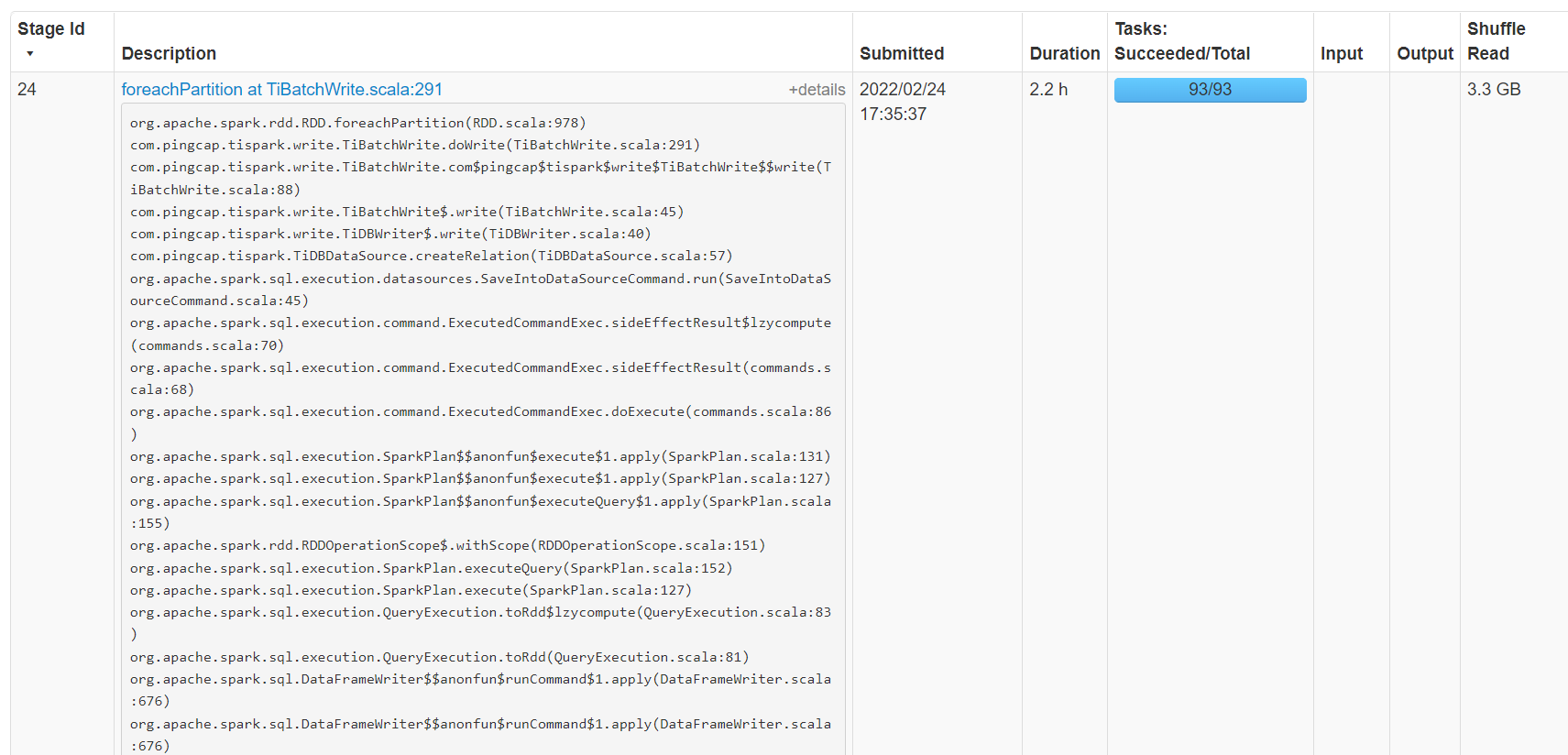
问题:tidb目标表已经存在5000多万条数据,现在要从hive表将4000多万的数据表合并到tidb目标表中,通过tispark里option replice=true选项实现,spark任务卡顿,一直无法完成。

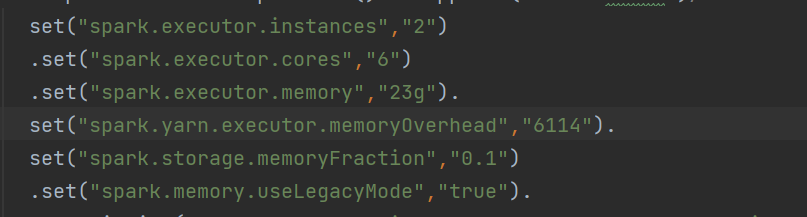
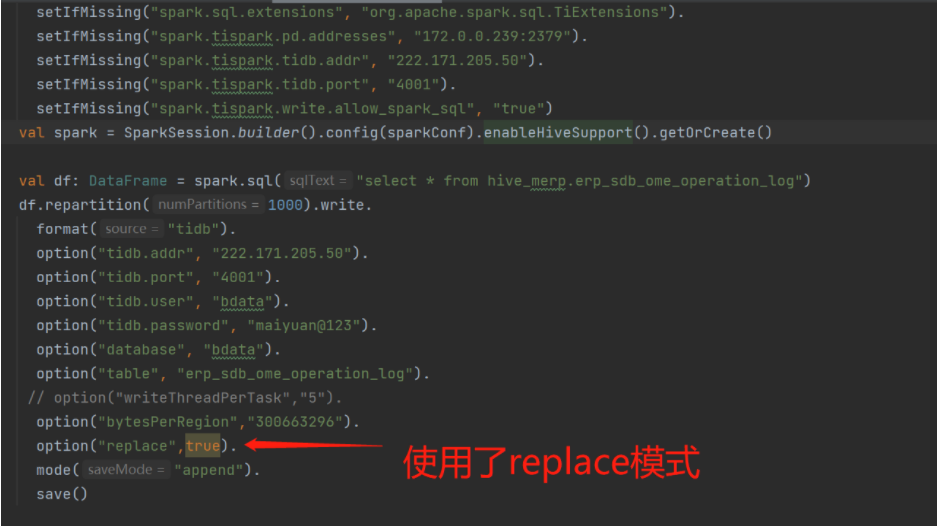
tispark代码:
写入的数据条数:43876213
表结构:
问题:tidb目标表已经存在5000多万条数据,现在要从hive表将4000多万的数据表合并到tidb目标表中,通过tispark里option replice=true选项实现,spark任务卡顿,一直无法完成。
表结构:
类似的情况可能的原因是gc过多或者shullfe有溢出到disk的情况,看一下有这两方面原因么?
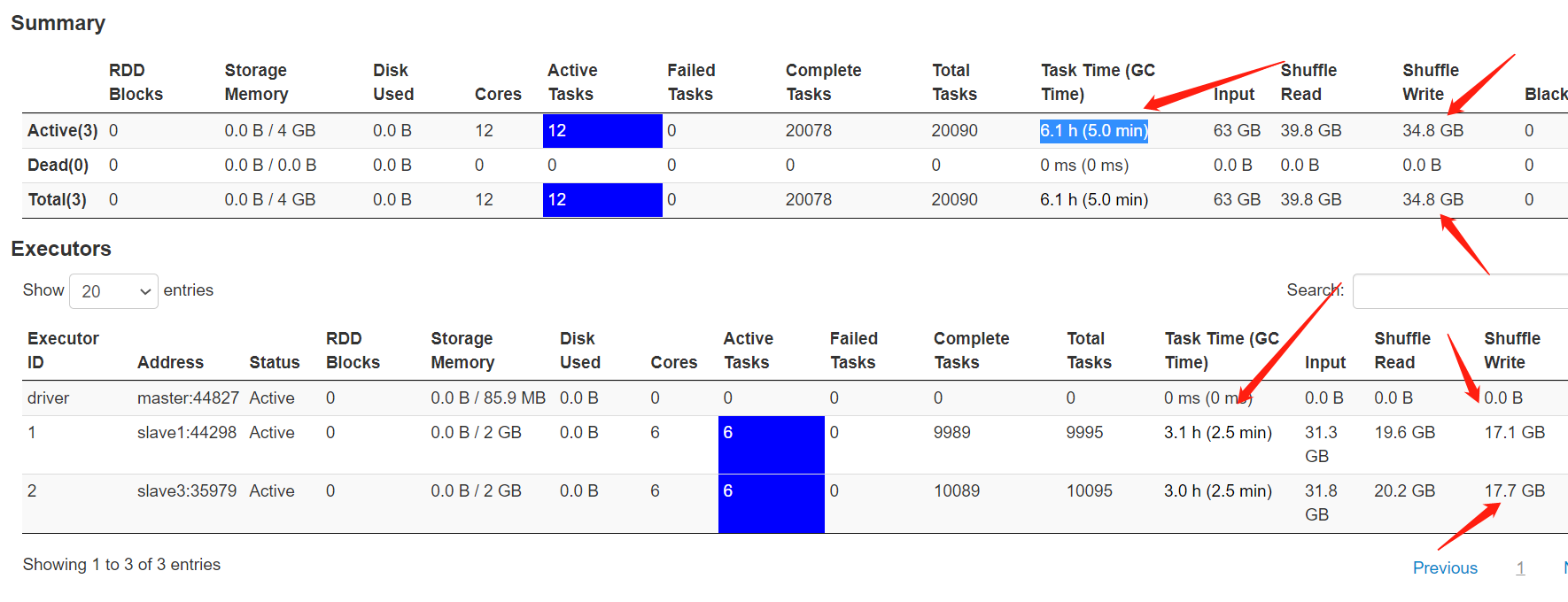
刚刚测了一次50w数据量的写入,共花了7.1分钟
时间跟环境也有很大关系,我这边测的最好的是tidb 8c16G tikv 8c16G 分别16个节点,普通SDD盘,2000万7分钟,50万数据repartition1000是不是有点多,你这个配置,按说200就够了,卡着的问题,有没有翻翻日志?有fail的task么?
我们tidb的节点配置低,节点不到5个,分区一开始用的就是200个,跑不动换成1000个也不行,有没有什么参数可以调优加快写入速度
1000分区写入的时候,tidb那边的cpu和io情况如何?是不是已经被打满了?目标被打满就是没有很好的办法优化,我目前遇到的情况,磁盘很差的情况下,很容易卡住。
spark版本是2.4.5
tispark版本是2.4.3-scala_2.11
你的目标tidb是悲观事务还是乐观事务?查了一下是两阶段提交的第二阶段,如果是悲观事务,从grafana查一下tikv的延迟等指标,看看tikv的运行情况吧
如果只有一个主机,spark写数据没啥优势啊,考虑lighting的local backend模式?
麻烦给一个lighting从hive导入tidb的例子
我们多数情况下,用csv做的过度,关于lighting支持csv的情况,参考:https://docs.pingcap.com/zh/tidb/stable/migrate-from-csv-using-tidb-lightning
另外,如果是在测试评估hive到tidb的数据导出方式,tidb这一端是否可以考虑加点机器?只有一台机器混部的情况,很容易就打满资源了。建议,一个pd,一个tidb,三个tikv,tikv最好配置ssd,在这个环境上跑TiSpark输出数据相对能多测一些数据。
好的,多谢
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。