为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.12
- 【问题描述】:集群的某些节点夜间会报cpu load过高,看了下相关的慢日志和监控发现夜间的业务量并没有白天高但是告警却只在晚上出现,目前发现的一个异常是告警时段内coprocessor cpu会很高,慢日志就一条insert SQL on duplicate update的SQL,执行次数也只有2000多次/半小时;其他诸如raftstore cpu都比较正常,请问我还能从哪些方面来排查这个问题~
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
上面慢日志统计的 insert SQL 不应该导致 coprocessor cpu 抖动,可能是其他 SQL 导致的,麻烦导出 tidb 和 tikv-details 的监控看下,参考 [FAQ] Grafana Metrics 页面的导出和导入
表扫描+selection 有明显的上涨
grep slow-query tikv.log 查一下,如果有 slow-query 会打印 region_id,根据 region_id 查询表信息
curl http://{TiDBIP}:10080/regions/{regionID}
Hi:
这个集群目前就两个表的数据超过千万,目前慢查询insert也只涉及这两个表,一个5E一个20E数据。
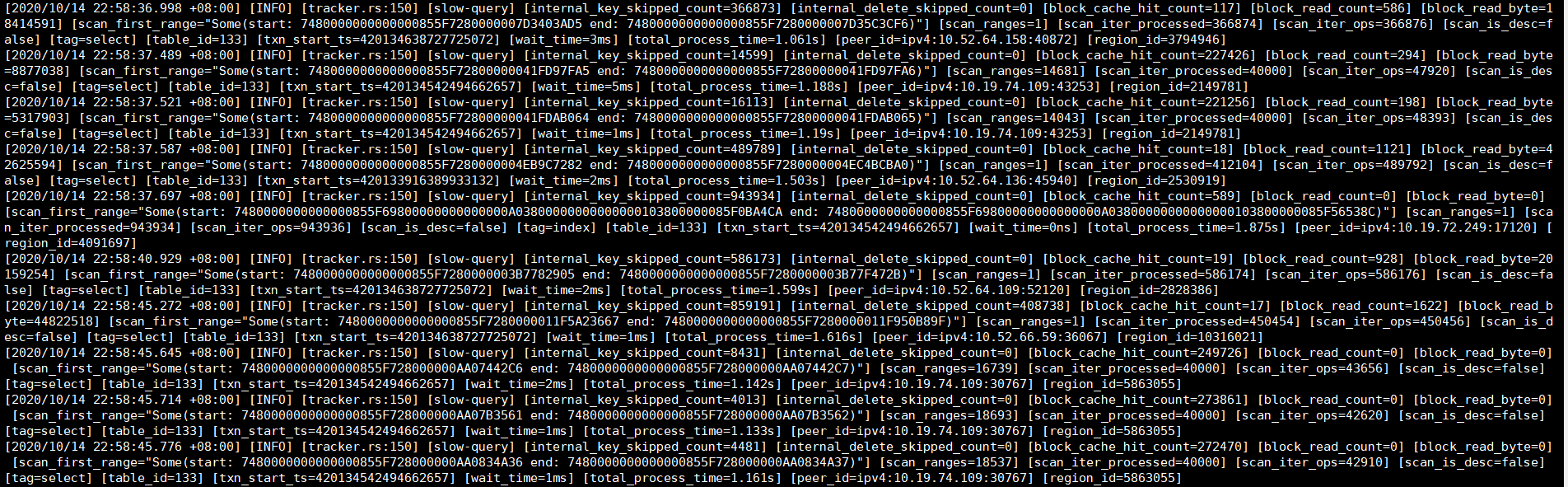
慢日志中显示的是5E表的insert,tikv.log显示的是另一个20E表的slow query,信息基本如下:
curl其中一个region信息如下:
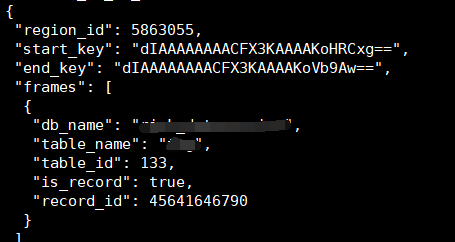
show table regions where region_id=5863055显示此region是一个follower peer,大小比较常规:62MB约24W5的keys
可以确认下
tikv 日志中的慢查询最早出现是什么时候,监控上抖动的时间范围是 22:33-23:58,日志和监控是否对得上
tikv 日志有记录 txn_start_ts,用这个 ts 去 tidb slow query 日志中搜索看能不能找到慢查询 SQL
tikv里的slow-query几乎无时无刻不在报,所以是涵盖了抖动时段的。
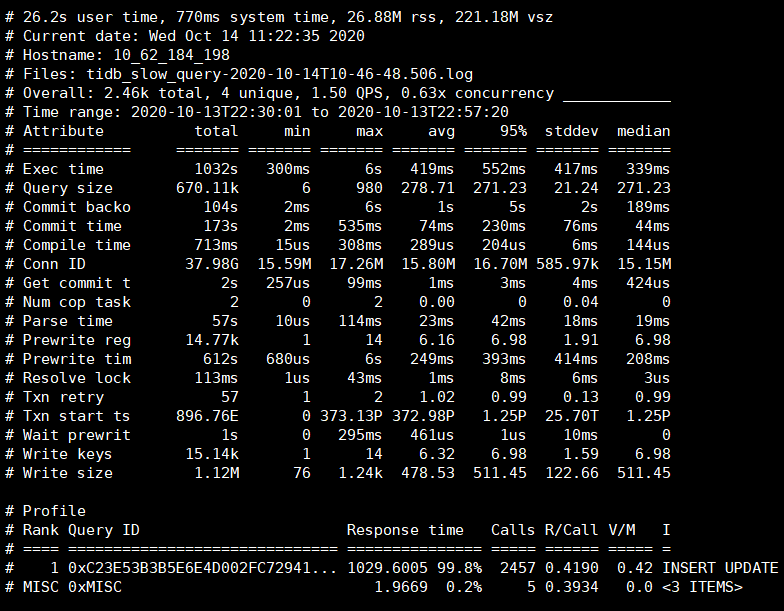
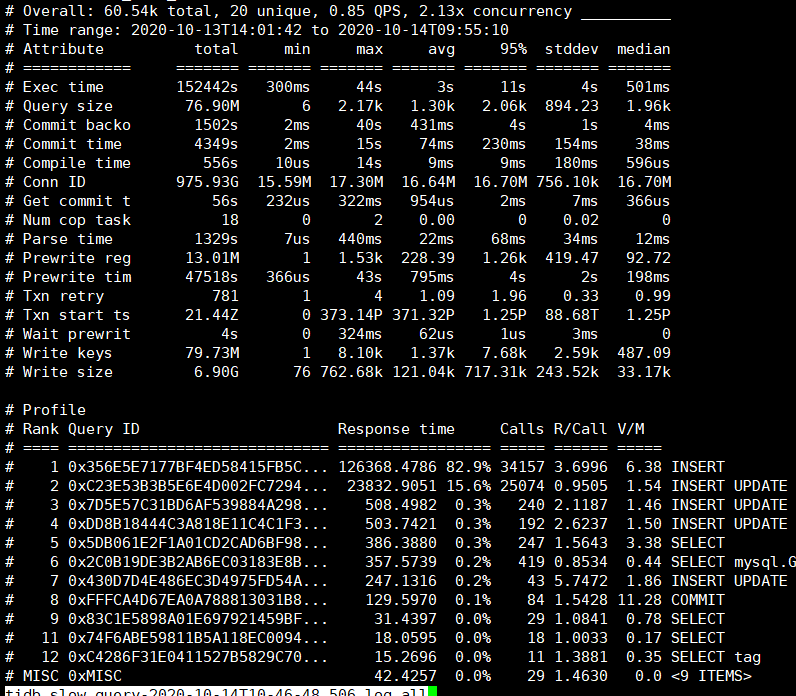
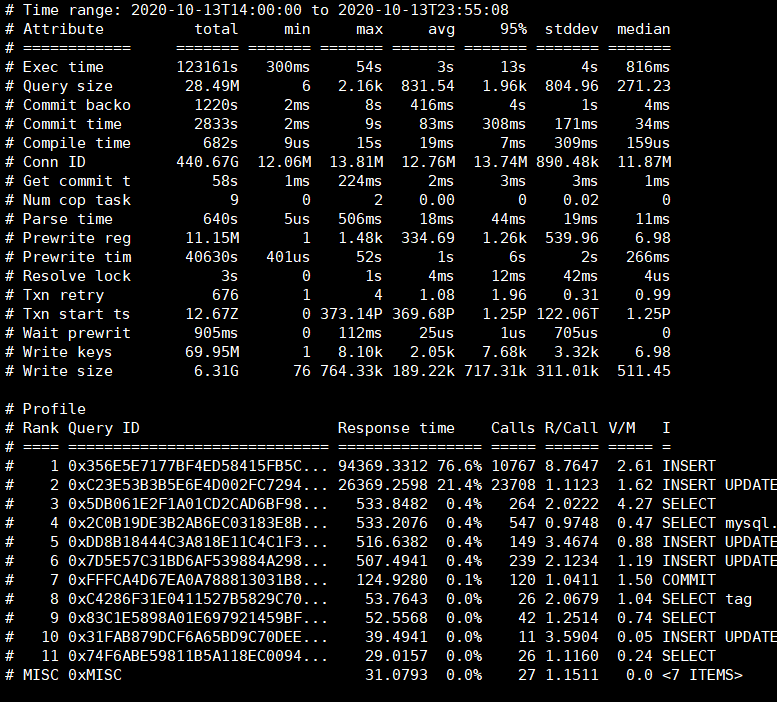
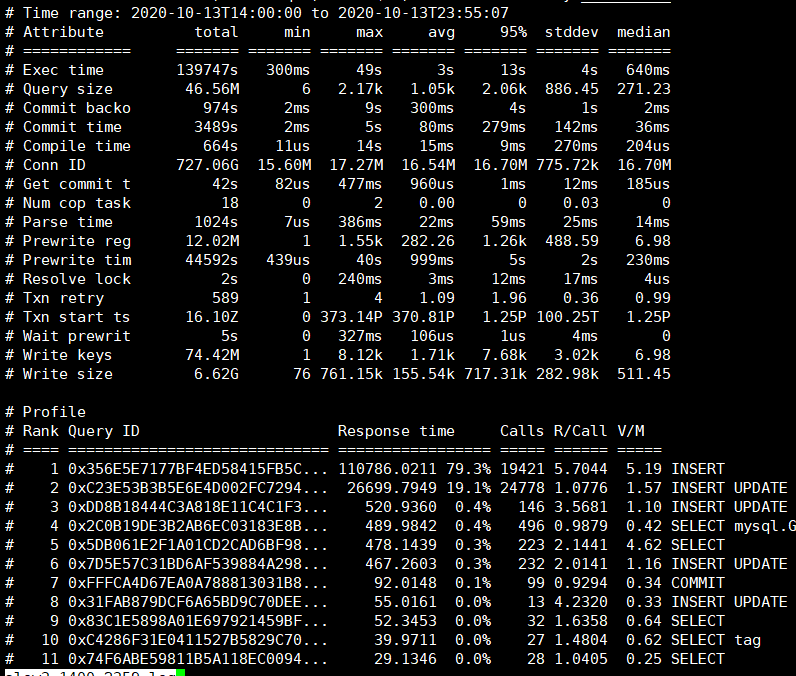
由于这个抖动是周期性的(每晚22-23点以及0点到1点之间),时间段也固定,所以如果tidb有大的慢查询也应该不会跨天,我直接选了13号14:00到23:59的tidb慢日志,并未发现特殊的慢查询。
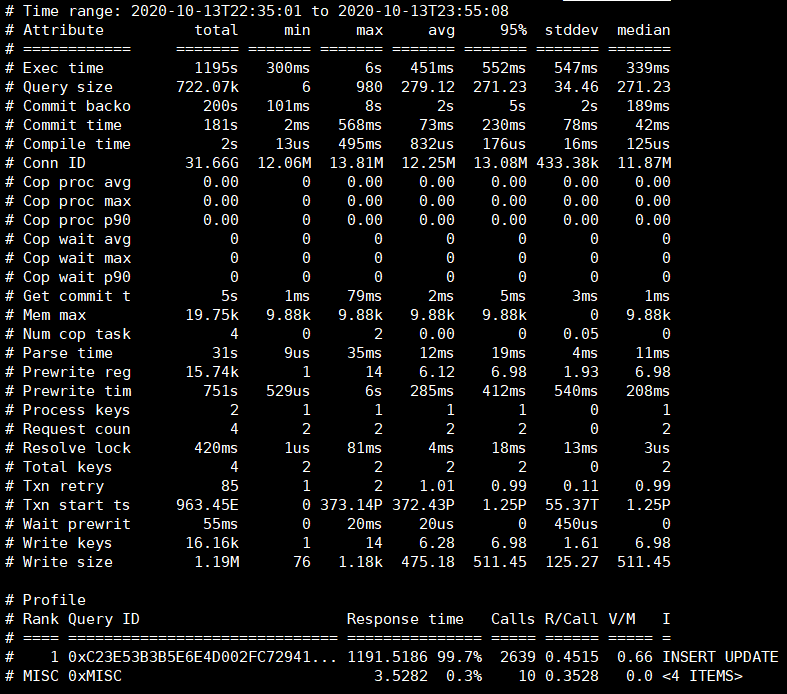
相应时段的tikv日志(包含问题节点3个tikv实例的日志)和tidb慢日志统计我都贴在了附件中。
链接:https://pan.baidu.com/s/1reUPSJOs1fKUyYHAjsRo0A
提取码:l1u1
Ps:这个集群就一个业务库,里边除了上述提到的2个表之外最大的也不超过50W条,那两个大表就是出现在tikv日志中id为133和231的两个。
感谢~
tikv 日志中下面两个 txn_start_ts (2020-10-13 22:33:30)开始的事务慢查询出现次数最多(每个 tikv 2000+ 次),出现时间段(22:33~23:57)跟监控基本一致,可以查一下三个 tidb 节点的 tidb_slow_query.log,附件中的 tidb 慢日志统计日志中未发现 coprocossor 相关请求的 SQL
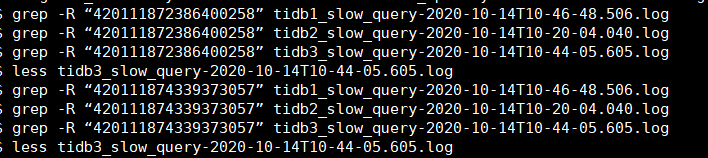
txn_start_ts=420111872386400258
txn_start_ts=420111874339373057
检查了下还是未发现异常的SQL,你提到22:33~23:57 2000+次慢查询与insert update的出现的次数差不多:
table_name(A,B,C,D,create_time,update_time)VALUES(…,now(),now()) on duplicate key update update_time = now(),D=VALUES(D)\G执行 grep 也没有找到相关 SQL 吗
grep -R “420111872386400258” “tidb_slow_query_.log"
grep -R “420111874339373057” "tidb_slow_query_.log”
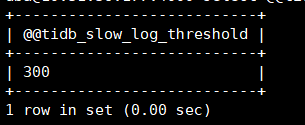
另外看下 slow query 阈值的设置
select @@tidb_slow_log_threshold;
这个 sql 到 tikv 的请求是 batchget 或 get,对应 tikv storage readpool cpu,coprocessor cpu 升高应该是其他的 sql 导致,3.0.12 有已知的某些情况下慢日志会遗漏记录的问题,可以跟业务方确认下是否有其他的查询请求;如果告警频繁出现,可以开启 general log ,记录全量的 SQL 到日志文件,但打开后对性能有一定的影响。
收到,谢谢~ 今晚我提早开下试试
不好意思,破案了…是tispark的SQL,后继有问题我再来咨询。
谢谢qizheng的回复!
![]()