qiyou
(Qiyou)
1
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:v4.0.6
- 【问题描述】:同样的查询在clickhouse下耗时是1秒左右,使用了TiFlash引擎后,耗时瞬间加到了接近20秒,整表数据量大概3千万,TiFlash引擎底层使用的也是clickhouse,请问有什么好的优化方案吗?
我自己单独尝试过如果是只执行里面子查询部分的查询速度是很快的,整体执行只是加多了个group by,效率相差这么远?
tidb_slow_query.log (4.5 KB)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出打印结果,请务必全选并复制粘贴上传。
qiyou
(Qiyou)
2
不懂就问
(zhouyueyue)
3
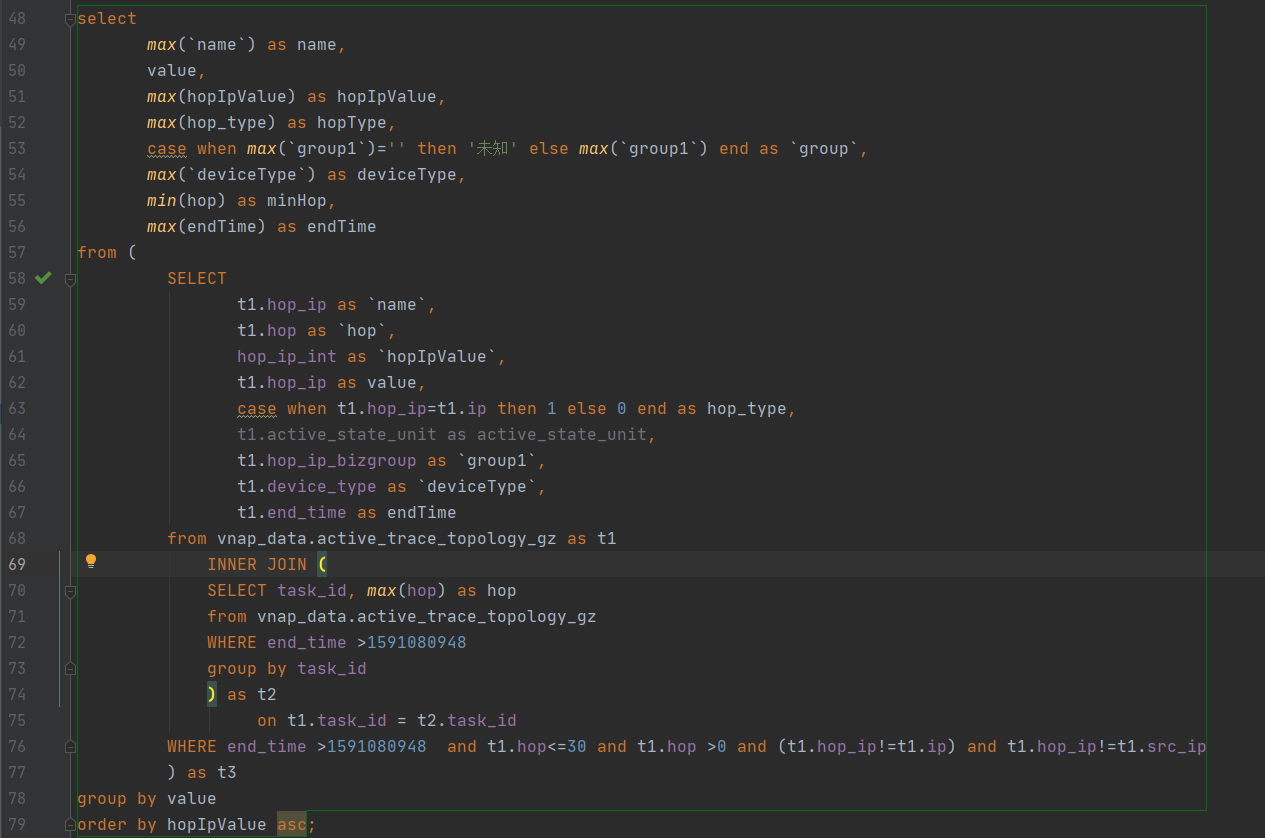
请问下 SQL 语句里面的两个 join 操作对应的 t1 和 t2 数据量大概多少?
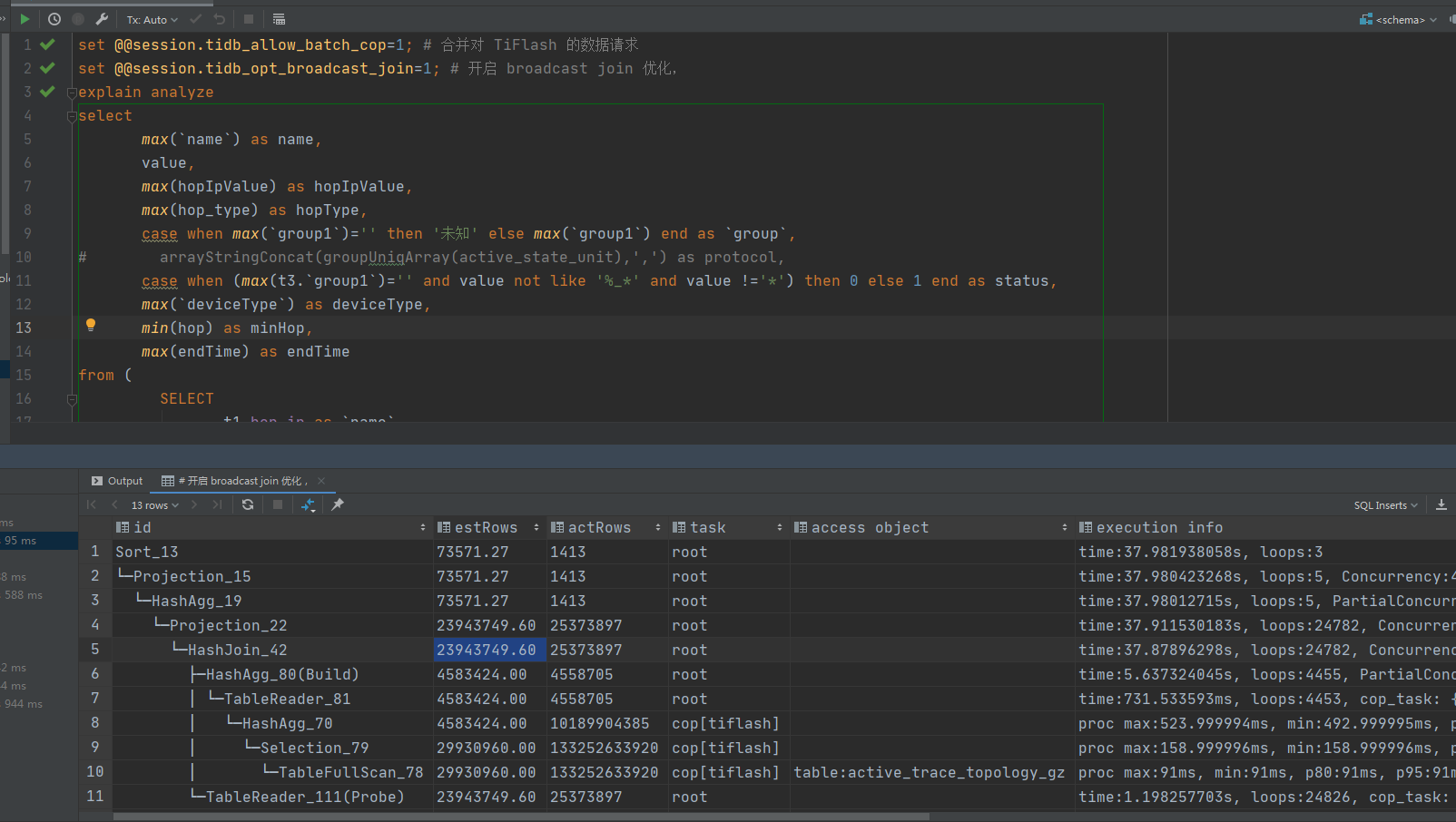
你好,从 explain analyze 结果来看,目前主要耗时是在 TiDB 节点中做 join 操作。4.0.6 版本可以尝试开启以下优化项:
set @@session.tidb_allow_batch_cop=1; # 合并对 TiFlash 的数据请求
set @@session.tidb_opt_broadcast_join=1; # 开启 broadcast join 优化,即尝试把 小表 join 大表 的操作下推到 TiFlash 节点
qiyou
(Qiyou)
5
自己join自己,大概3000万,直接执行里面的子查询速度其实不算慢,但是整体执行却很慢,不太清楚是什么原因导致的。
qiyou
(Qiyou)
6
好像更慢了,问题是出在join,但join如果是在TiFlash节点做的话应该很快的才对。
qiyou
(Qiyou)
8
qiyou
(Qiyou)
9
和我的建表索引会不会有关系?我不清楚在mysql接口定义的索引同步到TiFlash后是什么样的情况。还有就是TiFlash的数据怎么做分区?如果我要建一个按天做分区的表应该怎么做?
非常遗憾,这个 SQL 目前 TiDB 确实无法下推,因为它 join 的一边是 agg。我们目前正在优化这个问题。
关于 TiFlash 的分区,和正常 TiDB 分区表的使用方式是一样的,可以参考 https://docs.pingcap.com/zh/tidb/stable/partitioned-table#分区表
qiyou
(Qiyou)
11
agg指的是什么?join自身都会有这个问题吗?还是说全部的join操作都会有这种问题?
(
SELECT task_id, max(hop) as hop
from vnap_data.active_trace_topology_gz
WHERE end_time >1591080948
group by task_id
) as t2
这条 SQL 需要做 t1 join t2,然后 t2 是一个聚合(aggregation)的结果,因为有 group by。TiDB 目前对于这种情况无法将 join 下推到 TiFlash 节点进行计算,即使已经设置了 set @@session.tidb_opt_broadcast_join=1;
当前版本可以考虑用 TiSpark。另外 TiDB 会尽快支持类似的复杂查询下推,提升查询效率。
system
(system)
关闭
15
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。