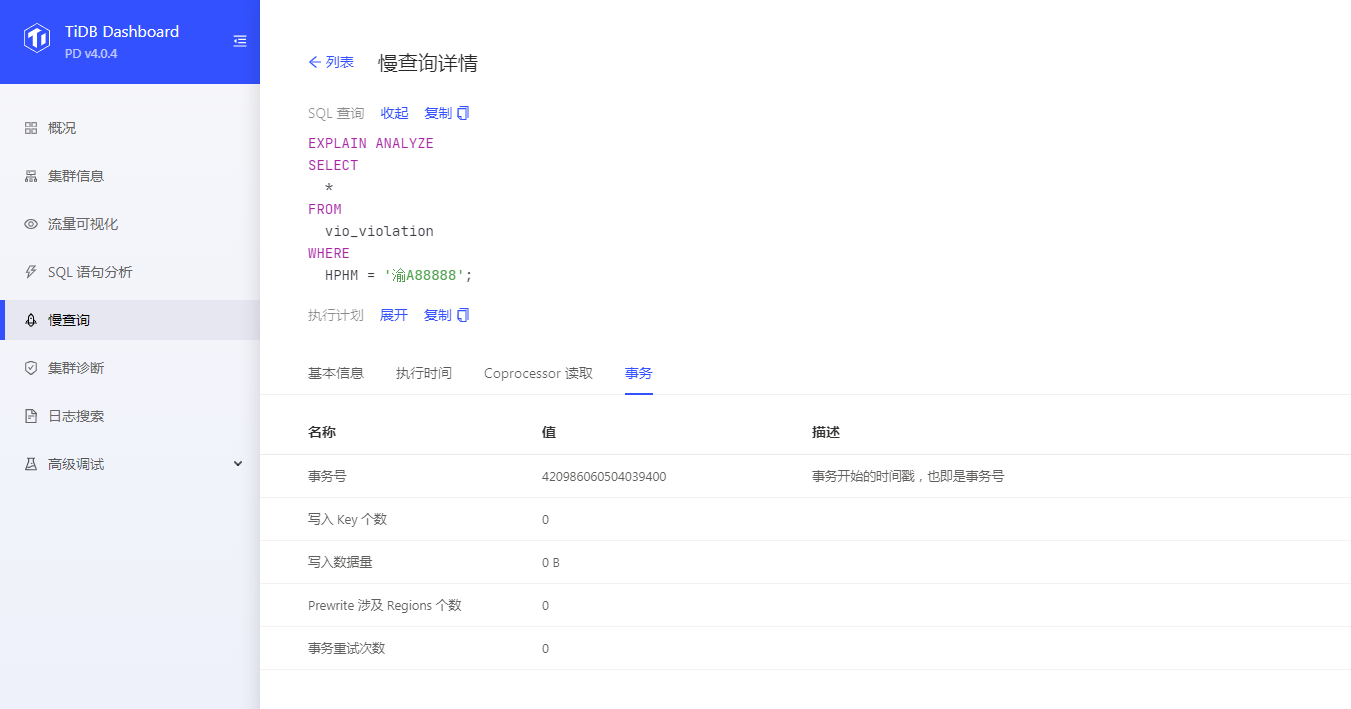
explain analyze信息:
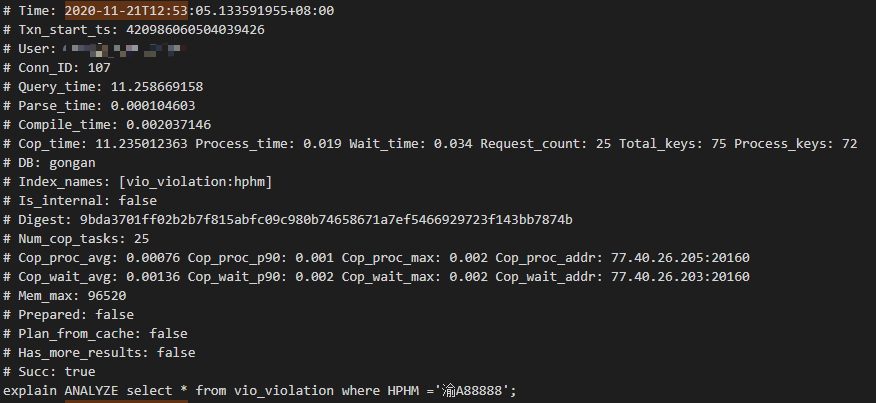
 slow query log 信息:
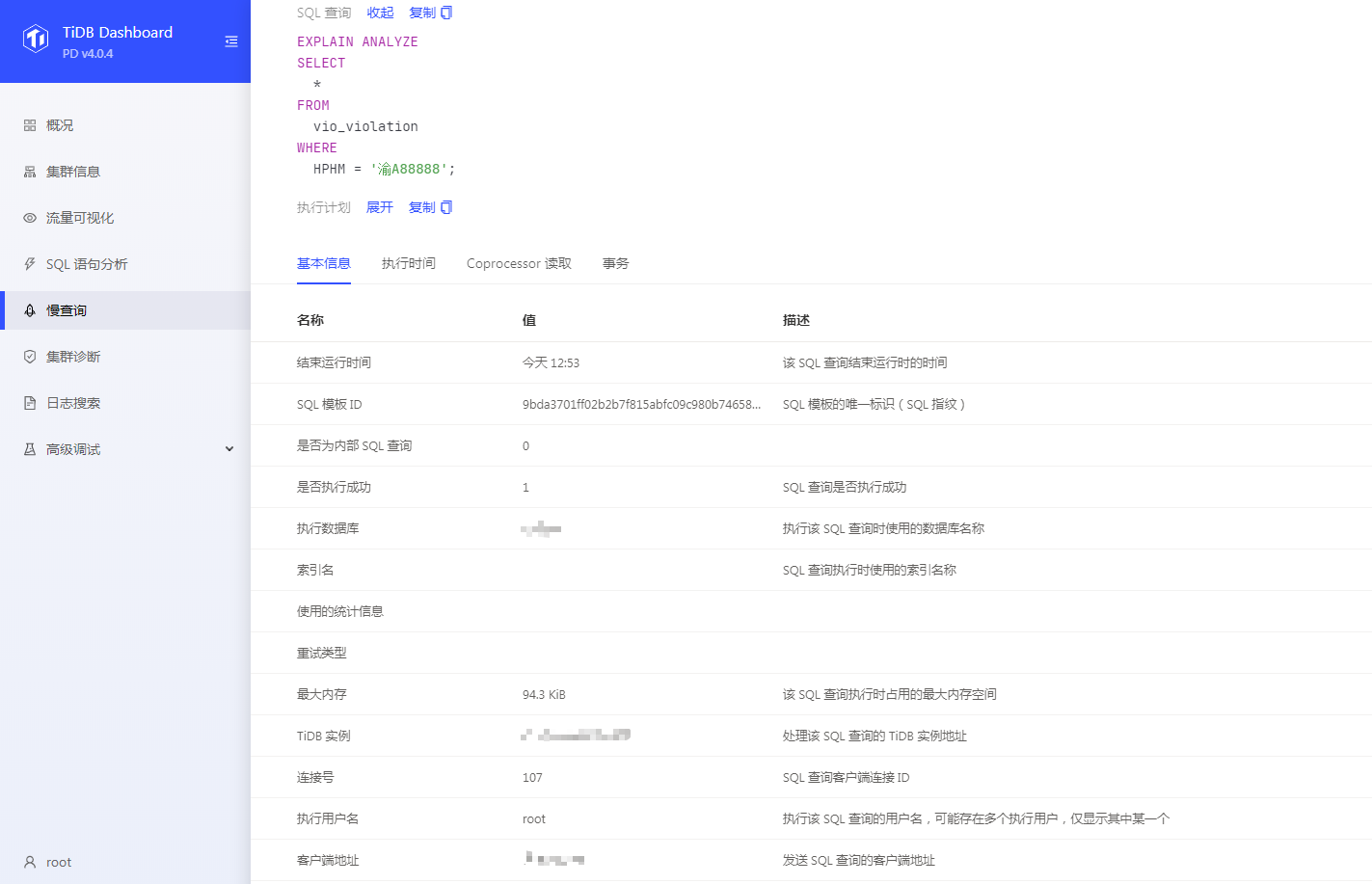
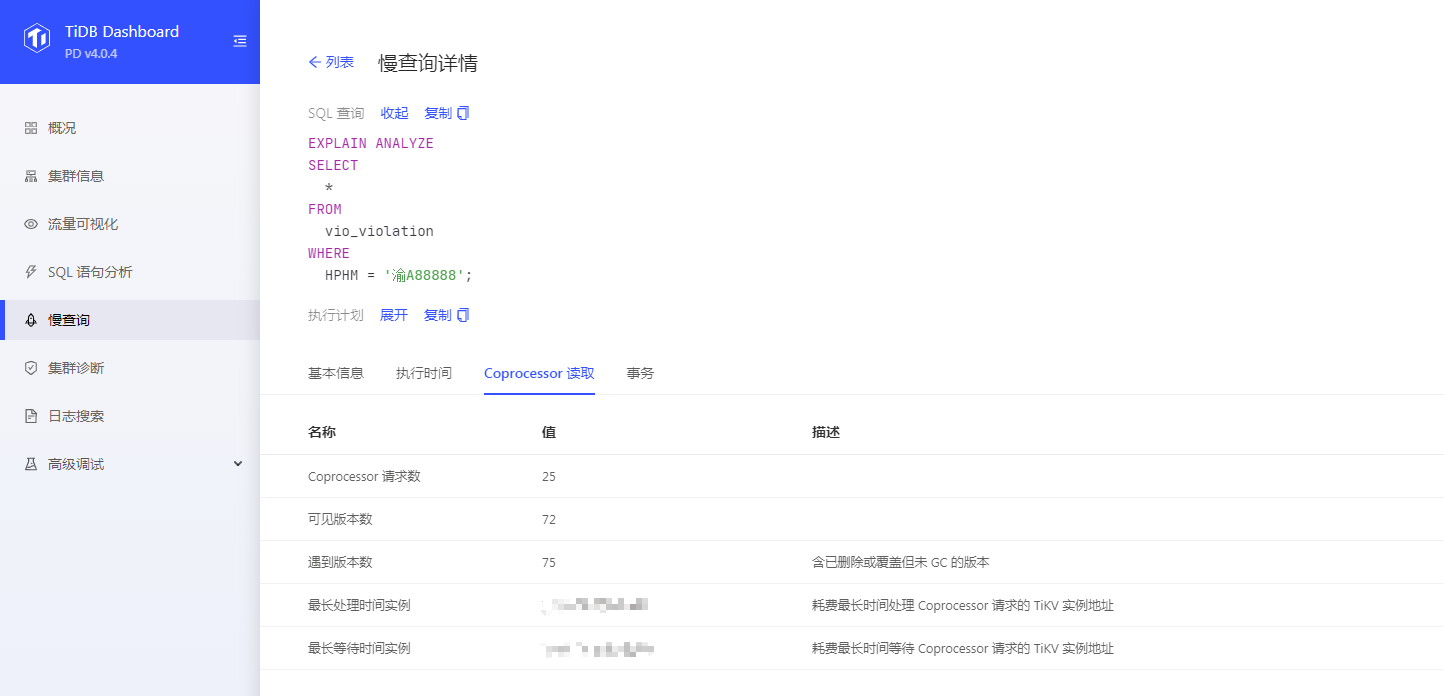
tiadb dashboard 信息:
slow query log 信息:
tiadb dashboard 信息:
现象描述: 正常情况下 查询时间 毫秒级。 但是最近平均每20次就会出现一次特别长时间的查询,整个TIDB所有的表都会出现这种请款。
集群配置 :
1 PD 2* 8核CPU 内存 16G SAS硬盘
1 TIDB 2* 8核CPU 内存 16G SAS硬盘
3 TIKV 2* 8核CPU 内存 32G 2TSSD
网络环境:千兆网络,内网。 会有不稳定,基本在 0.1 -30 ms 之间波动
监控信息如下:
表数据量 在 一亿左右 , hphm 字段有索引。 及时不适用 * 来查询,适用正常的 指定字段查询 还是会出现特别长的查询时间
spc_monkey
(carry@pingcap.com)
2
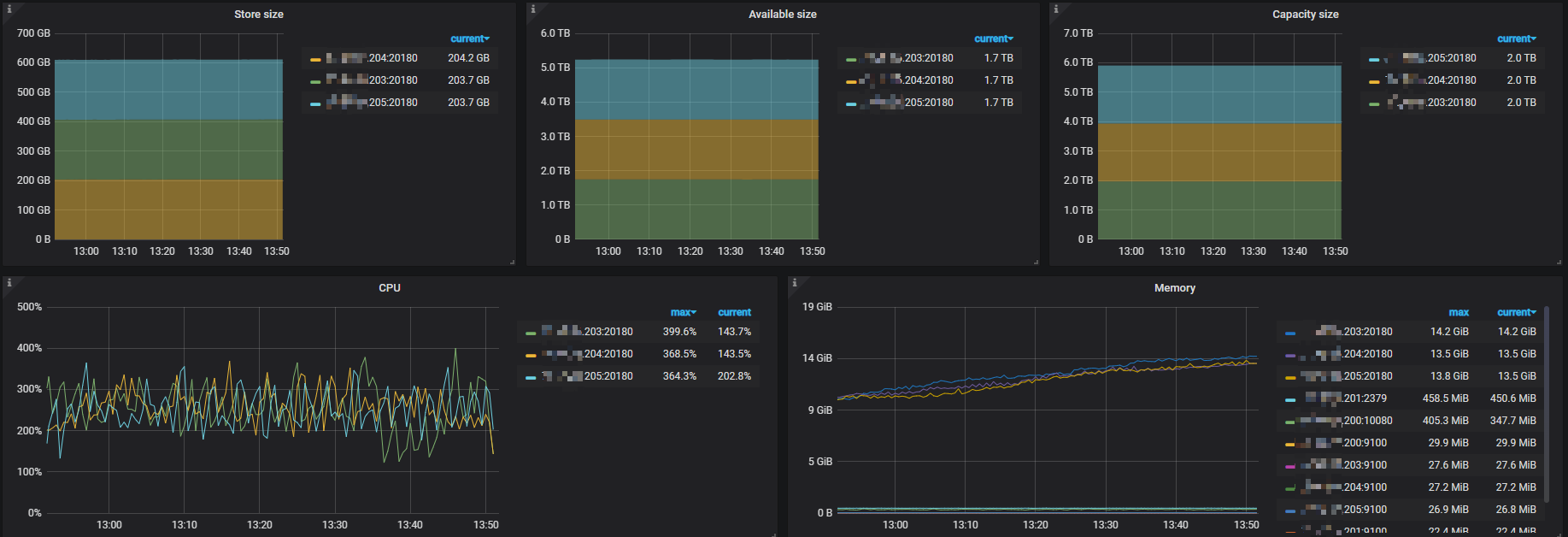
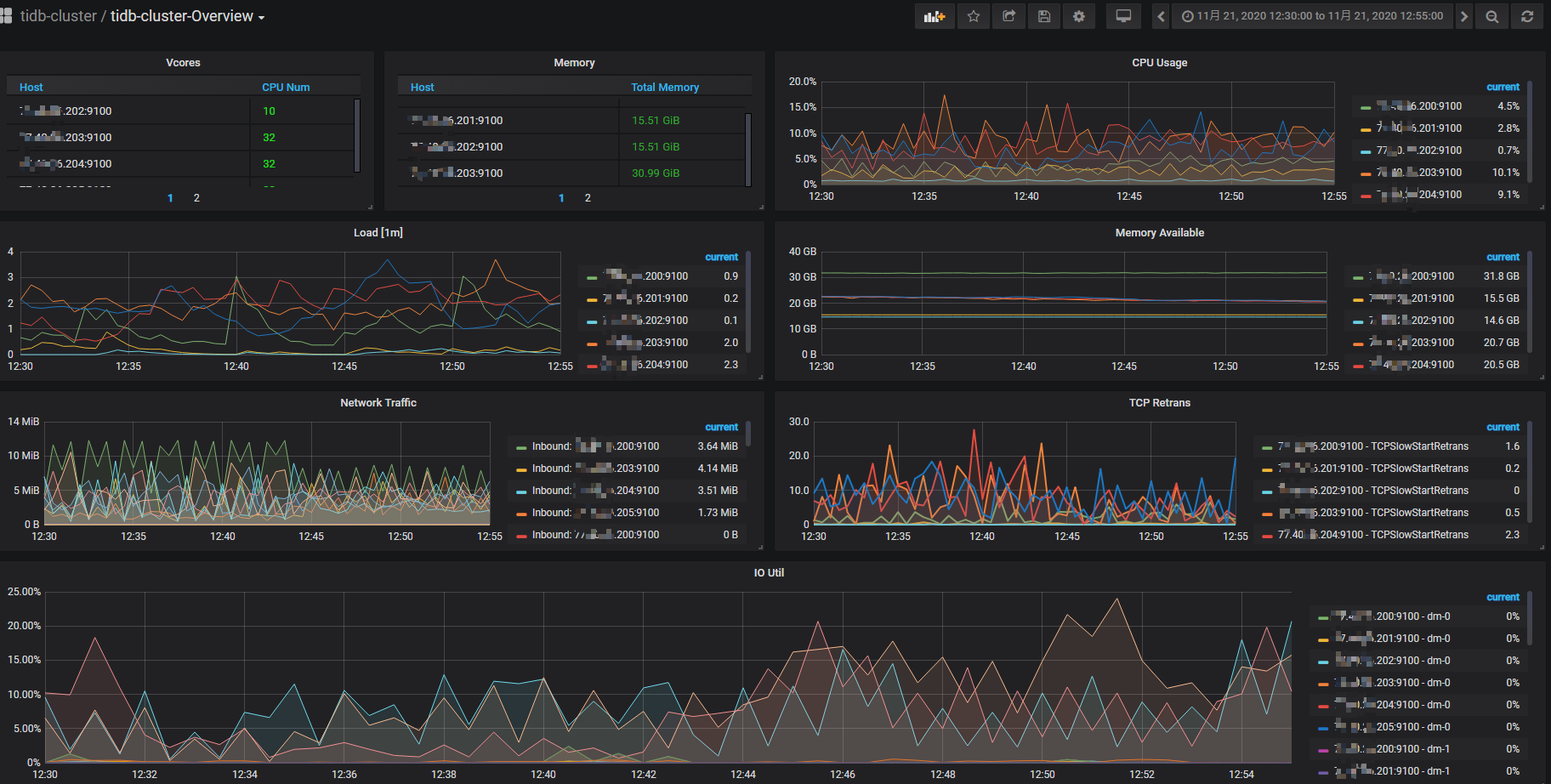
1、给一下 overview 下的 system info 监控指标
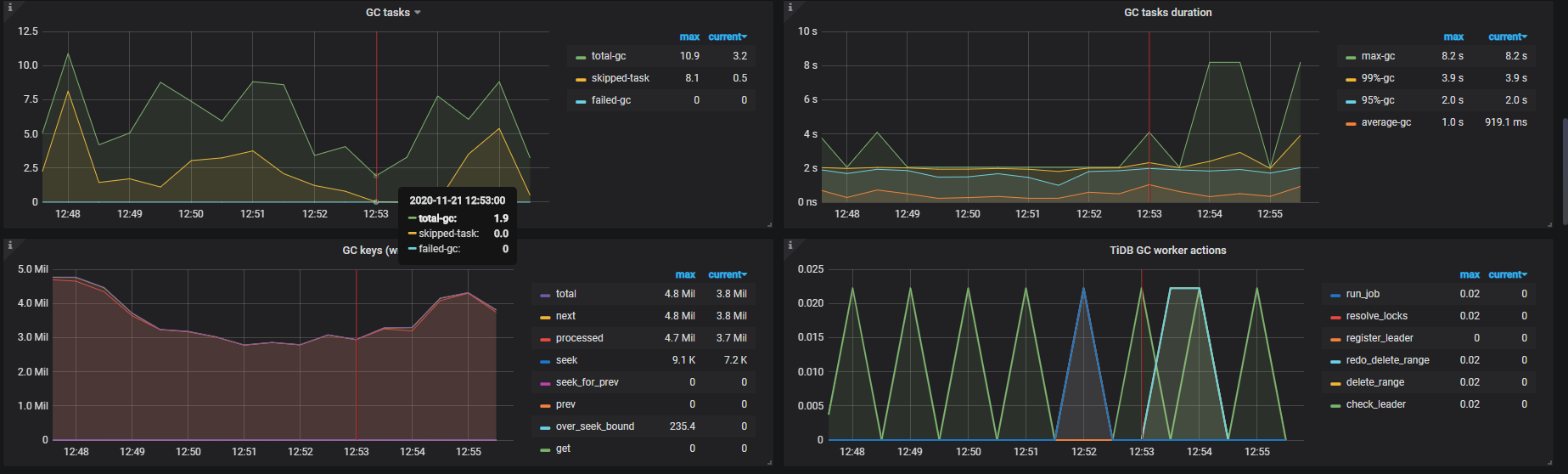
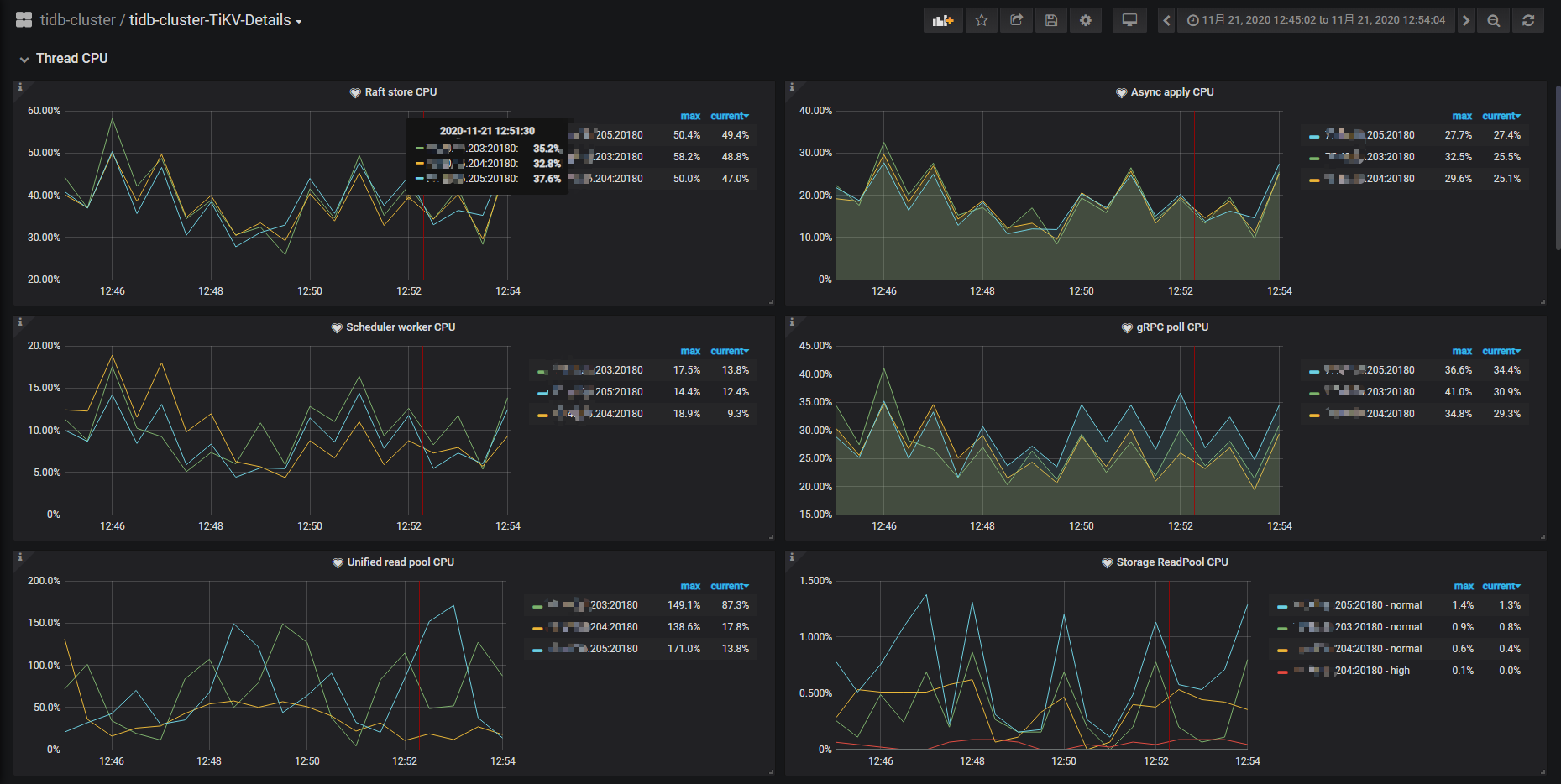
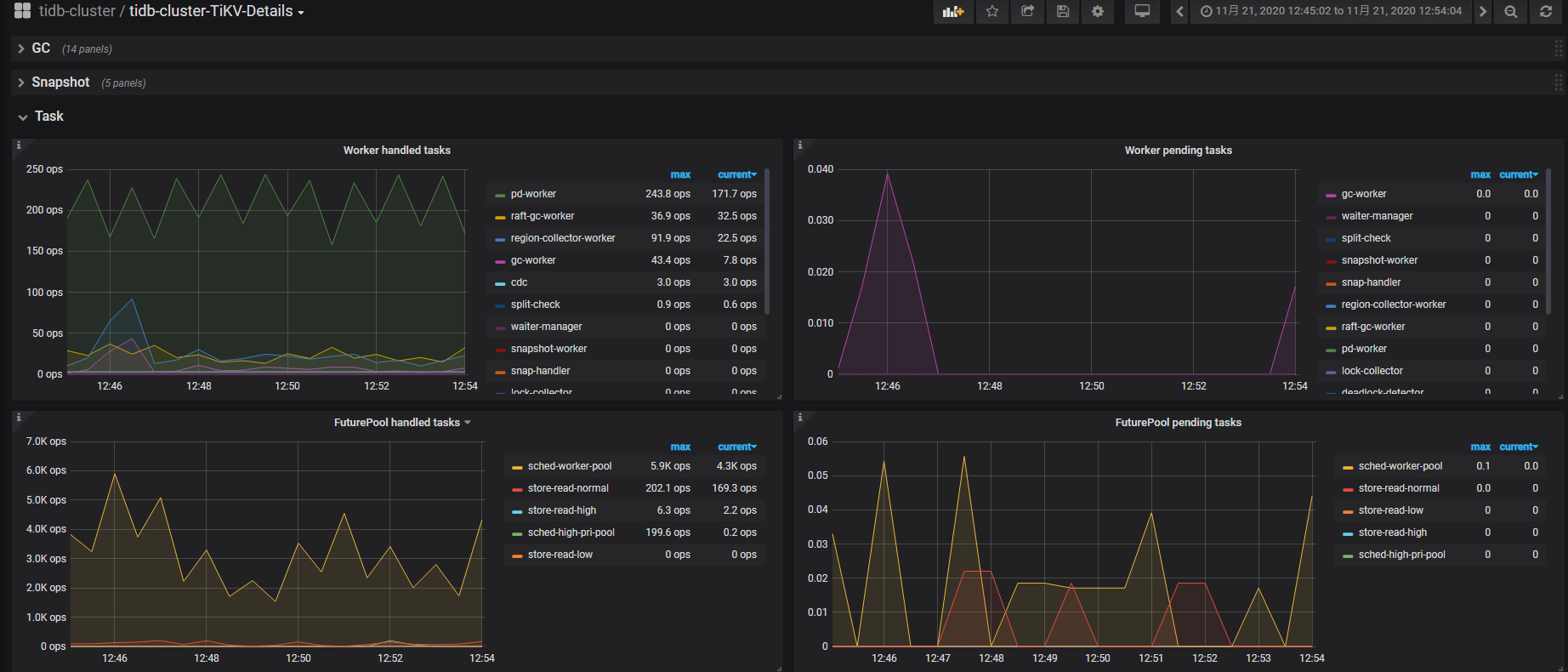
2、查看 tidb 下的 kv duration 、tikv-detail下的 thread cpu、raft-kv 下的指标,还有 task 下的监控指标
overview面板信息
tidb-kv duration 这个信息我不知道指的具体是哪个,下面是我猜的
tikv-detailsx下的 threadcpu
raft-kv这个信息也不知道具体是哪个,没有找到标签
task信息
下面将 tidb 和tikvdetails 面板页截图 供参考选择
以上所截取的面板信息,都是那条sql发生时间段内半小时的 面板情况
spc_monkey
(carry@pingcap.com)
5
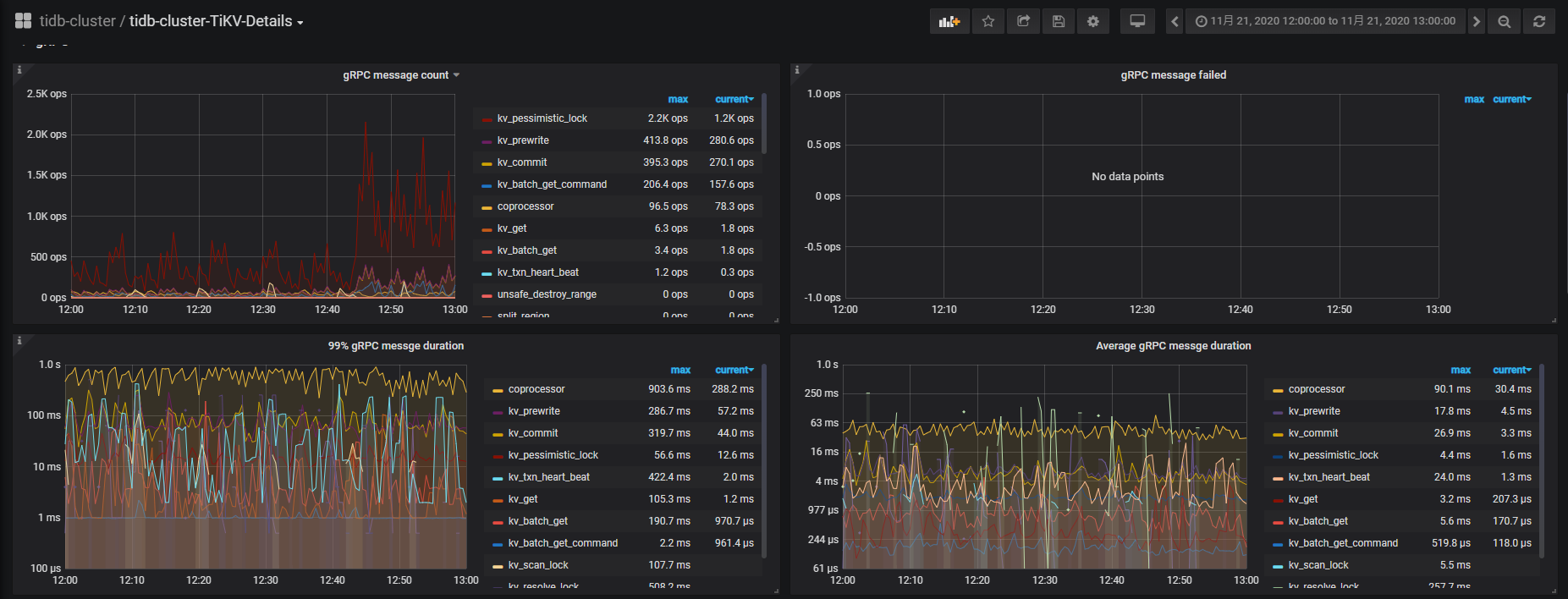
监控看起来集群压力很小,数据库内部执行速度也比较快,不过 tidb-server 下的 kv duration 比较长,所以需要看看 tikv-detail 下的 grpc 下的 grpc duration 是否高,如果不高,则需要看看各服务器之间的网络问题(blackbox—exporter 下看 ),重点排查一下网络吧,grpc duration 信息补充一下,
补充grpc 信息,问题语句发生时间是12:53左右,确实发现grpc duration一下子飙升,锁冲突比较多?
、
spc_monkey
(carry@pingcap.com)
7
再提供一下
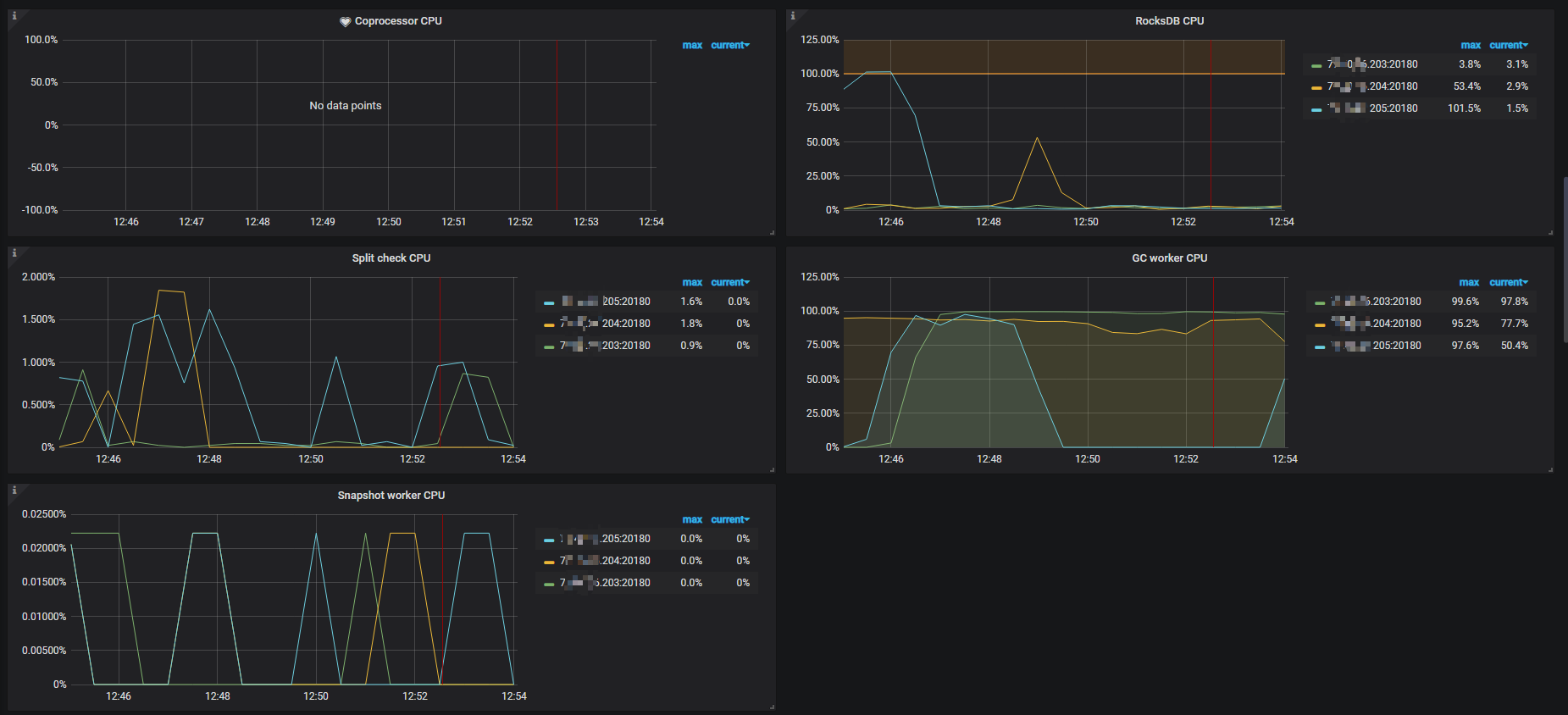
1、tikv-detail 下的 coprocessor detail 及 coprocessor overview 下的所有指标,还有 rocksdb-kv 下的所有监控指标(如果太大,可百度网盘)
2、检查 tidb-server 与 tikv-server 之间的网络,看监控 blackbox——exporter
spc_monkey
(carry@pingcap.com)
8
麻烦再给一下 这个监控指标:TiKV-Detail -> Coprocessor Overview -> Total Response Size**