不是混合部署
2 个赞
tidb-prod-TiKV-Details_2022-03-29T06_21_48.505Z.json (5.7 MB) tidb-prod-PD_2022-03-29T06_25_14.719Z.json (169.6 KB) tidb-prod-TiDB_2022-03-29T06_26_02.437Z.json (2.4 MB)
1 个赞
学习一下。
1 个赞
1、metric导出的数据没包含出问题的时间点
2、tikv实例内存是怎么配置的?block-cache 即 capacity默认大概是主机内存的45%
3、tikv这块的主要内存配置是capacity和write-buffer,这块是怎么配置的?
4、另外压测的时候,有没有进行大查询?
1 个赞
tidb-prod-TiKV-Details_2022-03-29T08_20_43.801Z.json (27.4 MB) tidb-prod-TiDB_2022-03-29T08_15_55.704Z.json (5.2 MB) tidb-prod-PD_2022-03-29T08_17_36.238Z.json (5.2 MB)
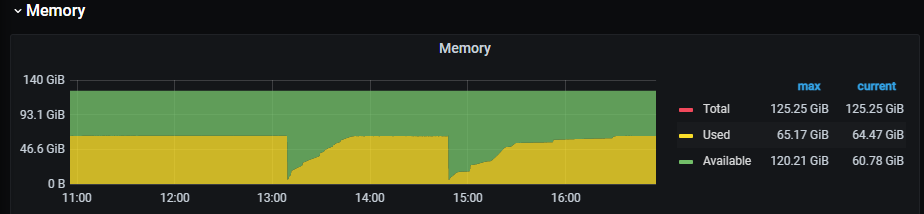
所有关于内存的参数都是默认值,压测的时候没有大查询,但是研发灌数据的时候会有大的统计,13点10分的时候oom了一次,14:47的时候store-1oom了
1 个赞
主要我不明白的是,oom之前内存应该是先升高,然后突然掉下来,但我现在这种情况使用内存一直都是总内存的一半,没有升高的现象,直接就掉下来了
1 个赞
大的统计,就是大查询啊,比如查询一个超大表,又下推到tikv节点,必然会占用很多内存的。
1 个赞
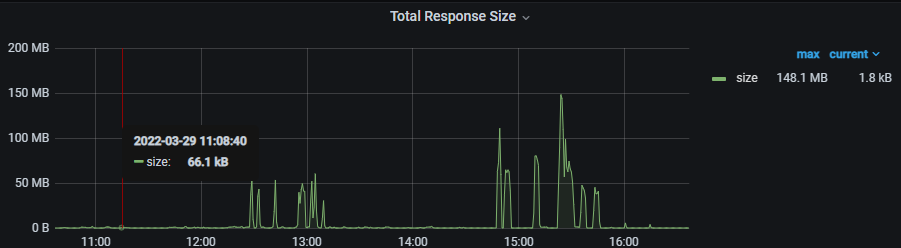
1、response size是请求返回的大小,和算子在tikv查询过滤没有关系
2、tikv是独占部署吗? 主机内存可否有监控指标?
1 个赞
tikv是单独部署的,除了tidb自带的监控指标外没有单独的监控
1 个赞
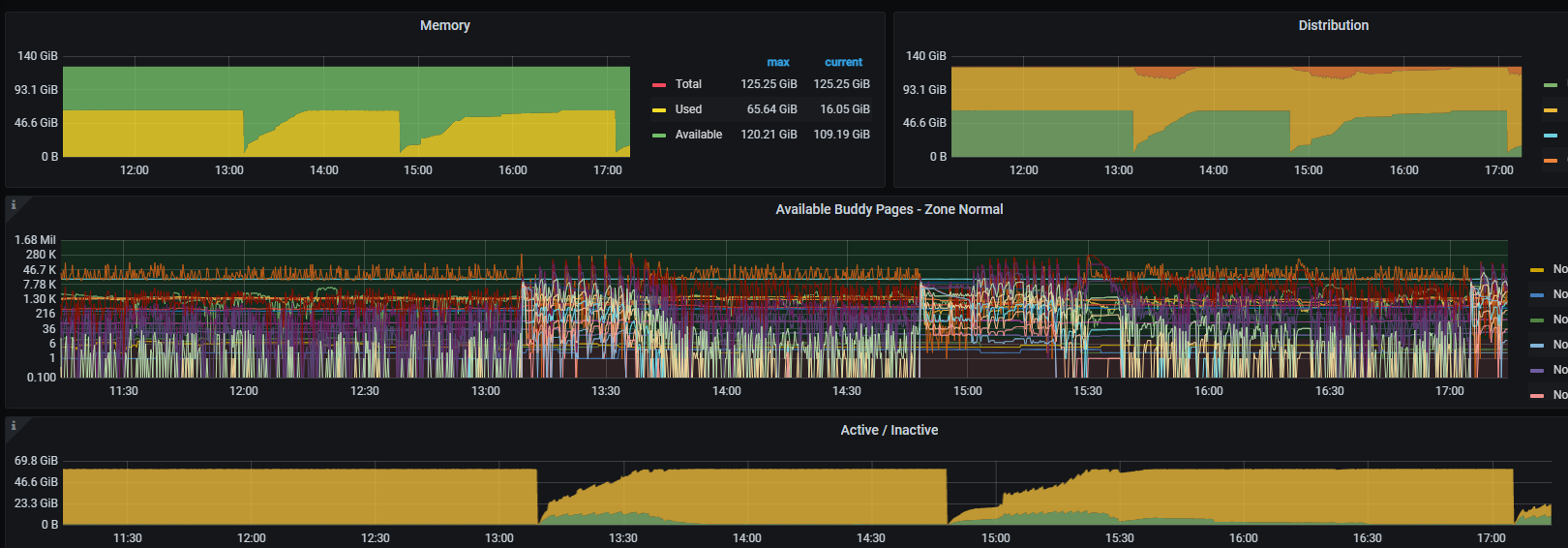
看你这指标,到目前为止今天发生了2次oom
1 个赞
对,第一次是3个kv同时oom,第二次只有这一台oom了,我想知道为什么,怎么处理
1 个赞
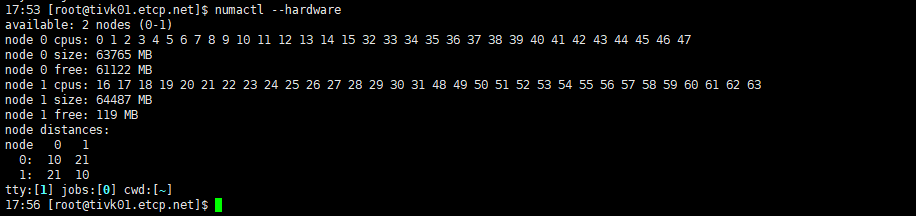
cat /proc/sys/vm/zone_reclaim_mode 看看
1 个赞

1)启用numa,然后内存回收只使用local node memory,这个是怀疑方向
2)numactl --hardware 看看
1 个赞