
这种是空region,不知道是不是触发了啥bug,你的集群开启了merge region了么,merge region的开启方法如下
pd-ctl config set max-merge-region-size 20
pd-ctl config set max-merge-region-keys 200000
pd-ctl config set merge-schedule-limit 8
config set enable-cross-table-merge true (跨表合并)
https://docs.pingcap.com/zh/tidb/v4.0/massive-regions-best-practices#方法五开启-region-merge
tikv_gc_life_time 我昨天调整到24小时,还是报错。之前是默认值10分钟
这几个值我设置过了
我问问产研大佬们,不知道是不是触发了什么bug,看着像空region引发的问题,之前也有个同样的问题不了了之
检查过下游 TIDB 集群状态吗?
- 集群是否是新创建的?
- TiKV 节点是否都是 up 且 normal 的?
- 有没有看看 BR 恢复前,TiKV 日志有没有异常报错 ?
在恢复集群使用 pd-ctl key 查询一下。个 range key 状态。
这个范围 [7480000000000001FF6B5F72800000003DFFDD14130000000000FA,7480000000000001FF6B5F72800000003FFF01A9FD0000000000FA) 使用 start key 做一下查询,然后输出反馈提供一下。start key ·[7480000000000001FF6B5F72800000003DFFDD14130000000000FA·
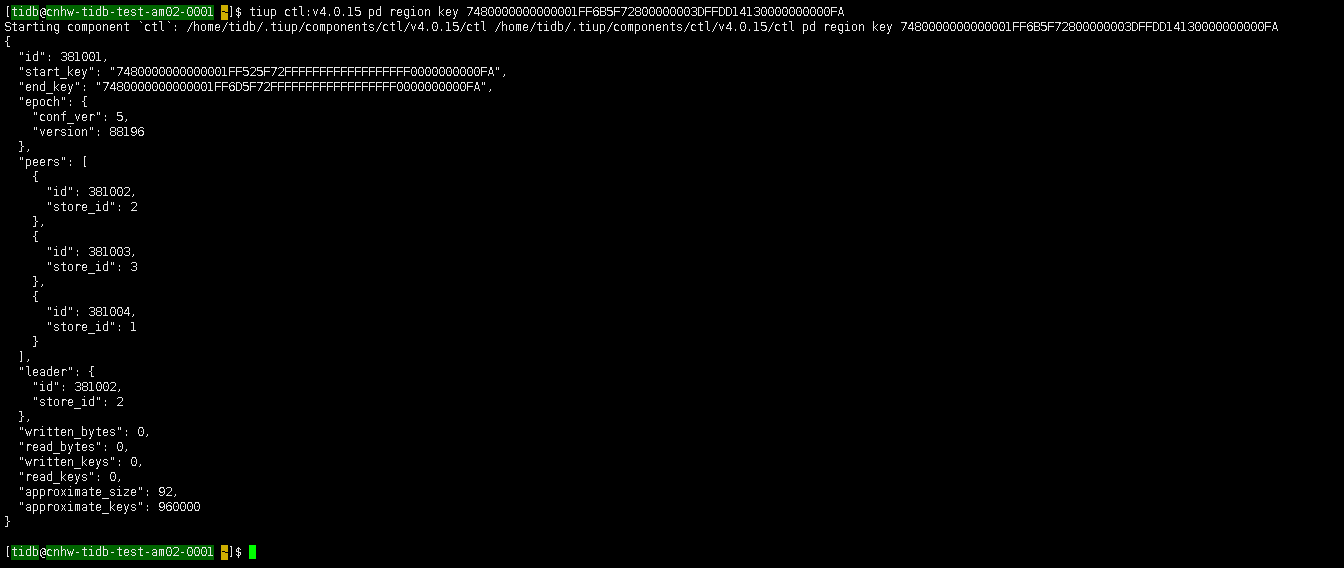
目前看起来是这个问题,https://github.com/pingcap/tidb/issues/33419,BR 在恢复的时候,对 scan region 返回空的重试逻辑存在 bug, 导致重试过短,这应该是不稳定导致的。
workaround 的话,可以尝试调低并发 --concurrency=32 或者限速,再试一次。
1 个赞
BR恢复时scan region 目的是啥?
scan region 是为了找到 region leader 所在的对应 tikv 节点,然后发送 download/ingest sst 请求到对应节点上
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。