yarthur
(Yarthur)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:
Release Version: v4.0.6
Edition: Community
Git Commit Hash: 51d365fc45fdfc039eb204a96268c5bd1c55075f
Git Branch: heads/refs/tags/v4.0.6
UTC Build Time: 2020-09-15 09:50:30
GoVersion: go1.13
Race Enabled: false
TiKV Min Version: v3.0.0-60965b006877ca7234adaced7890d7b029ed1306
- 【问题描述】:
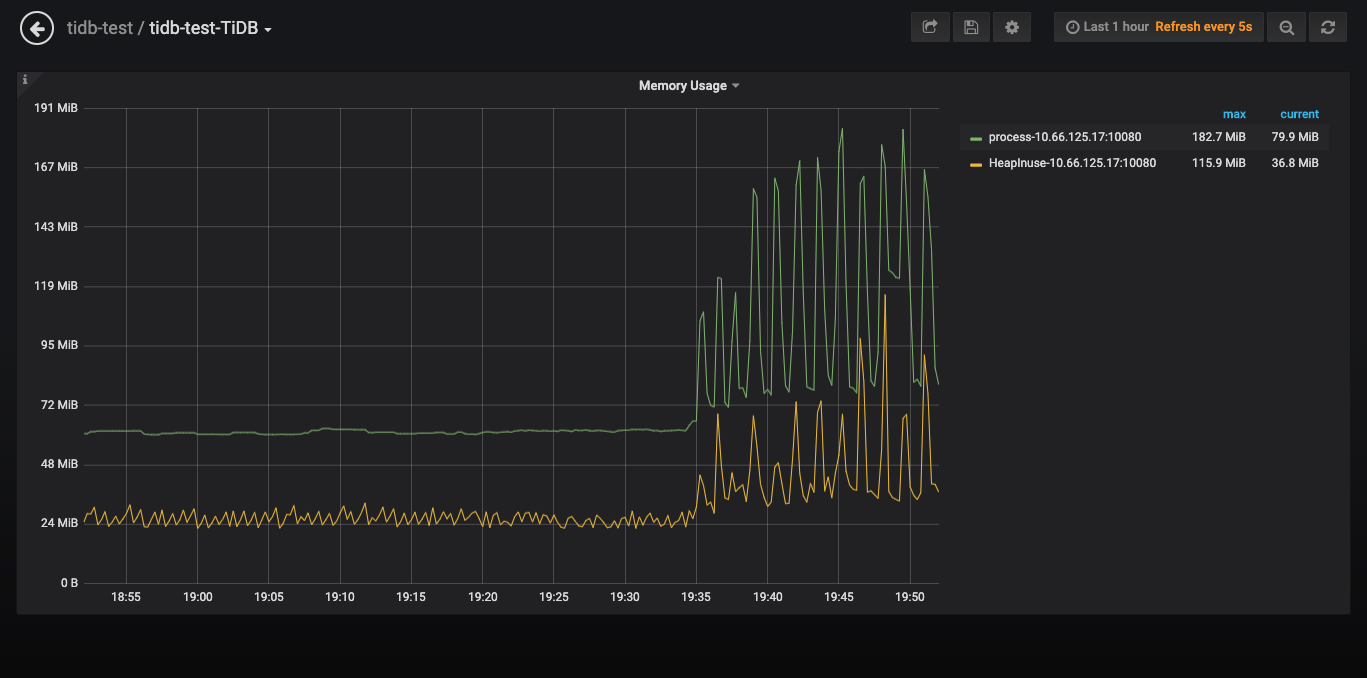
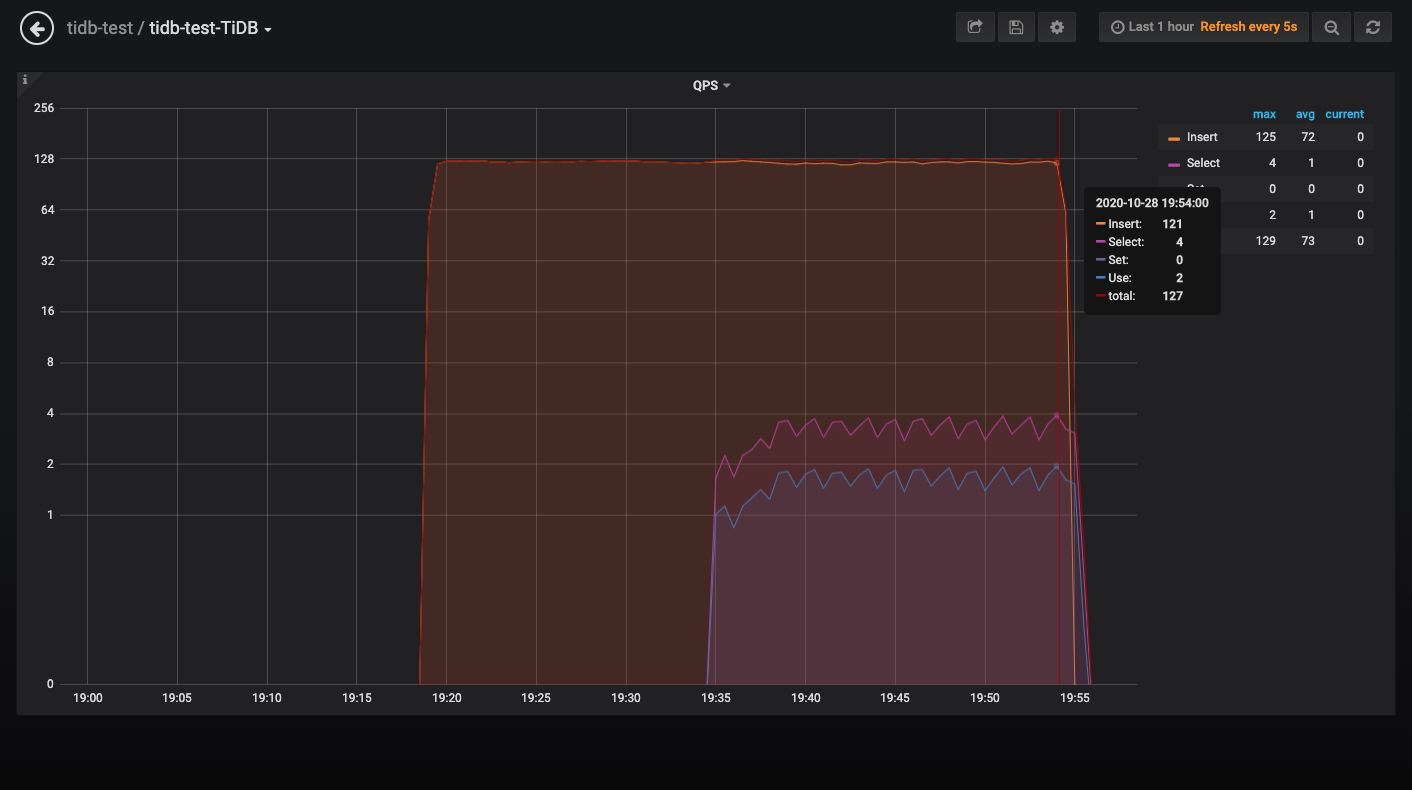
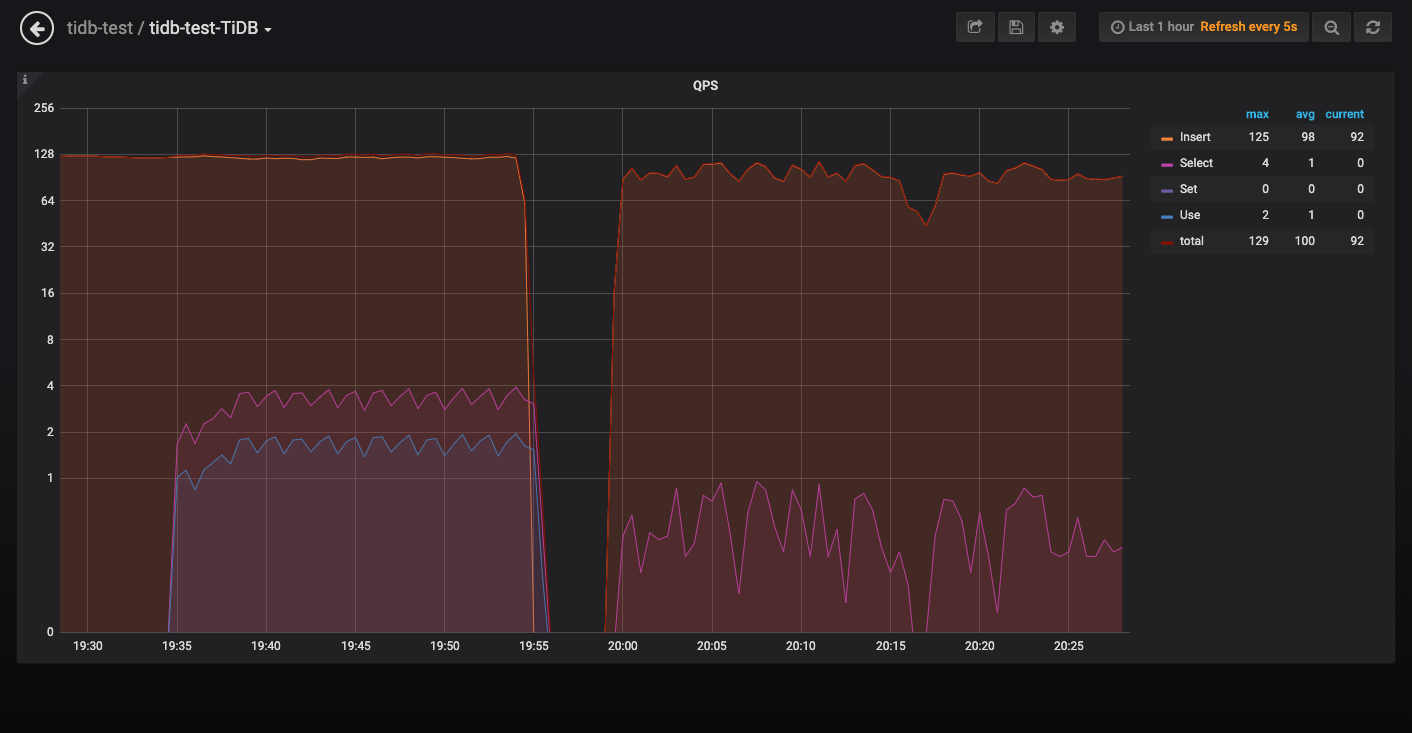
最开始是测试程序只insert 数据,用一个脚本执行聚合select,内存的占用100多M,CPU利用10%以下
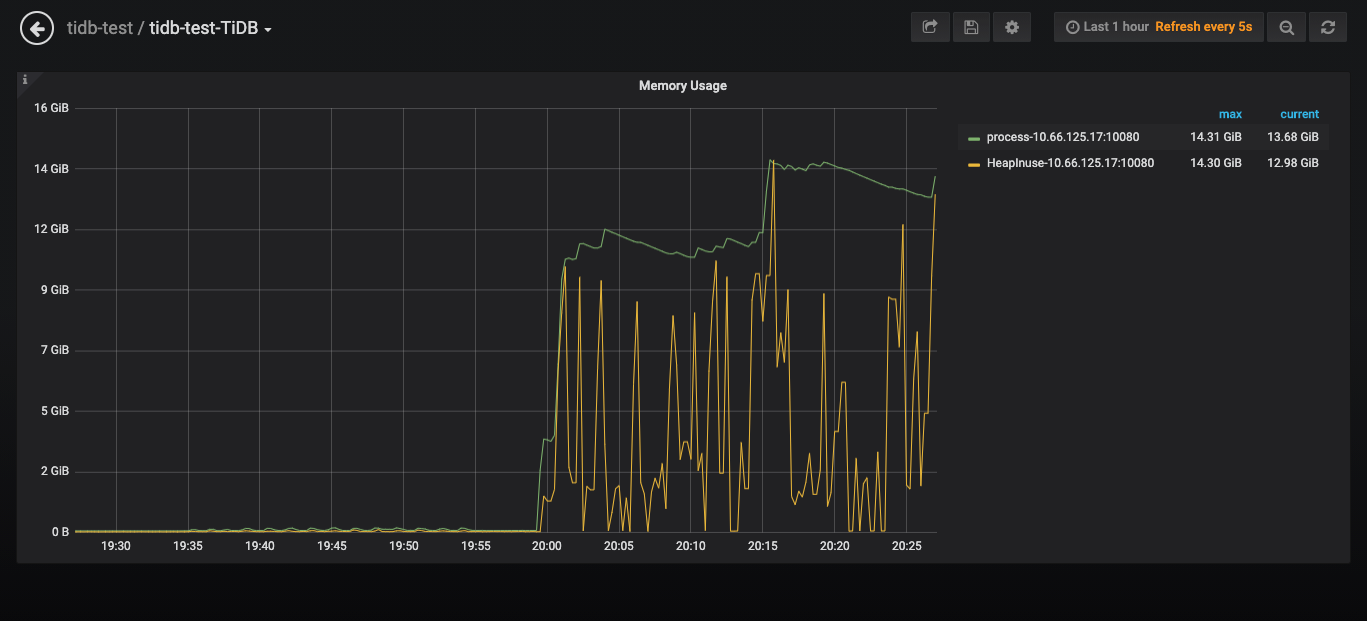
测试程序如果同时插入和执行聚合select,唯一的区别就是脚本执行select是每次重新建立连接(mysql -h 10.x.x.x -u root -P 4000 -D lXvXXX -e “SELECT ……”),测试程序执行聚合select用的是SQL的连接池,发现tidb的内存会急速上升到10多个G,CPU也上升的比较明显。
这个聚合查询我在SQL里面指定了走tiflash,查看tidb的日志发现这个慢查询的Mem_max在200多M,select的并发也不高只有2-3.如果将测试停了过一段时间后内存会恢复正常。
我想知道这种现象是正常的吗,因为复用连接导致一些数据没办法GC?
yarthur
(Yarthur)
3
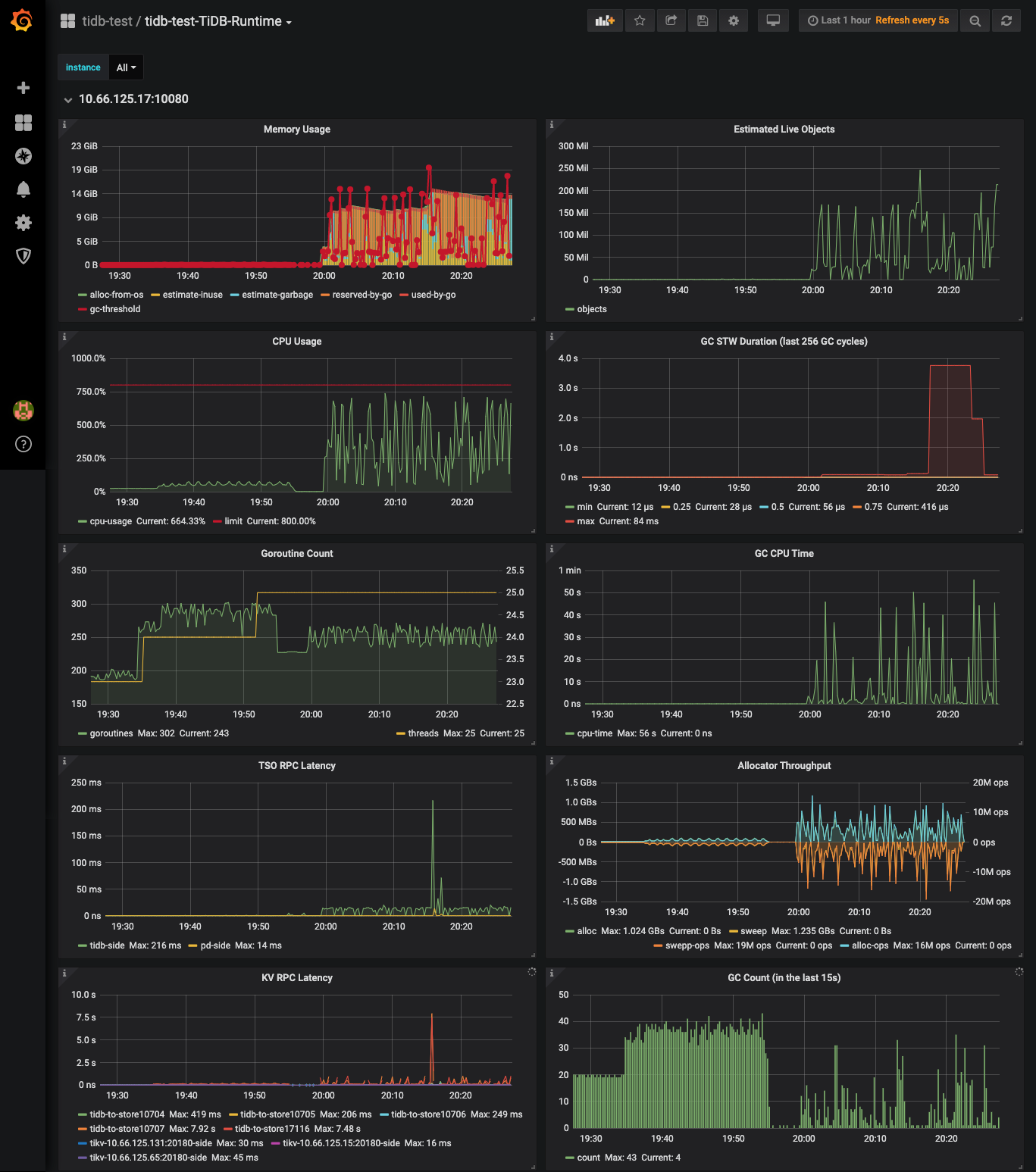
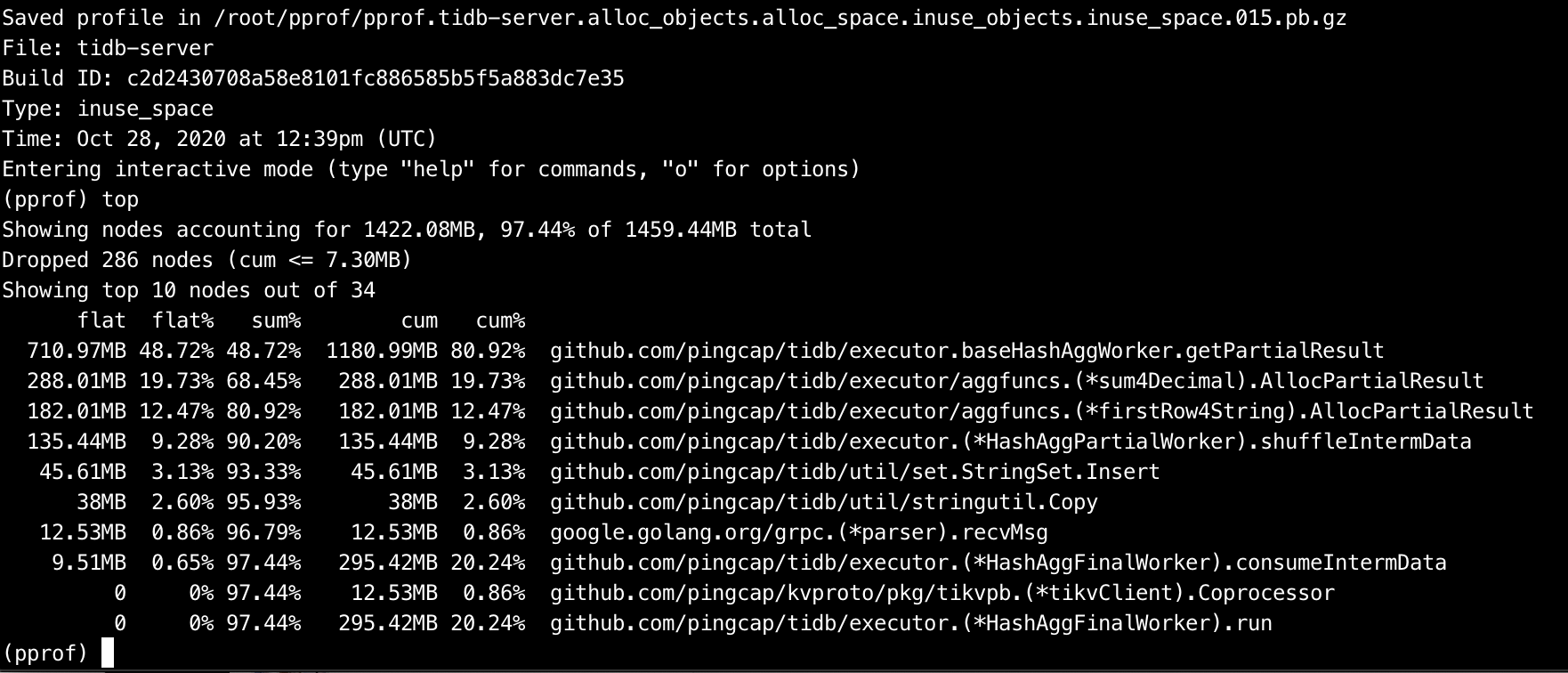
用pprof看内存的使用并不多,应该是没有gc导致的
yilong
(yi888long)
5
curl -G http://{TiDBIP}:10080/debug/zip?seconds=30" > profile.zip 抓一个内存占用多时的profile,麻烦上传下。
yarthur
(Yarthur)
8
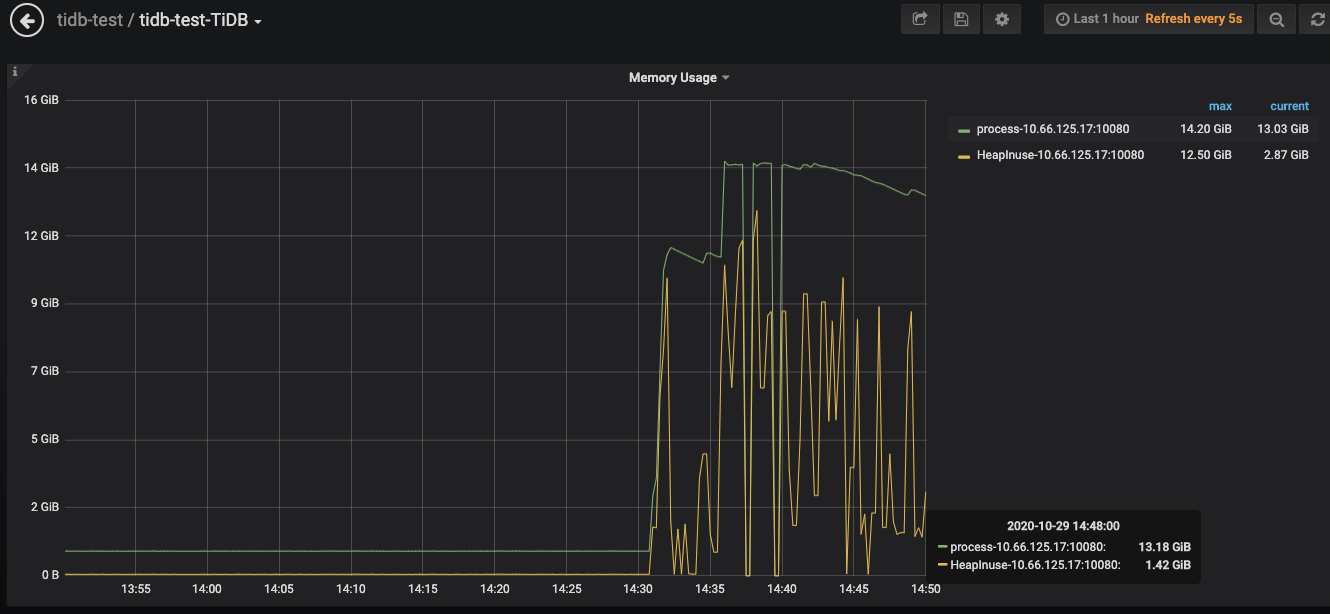
这个是今天12点的是吧 那个时候看监控其实从操作系统层面内存占用挺大的,我等下再重新上传一个
yarthur
(Yarthur)
11
1、进程是 tidb-server
2、下面是tidb-server所在机器的 cat /proc/meminfo内容
MemTotal: 15791360 kB
MemFree: 3126064 kB
MemAvailable: 3039372 kB
Buffers: 3108 kB
Cached: 217632 kB
SwapCached: 44280 kB
Active: 11993812 kB
Inactive: 388616 kB
Active(anon): 11976140 kB
Inactive(anon): 278208 kB
Active(file): 17672 kB
Inactive(file): 110408 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 5242876 kB
SwapFree: 4385188 kB
Dirty: 80 kB
Writeback: 0 kB
AnonPages: 12143668 kB
Mapped: 79240 kB
Shmem: 92660 kB
Slab: 77040 kB
SReclaimable: 33456 kB
SUnreclaim: 43584 kB
KernelStack: 5376 kB
PageTables: 40056 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 13138556 kB
Committed_AS: 14633400 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 36572 kB
VmallocChunk: 34359697320 kB
HardwareCorrupted: 0 kB
AnonHugePages: 131072 kB
CmaTotal: 0 kB
CmaFree: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 155620 kB
DirectMap2M: 6703104 kB
DirectMap1G: 9437184 kB
请问一下,后面的查询并发量和每次查询的数据量和之前有区别么?
Mem_max 没能统计到 TiDB 处理 TiKV 返回的二进制数据时消耗的内存。如果是比较复杂的查询,返回的数据量会比较大,这里的内部并发也会比较高一点,所以会出现一个瞬时的内存占用峰值。
因为 Go 自身的设计,当出现一个瞬时峰值之后,它不会立即归还所有的内存还给操作系统,而是以一个比较慢的速率逐渐归还,所以会发现 TiDB 的进程占用一直比较高。这个在监控里就是 reserved-by-go,这部分内存最终会归还给 OS,后续的堆空间增长也会重复利用这个部分。
yarthur
(Yarthur)
14
查询并发量没什么区别,因为测试时sql语句的时间范围是随机生成的,每次SQL查询的数据量都会不一样,但用shell脚本和go database/sql测试时间范围都是随机生成的,还有一点就是我的SQL指定了走tiflash;
其实我看那个监控图也明白GC回收不会那么快,我想知道的是用shell脚本直接执行mysql 查询和用database/sql库的底层有啥区别:joy:
我的测试程序使用的是go database/sql库,我改为查询不复用连接的测试结果和复用连接的结果一样:joy:
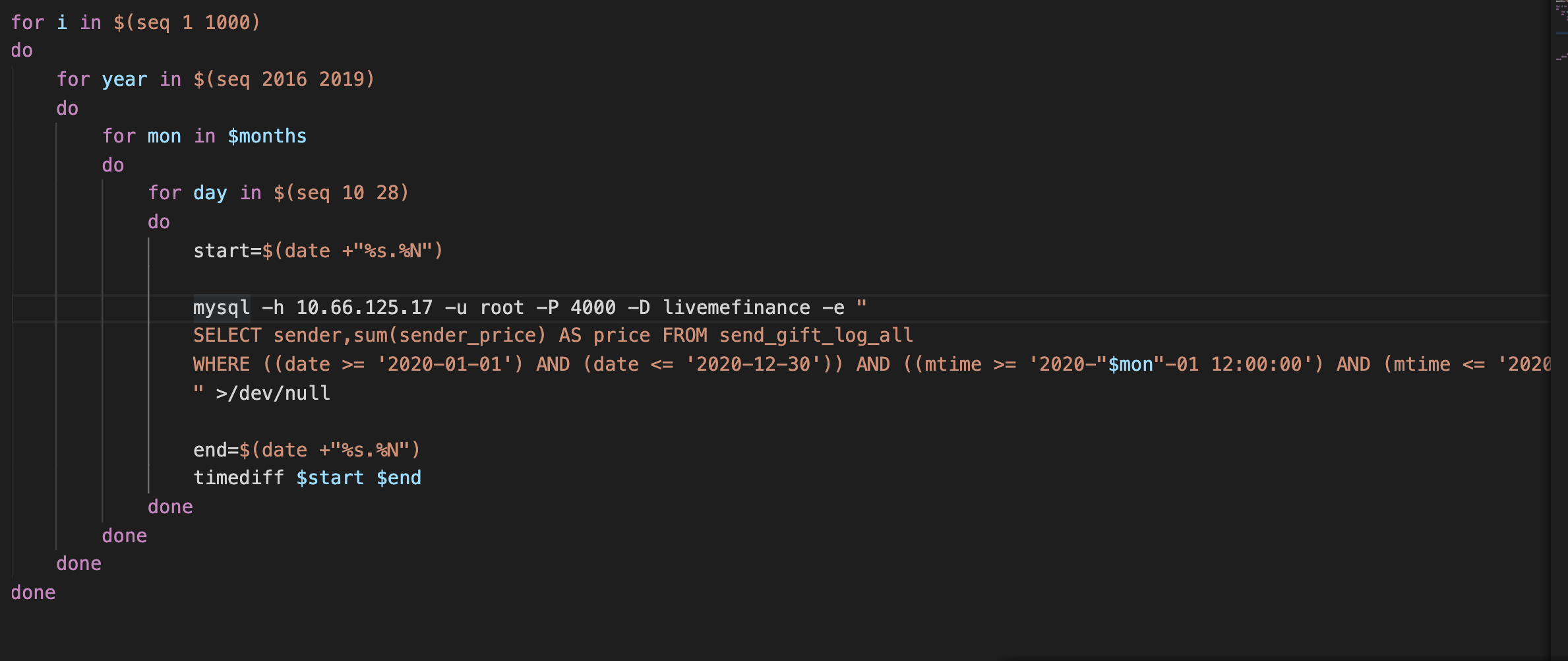
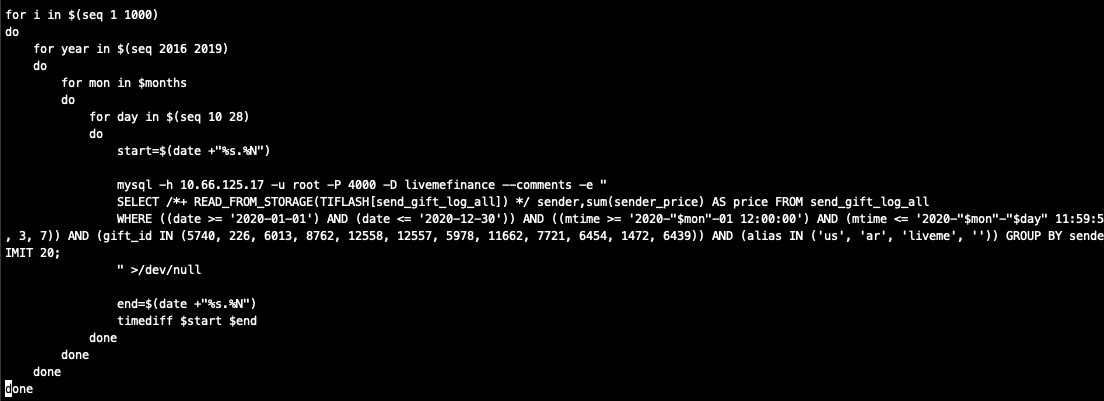
我不知道用shell脚本直接执行mysql 查询和用database/sql库的底层有啥区别,用shell脚本查询不会有内存升高的情况;下面是我的shell脚本和测试代码
是说 shell 执行的时候没有 tiflash hint,用 database/sql 的时候加了 tiflash hint 么?
如果是这样的话,能否尝试一下 go 也不加 tiflash hint?
yarthur
(Yarthur)
16
不是 都加了 tiflash hint:joy:
就很奇怪shell mysql 查询和用database/sql库的底层有啥区别
那个图是之前的
yarthur
(Yarthur)
17
我发现shell的时间范围是顺序的,数据可以重复利用,而测试程序的时间范围是随机生成的,不存在连续性 是这个原因吗
是这个原因吗
嗯,shell 脚本的看起来查询范围是逐渐变大的,这样有多个脚本并发查询的时候也是从多个小查询变成多个大查询。测试程序的范围就不一定,可能会出现同时有多个大查询。或者查询的数据量比 shell 多。
tidb_slow_query.log 里应该会记录下耗时久的查询,可以调节 https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file#slow-threshold 配置项来收集更多的日志。从这里可以对比一下,这两种方法产生的参数的范围,Num_cop_tasks 还有 Mem_max 是不是有区别。
yarthur
(Yarthur)
19
好的 我后面试下
还有个问题是像 select limit n这样的查询走tikv 和tiflash有区别吗 tiflash是返回大量的数据然后由tidb 取n条?