为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
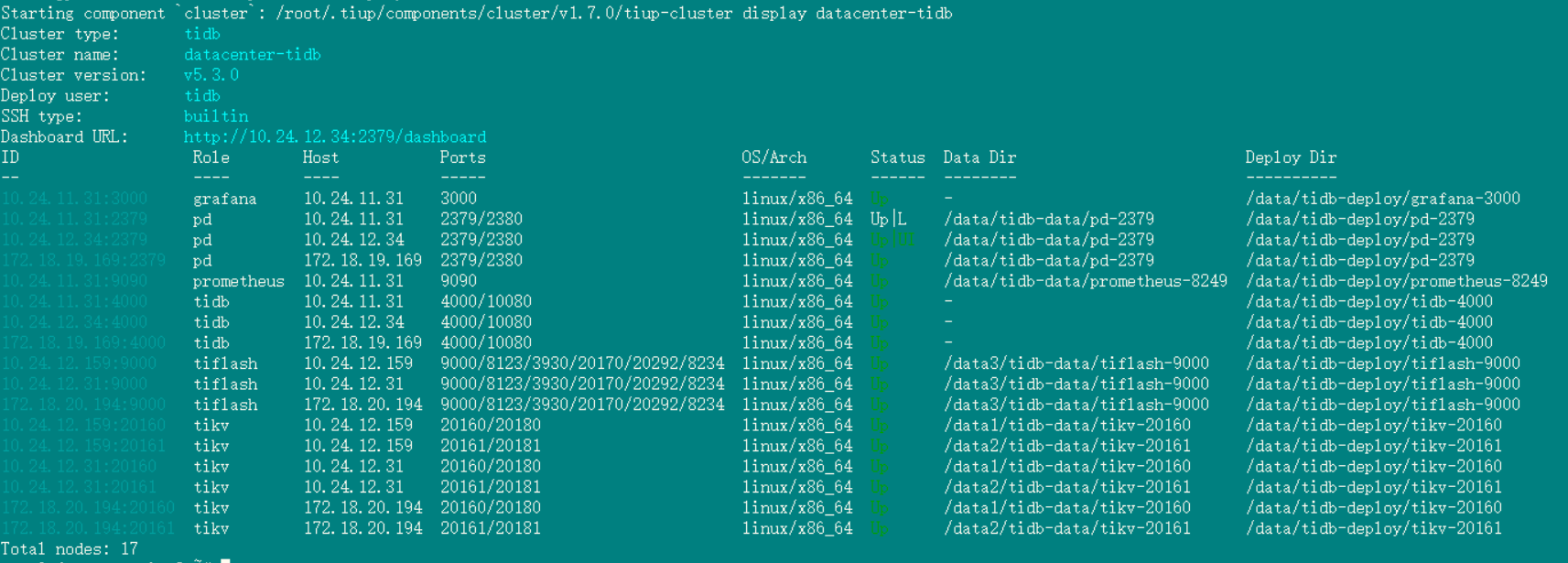
集群拓扑:pd和tidb两个角色是在3台ssd上各一个,2tidb+1tiflash在同一台ssd上(一共三台,每个服务都是独立的ssd盘)
【概述】 场景 + 问题概述
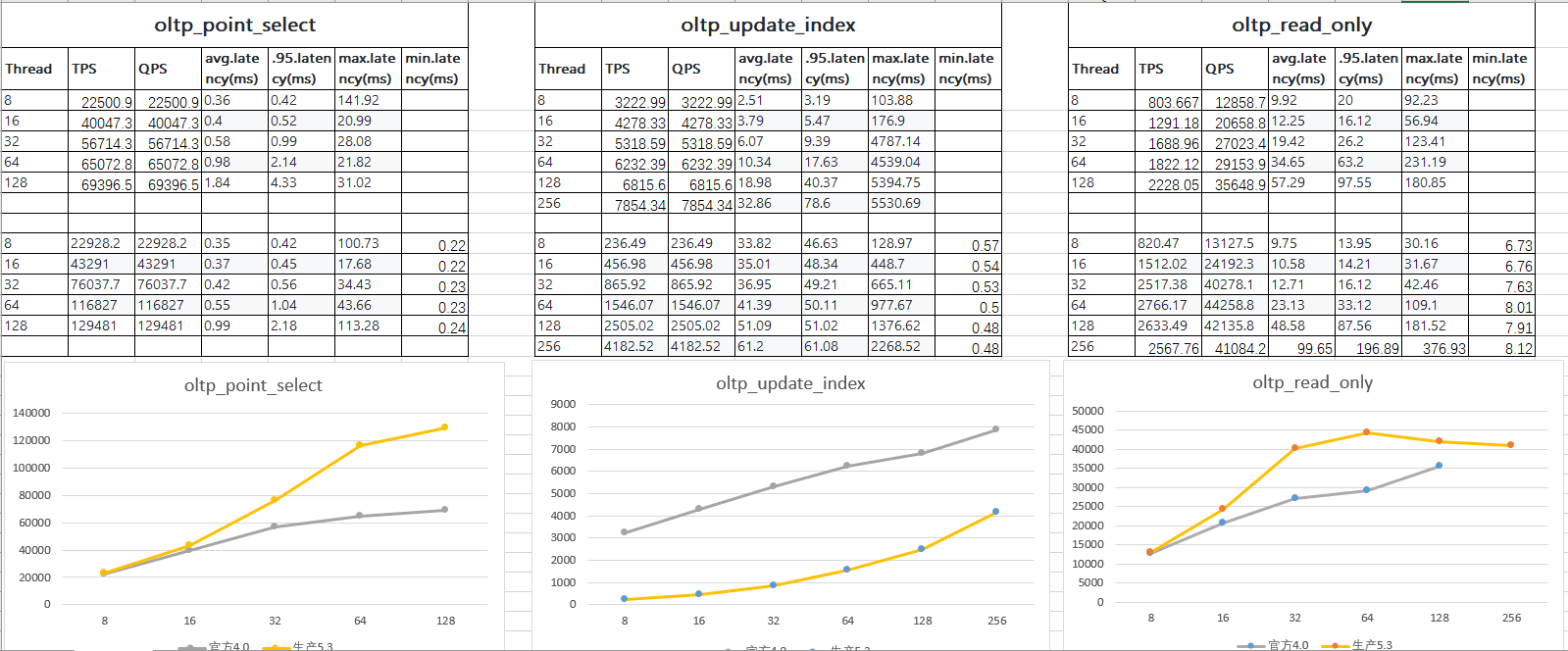
我用sysbench压测oltp_update_index这个的qps只有官方公布的十分之一,其他两个和官方的差不多,各位知道大概是什么原因不
【应用框架及开发适配业务逻辑】
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
5.3
【附件】 相关日志及监控(https://metricstool.pingcap.com/)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
h5n1
(H5n1)
2
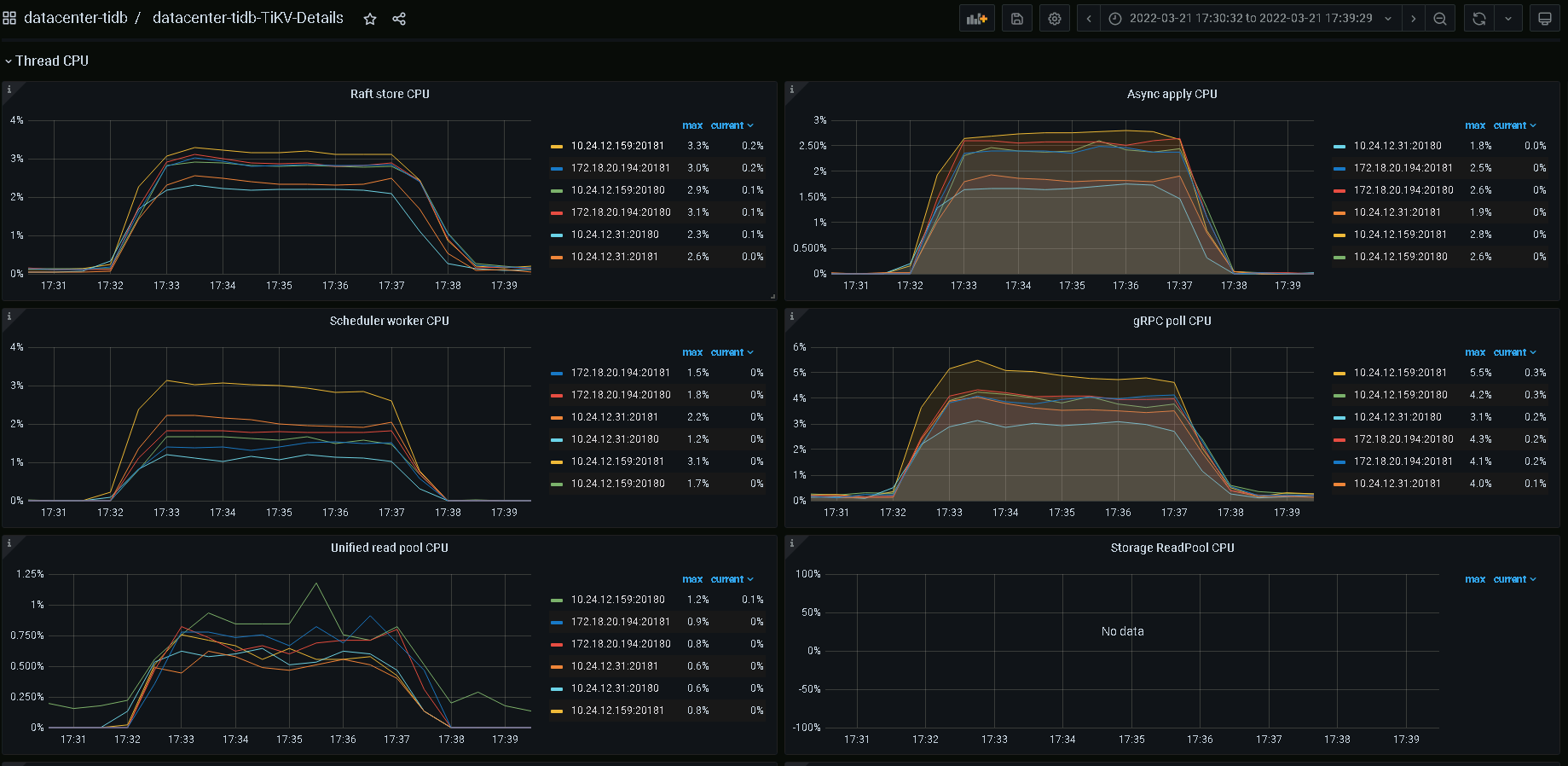
看下update index测试时候有没有热点,看tikv thread cpu
1 个赞
这是sysbench oltp_update_index --mysql-host=。。。。 --mysql-port=4000 --mysql-user=root --mysql-password=。。。。 --mysql-db=sbtest --db-driver=mysql --tables=32 --table-size=10000000 --report-interval=10 --threads=8 --time=300 run 的时候tikv的thread cpu
h5n1
(H5n1)
6
你用了几个tidb server, 直连的tidb server 还是走的负载均衡,tidb server CPU 利用率怎么样
1 个赞
h5n1
(H5n1)
8
官方的测试是3个tidb server,建议资源充足配置3个tidb server 前端加一个负载均衡, 混布的话可以设置numa_node绑核
1 个赞
官方那个数据是三个加的,但是我这个单个的只有官方的十分之一,还是感觉不太正常,我的tikv是两块ssd做的raid0,有影响吗
h5n1
(H5n1)
10
tiup cluster display 看下你的拓扑
这是oltp_update_index --threads=64的时候,tidb的负载,都很低
h5n1
(H5n1)
15
Tidb-Cluster-Node_exporter_2022-03-25T09_15_50.600Z.json (1.3 MB) datacenter-tidb-Overview_2022-03-25T09_14_43.668Z.json (1.3 MB) datacenter-tidb-PD_2022-03-25T09_13_43.656Z.json (3.4 MB) datacenter-tidb-TiDB_2022-03-25T09_12_00.037Z.json (2.5 MB) datacenter-tidb-TiKV-Details_2022-03-25T09_08_03.281Z.json (10.1 MB)
命令 sysbench oltp_update_index --mysql-host=。。。。 --mysql-port=4000 --mysql-user=root --mysql-password=。。。。 --mysql-db=sbtest --db-driver=mysql --tables=32 --table-size=10000000 --report-interval=10 --threads=64 --time=600 run
h5n1
(H5n1)
17
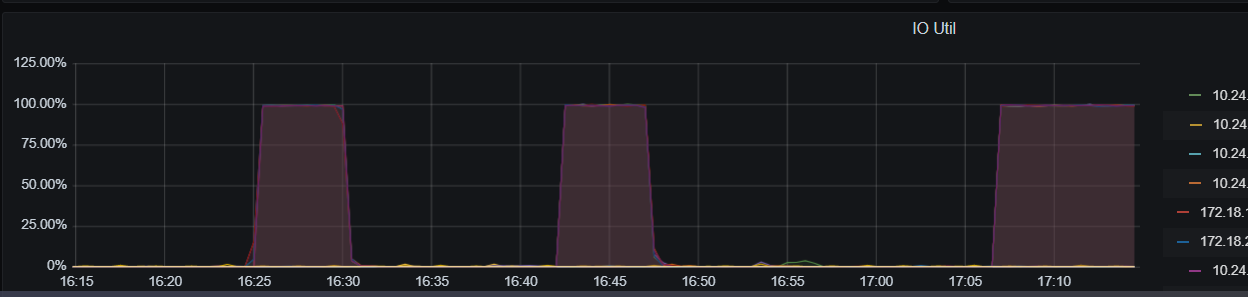
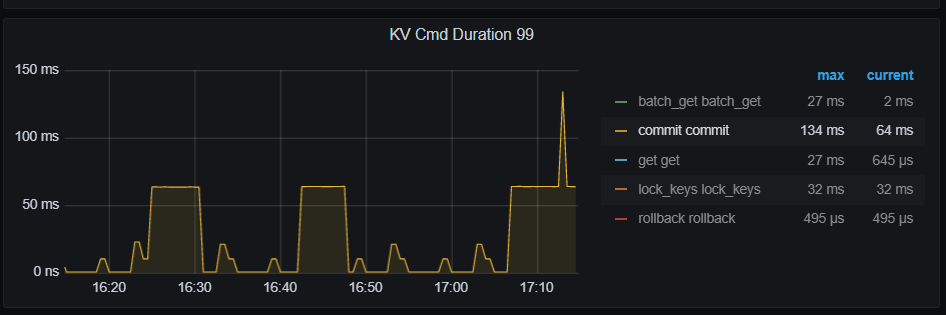
20.194上的磁盘IO满了,commit耗时长,我看这上面2个tikv,1个tiflash, tiflash有些数据吗?磁盘正常吗,select 时数据库可以从磁盘读出后在内存缓存,update必须写磁盘
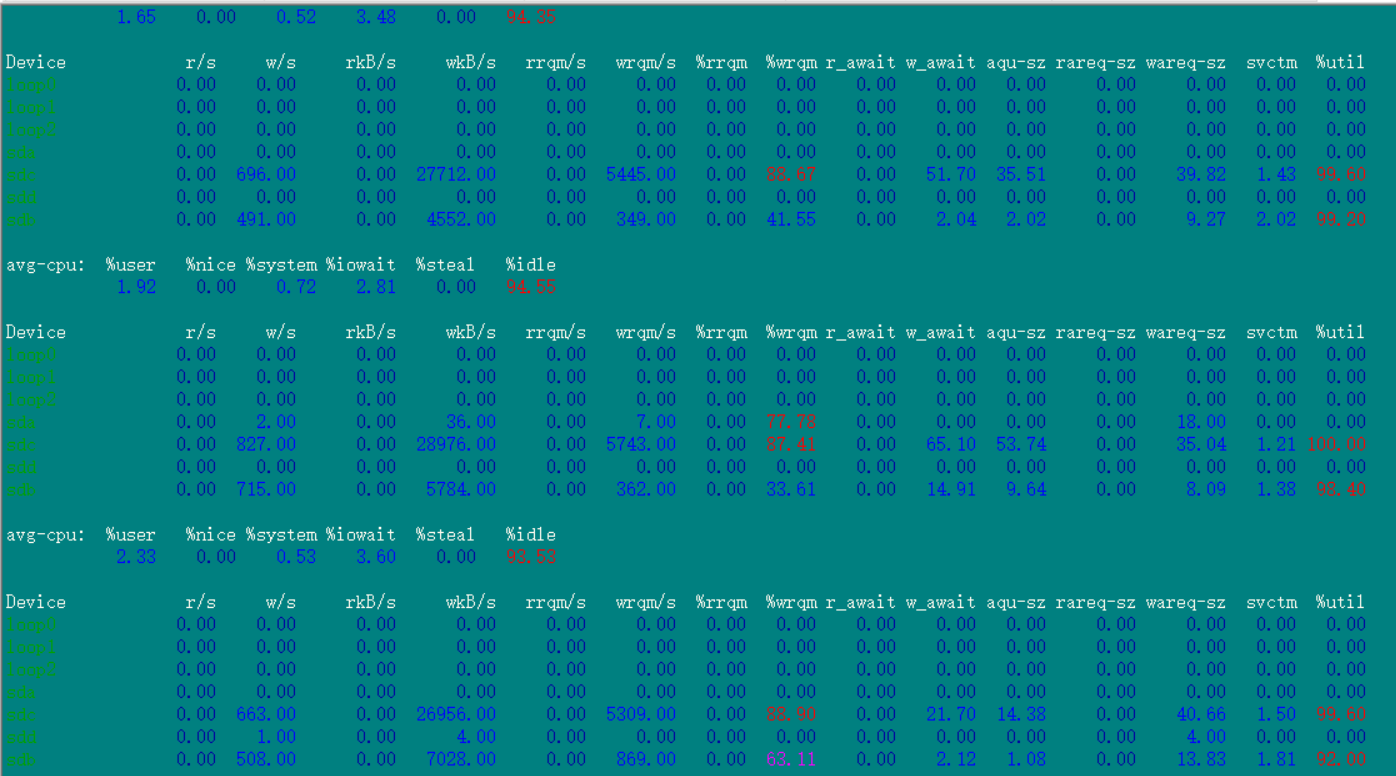
这是在跑sysbench时候iostat -x 1 10 命令的结果
这是在20.194上执行dd测试的时候iostat -x 1 10 命令的结果,看起来磁盘没有啥问题