[tidb@node4107 v4.0.7]$ export ETCDCTL_API=3
[tidb@node4107 v4.0.7]$ ./etcdctl get --prefix /tidb/cdc --endpoints=http://172.16.4.107:12379 > etcd.log
辛苦在试下.
总结一下目前的分析
- 主贴里最初出现的
rpc error: code = ResourceExhausted desc = trying to send message larger than max (12331115 vs. 2097152)问题,目前猜测是需要同步的表数量过多(包含分区表,每个分区计数 1);因为从截图和日志都可以看到"filter":{"rules":["*.*"],代表同步了所有表 - 反馈修改了 filter 之后可以同步,这个符合预期
- 截图 DDL 被忽略的问题,因为 DDL 涉及到的表没有在 filter 里匹配,所以会忽略该 DDL
- 日志里
[2020/11/05 23:43:23.366 +08:00]和[2020/11/05 23:47:52.062 +08:00]cdc server 分别重启了两次,这个需要 cdc_stderr.log 定位是否有 panic,也可以通过 dmesg -T 查看是否有 OOM killer 杀掉 cdc 进程 - CDC 正常运行过程中不应该占用特别多内存,一般超过 10G 的场景通常是出现了同步阻塞,或长时间增量扫数据的情况。所以出现 cdc 内存占用突然增高时,要优先查看是否同步阻塞,或者下游同步速度跟不上。(目前已知的 cdc 如果任务停掉过久,滞留的数据量过多新启动任务会出现 OOM,正在 https://github.com/pingcap/ticdc/pull/972 中进行优化)
现在又挂了,应该是太耗内存了。是不是过滤指定的表会好很多?
- 是运行一段时间挂了,还是重新拉起任务时候挂了
- 可以提供一下监控的信息么
./cdc cli changefeed list --pd=http://172.18.115.34:2379
[
{
“id”: “binlog-a20040002”,
“summary”: {
“state”: “normal”,
“tso”: 420711875854205482,
“checkpoint”: “2020-11-09 10:20:42.437”,
“error”: null
}
},
{
“id”: “binlog-a20070032”,
“summary”: {
“state”: “normal”,
“tso”: 420711873704624140,
“checkpoint”: “2020-11-09 10:20:34.237”,
“error”: null
}
},
{
“id”: “binlog-a20080057”,
“summary”: {
“state”: “normal”,
“tso”: 420712354476720261,
“checkpoint”: “2020-11-09 10:51:08.237”,
“error”: null
}
},
{
“id”: “binlog-ctyg”,
“summary”: {
“state”: “normal”,
“tso”: 420711873193443466,
“checkpoint”: “2020-11-09 10:20:32.287”,
“error”: null
}
},
{
“id”: “binlog-liyuan-xinyi-rbs”,
“summary”: {
“state”: “normal”,
“tso”: 420711871410864495,
“checkpoint”: “2020-11-09 10:20:25.487”,
“error”: null
}
},
{
“id”: “binlog-sanlian”,
“summary”: {
“state”: “normal”,
“tso”: 420711873704624140,
“checkpoint”: “2020-11-09 10:20:34.237”,
“error”: null
}
}
]
kafka 没消费到数据,checkpoint 停留在上午。但是生产环境是一直有数据变更的
从监控或者日志 [INFO] [statistics.go:118] ["sink replication status"] [name=MQ] [changefeed=binlog-test] [captureaddr=172.18.112.20:8300] [count=37] [qps=1] 可以看到 是否有 kafka 消息发送
cdc 今天的运行日志可以提供一下么
changefeed 为 binlog-test 的任务已经删除了。现在只有上面提供的6个changefeed
11/09 的日志看运行正常,第一次 cdc server 重启发生在 [2020/11/09 10:21:17.389 +08:00]
麻烦再确认几点,在 OOM ([2020/11/09 10:21:17.389 +08:00])之前
- 下游的同步速度能否跟得上上游
- 监控里 cdc 的内存变化情况
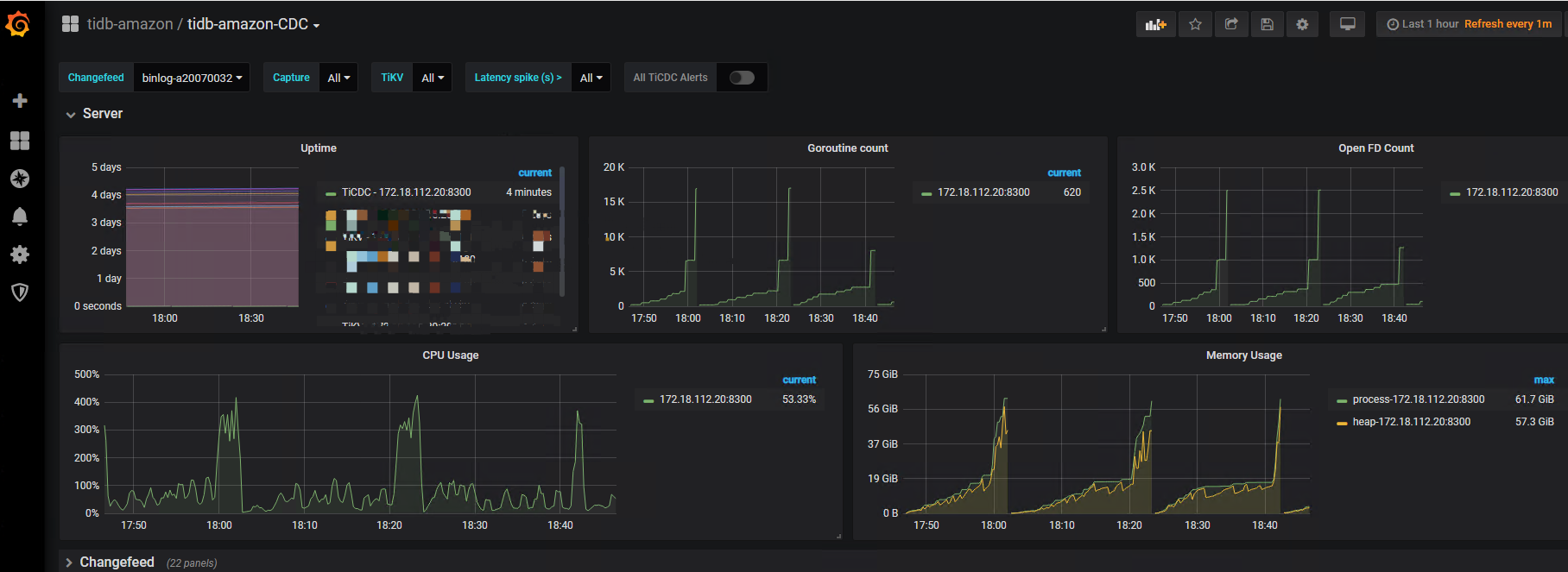
cdc 重启后会恢复任务
但现在的问题是追数据过程需要把增量数据完全扫一遍,从监控看追的数据量过多导致 OOM,所以数据一直没有追上。(PS:这个问题已经再优化)
-
当前的处理手段只能是清理部分任务,重新开始
-
因为多个任务都在一个 cdc 节点,这个节点的内存压力确实会比较大
-
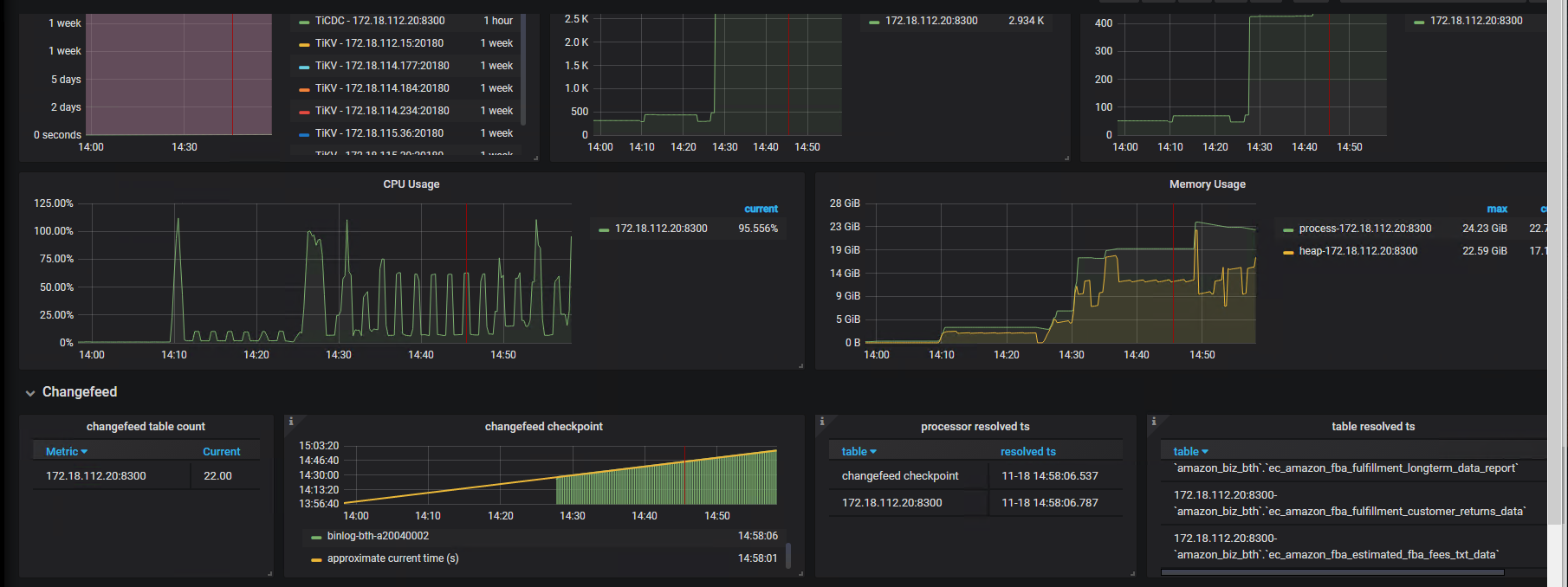
能否拉大一下时间段,提供一下10点之前的监控截图

正常运行的内存大约在30-37G上下浮动,平均一个任务占用 5~6G,稍微偏高,但感觉也算合理,具体内存分布可能需要 pprof 获取一下。然后10:20 可能是流量突增导致 OOM 了。这里可以多部署几个 cdc 节点么,平均一下负载。
如果能帮获取一下 pprof,可以进一步定位内存分布。获取的方法是正常运行 cdc 同步任务之后,通过 cdc 的 http status 接口获取
curl -s http://172.18.112.20:8300/debug/pprof/heap?debug=1 > heap_debug.log
curl -s http://172.18.112.20:8300/debug/pprof/heap > heap.log
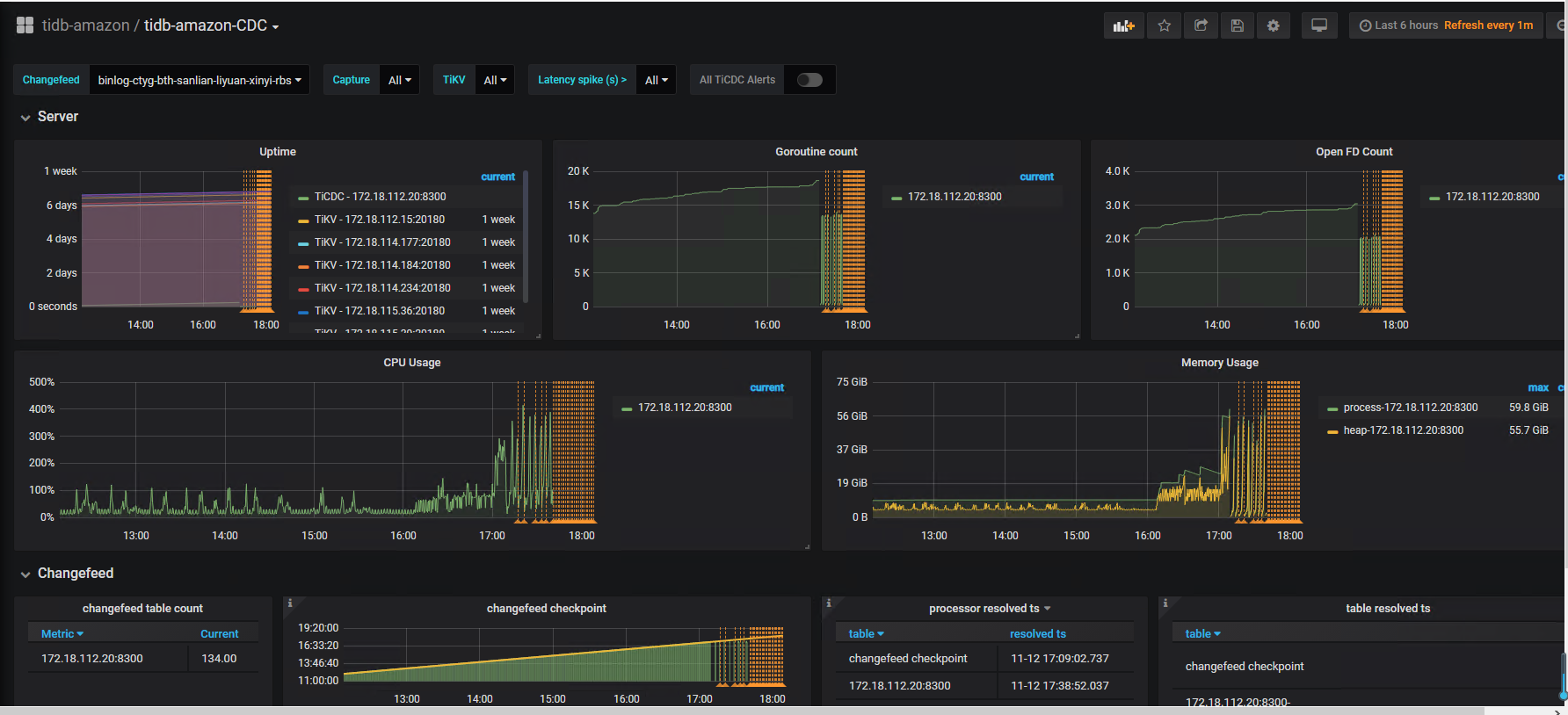
任务是上午搭建的,下午就挂了。62G 内存