实验环境
9节点tidb,9节点tikv,3节点pd,tidb版本v5.2.1
遇到的问题
-
宕机其中一个节点,请问pd会自动进行副本重建吗?会的话是在何时进行副本重建?
目前没有机器,没有办法做实验
-
删掉一个节点tikv的数据,请问pd能感知到副本数量变化,自动进行副本重建吗?会的话是在何时进行副本重建?吞吐有7s左右变成0,原因是?
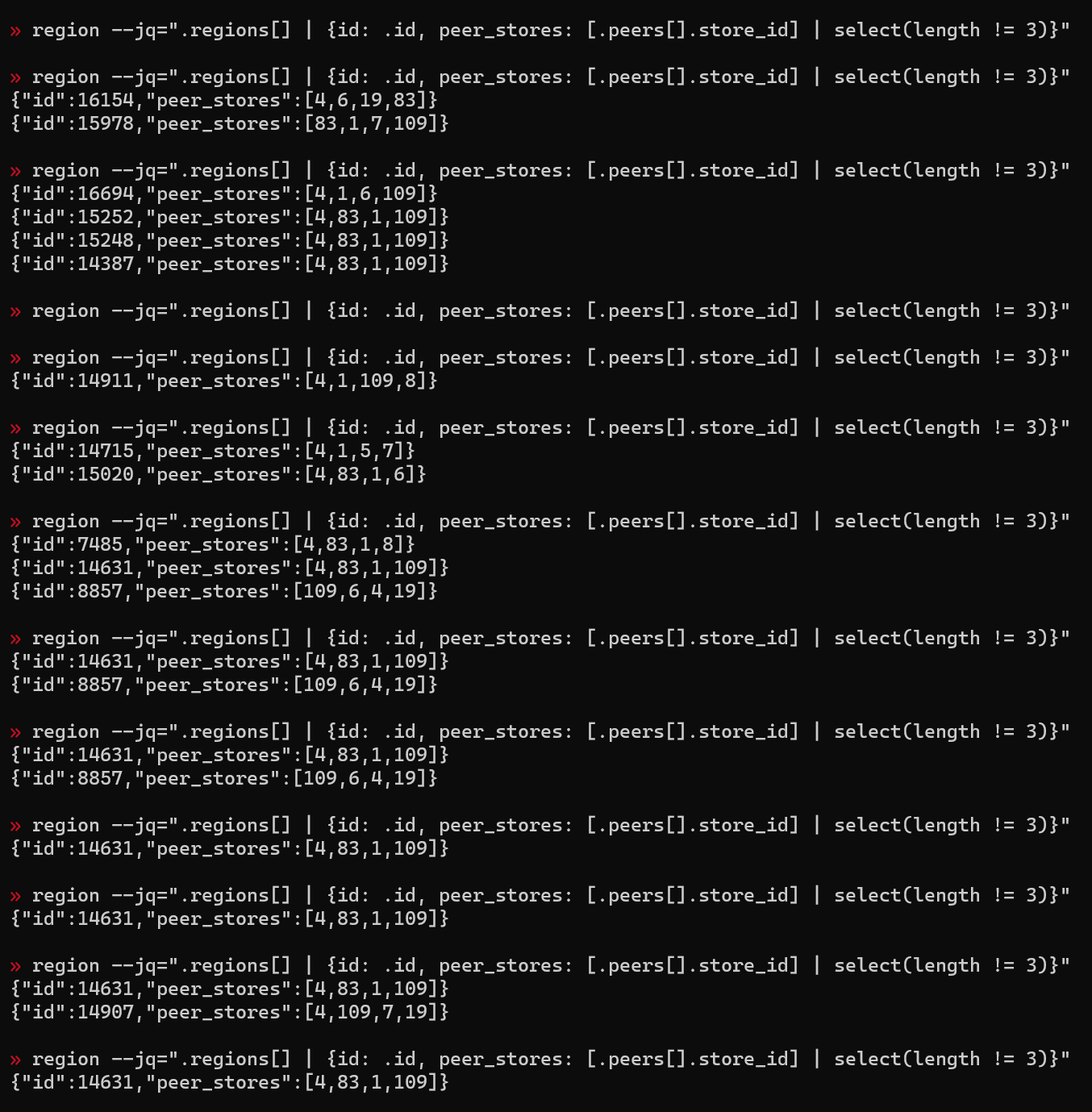
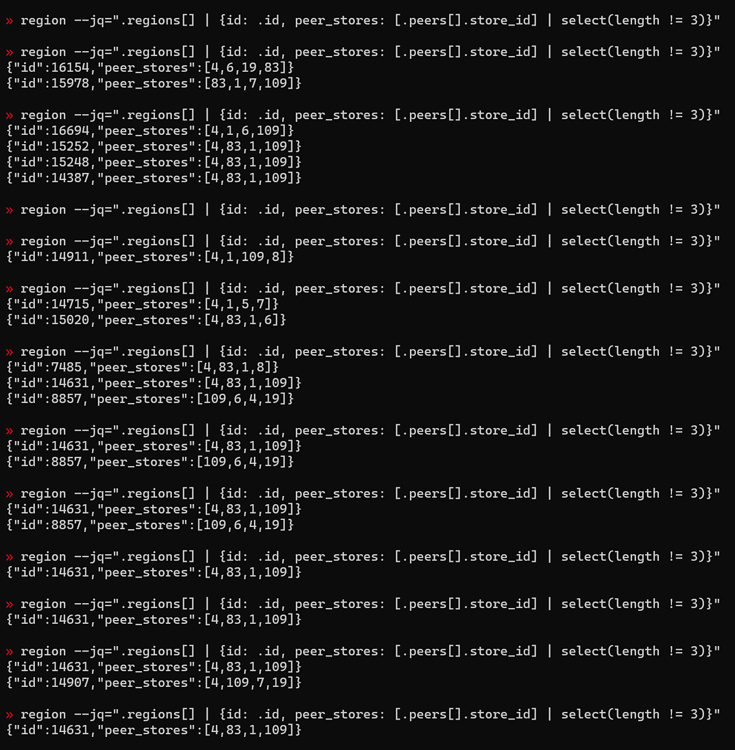
在跑benchmarksql过程中,删掉一个节点的tikv数据,吞吐有7s左右变成0(不知道是因为在选主还是在副本重建),在整个过程中间歇性地查询副本数不为3的副本,结果如图,没有看到副本数为2的情况。
h5n1
(H5n1)
2
tiup cluster display 拓扑贴下, 正常PD 使用raft 多数一致可用,一般奇数个节点,down1个不影响。tikv down后该节点上的region /leader会迁移到其他tikv,消耗网络IO等资源。数据默认3副本只允许宕1个tikv,2个tikv有问题了会出现部分数据不可用情况,要做多副本失败恢复
2 个赞
啦啦啦啦啦
3
TiKV Store 与集群失去连接的时间已经超过了 max-store-down-time 指定的时间,默认 30 分钟。超过该时间后,开始在存活的 Store 上补足各个 Region 的副本。
1 个赞
这是tiup cluster拓扑,请问为什么删掉一个节点tikv的数据,然后查询每个region的副本数,却看到不到副本数为2的region呢?
是通过其中一个pd节点的pd-ctl查询的官方文档,在删除一个tikv节点5分钟内多次查询,都没有看到2副本的region,具体的查询结果如下
h5n1
(H5n1)
8
补副本时可能是pending-peer状态,缺副本的是miss-peer,可以pd-ctl region check pending-peer/miss-peer看下
边城元元
(边城元元)
9
宕机一台,leader peer 选主,
超过了 max-store-down-time 指定的时间,在其他存活的 Store 上补足各个 缺失Region 的副本。
system
(system)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。